 |
VOOZH | about |
|
VOOZH | about |
The multi-head attention mechanism is a key component of the Transformer architecture, introduced in the seminal paper "Attention Is All You Need" by Vaswani et al. in 2017. It plays a crucial role in enhancing the ability of models to focus on different parts of an input sequence simultaneously, making it particularly effective for tasks such as machine translation, text generation and more.
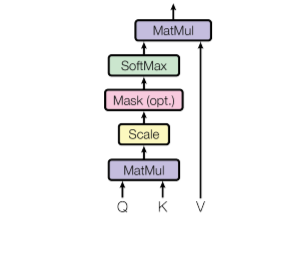
Before diving into multi-head attention, let’s first understand the standard self-attention mechanism, also known as scaled dot-product attention.
Given a set of input vectors, self-attention computes attention scores to determine how much focus each element in the sequence should have on the others. This is done using three key matrices:
The self-attention is computed as:
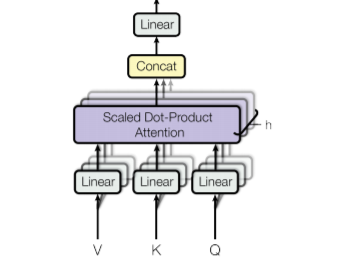
Multi-head attention extends self-attention by splitting the input into multiple heads, enabling the model to capture diverse relationships and patterns.
Instead of using a single set of matrices, the input embeddings are projected into multiple sets (heads), each with its own :
Mathematically, multi-head attention is expressed as:
where:
is a final weight matrix to project the concatenated output back into the model’s required dimensions.
Multi-head attention provides several advantages:
Multi-head attention is used in several places within a Transformer model:
1. Encoder Self-Attention: This allows the encoder to learn contextual relationships within the input sequence. Each word (or token) in the input attends to every other word, helping the model to understand dependencies regardless of their distance in the sequence.
2. Decoder Self-Attention: In the decoder, self-attention ensures that each position in the output sequence can attend only to previous positions (with a masking mechanism), preventing the decoder from “seeing” future tokens during training. This helps in generating sequences in an autoregressive manner while focusing on relevant parts of what has been generated so far.
3. Encoder-Decoder Attention: This layer lets the decoder attend over the encoder's output. It helps the decoder to align and focus on the appropriate input tokens when generating each output token, enabling sequence-to-sequence tasks like translation.
Importing all necessary libraries for tensor manipulations and neural network building.
This is the core of self-attention:
Every step mimics the original Transformer:
Output:
Notebook link : Multi Head Self Attention
Multi-head attention is widely used in various domains:
1. Natural Language Processing
2. Computer Vision: Vision Transformers (ViTs) for image recognition
3. Speech Processing: Speech-to-text models (e.g., Whisper by OpenAI)
The multi-head attention mechanism is one of the most powerful innovations in deep learning. By attending to multiple aspects of the input sequence in parallel, it enables better representation learning, enhanced contextual understanding and improved performance across NLP, vision and speech tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}