 |
VOOZH | about |
|
VOOZH | about |
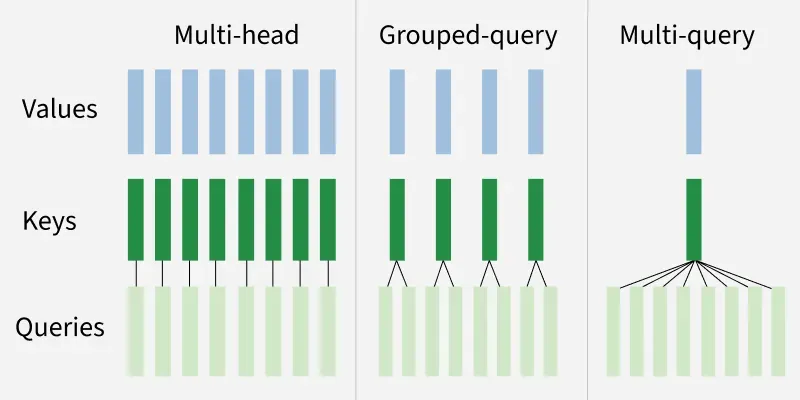
Grouped Query Attention (GQA) is an optimization technique for transformer models that balances computational efficiency and model performance. Inspired by the multi-head attention mechanism introduced in the seminal "Attention Is All You Need" paper, GQA addresses limitations of its predecessors: multi-head attention (MHA) and multi-query attention (MQA). Below is a detailed analysis of its architecture, benchmarks and tradeoffs.
GQA divides query heads into G groups, each sharing a single key and value head. This contrasts with:
The attention computation follows these steps:
1. Query-Key Dot Product: For each query group, compute dot products between queries and shared keys:
where is the key dimension (scaling prevents gradient vanishing).
2. Softmax Normalization: Apply softmax to generate attention weights.
3. Value Weighting: Multiply weights by shared value vectors to produce contextual outputs.
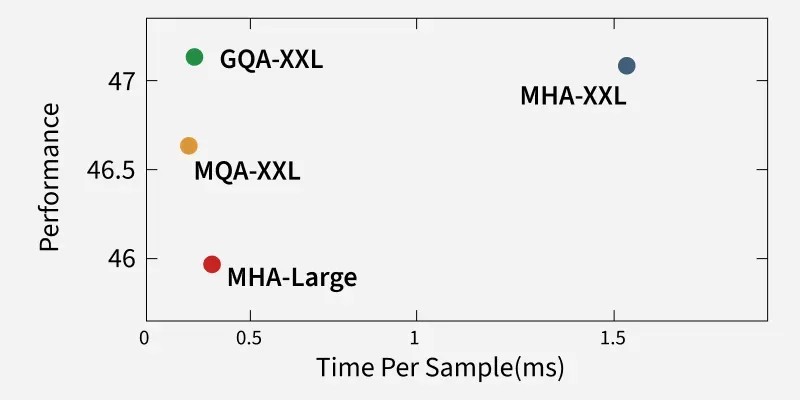
GQA interpolates between MHA and MQA, optimizing for:
Method | KV Heads | Inference Speed | Accuracy (vs. MHA) | Memory Use |
|---|---|---|---|---|
Multi-Head (MHA) | H | Baseline | 100% | Highest |
Multi-Query (MQA) | 1 | 1.5–2× faster | ↓ 5–15% | Lowest |
GQA (G=8) | H/8 | 1.3–1.4× faster | ↓ 1–3% | Medium |
1. Scalability for Long Contexts: GQA reduces memory complexity from to , enabling efficient processing of long sequences (e.g., 128K tokens) .
2. Hardware Optimization: When group count matches GPU count in tensor-parallel setups, GQA delivers near-free performance gains.
3. Flexible Configuration: Adjusting allows fine-tuning for specific tasks:
{kind=link}
{kind=link}
{kind=link}