 |
VOOZH | about |
|
VOOZH | about |
In SQL, UNION and UNION ALL are used to combine results from multiple SELECT statements. UNION returns only unique rows, whereas UNION ALL includes all rows, keeping duplicates.
Here is a detailed comparison of UNION and UNION ALL based on various features:
UNION | UNION ALL |
|---|---|
Removes duplicate rows, returning only unique records. | Includes all rows, even duplicates, from both result sets. |
Slower due to the need to eliminate duplicates. | Faster, as it doesn’t check for duplicates and simply combines the rows. |
The result set is smaller as duplicates are removed. | The result set is larger because duplicates are included. |
UNION removes duplicates internally (via sorting or hashing), but the final result order is not guaranteed unless ORDER BY is specified. | No sorting is done unless explicitly mentioned using ORDER BY |
Use when you need distinct results in the final output. | Use when retaining all rows, including duplicates, is important. |
Requires more processing power because of the duplicate elimination process. | More efficient as no additional computation is needed to remove duplicates. |
NULLs are treated as duplicates if they appear in both result sets. | NULLs are treated as regular values and included in the result, even if repeated. |
Works well for queries where distinct data is crucial, like in reporting. | Suitable for queries where duplicates are not problematic, such as transaction logs or detailed data analysis. |
Can be used in cases where you want to enforce uniqueness across different datasets. | Useful for combining large datasets where duplicate entries represent meaningful records, like in data aggregation. |
SQL engine performs a distinct operation internally to remove duplicates. | No distinct operation is performed; all rows, including exact duplicates, are included. |
Suitable when result accuracy is more important than performance. | Preferred when performance is the priority and duplicates don’t interfere with analysis or data quality. |
UNION is a SQL operation that combines the results of two or more SELECT queries into one result set. It removes duplicate rows, ensuring the final output contains only unique records. The operation also implicitly sorts the result set to eliminate duplicates.
Syntax
SELECT column1, column2, column3
FROM table1
UNION
SELECT column1, column2, column3
FROM table2;
In the above syntax:
Now let's understand this with the help of example
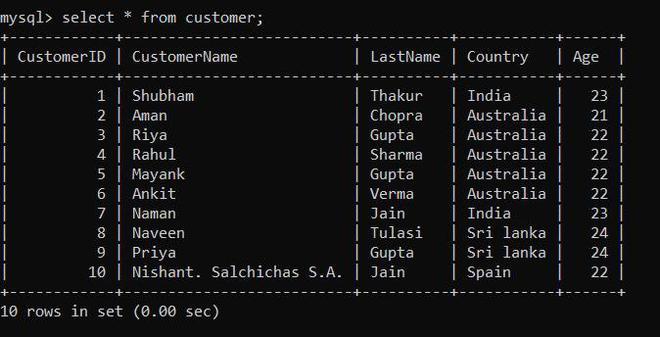
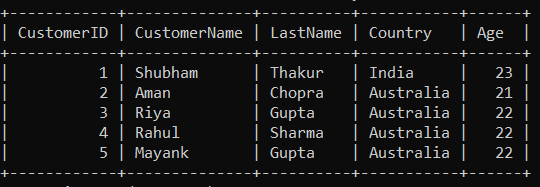
In this query, we will retrieve and combine rows with CustomerID between 1 and 5 from the "customer" table using the UNION operator.
SELECT ∗ FROM customer
WHERE CustomerID BETWEEN 1 AND 5
UNION
SELECT ∗ FROM customer
WHERE CustomerID BETWEEN 1 AND 5;
Output
In the above query:
SQL UNION ALL operator is also used to combine the set of one or more select statements as the result. The difference between UNION and UNION ALL is that in the UNION ALL operator there are duplicates in the result sets of SELECT statements whereas in the UNION operator, there are no duplicate values. The UNION ALL is faster than the UNION statement because in UNION ALL there is no additional step of eliminating duplicates.
Syntax
SELECT column1, column2, column3
FROM table1
UNION ALL
SELECT column1, column2, column3
FROM table2;
In the above syntax
Now let's understand this with the help of example:
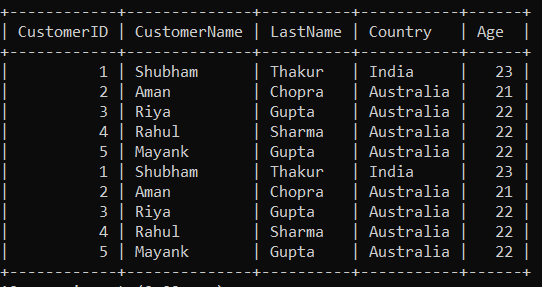
In this query, we will retrieves rows with CustomerID between 1 and 5 from the "customer" table and combines them with duplicate rows using the UNION ALL operator
SELECT ∗ FROM customer
WHERE CustomerID between 1 AND 5
UNION ALL
SELECT ∗ FROM customer
WHERE CustomerID BETWEEN 1 AND 5;
Output
In the above query:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}