 |
VOOZH | about |
|
VOOZH | about |
In machine learning, optimizers and loss functions are two fundamental components that help improve a model’s performance.
The optimizer’s role is to find the best combination of weights and biases that leads to the most accurate predictions.
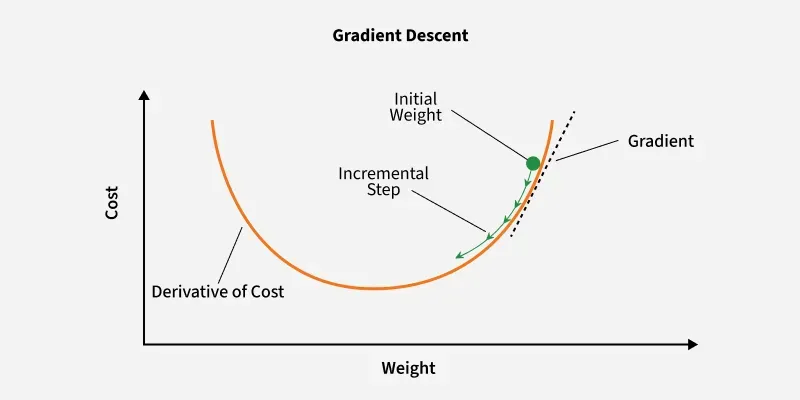
Gradient Descent is a popular optimization method for training machine learning models. It works by iteratively adjusting the model parameters in the direction that minimizes the loss function.
Formula :
where:
This variant ensures that the step size is large enough to effectively reduce the objective function, using a line search that satisfies the Armijo condition.
Condition:
Where:
Incorporates both first and second derivatives (Hessian matrix) to determine a more optimal step size for the update.
Condition:
Where:
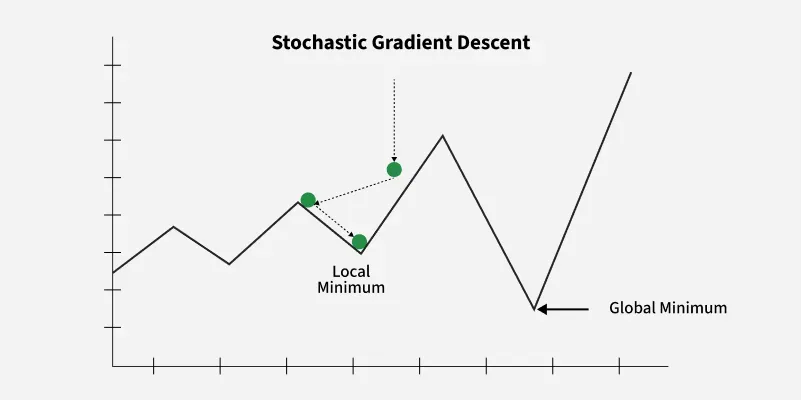
Stochastic Gradient Descent (SGD) updates the model parameters after each training example, making it more efficient for large datasets compared to traditional Gradient Descent, which uses the entire dataset for each update.
Steps:
Advantages: Requires less memory and may find new minima.
Disadvantages: Noisier, requiring more iterations to converge.
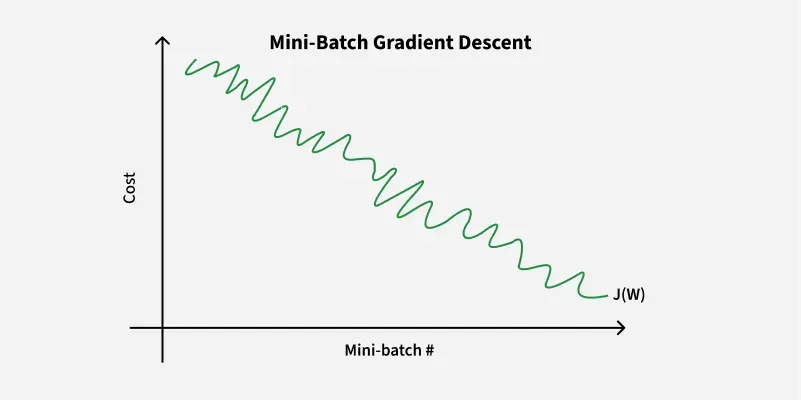
Mini-batch gradient descent consists of a predetermined number of training examples, smaller than the full dataset. This approach combines the advantages of the previously mentioned variants.
In one epoch, following the creation of fixed-size mini-batches, we execute the following steps:
Advantages: Requires medium amount of memory and less time required to converge when compared to SGD
Disadvantage: May get stuck at local minima
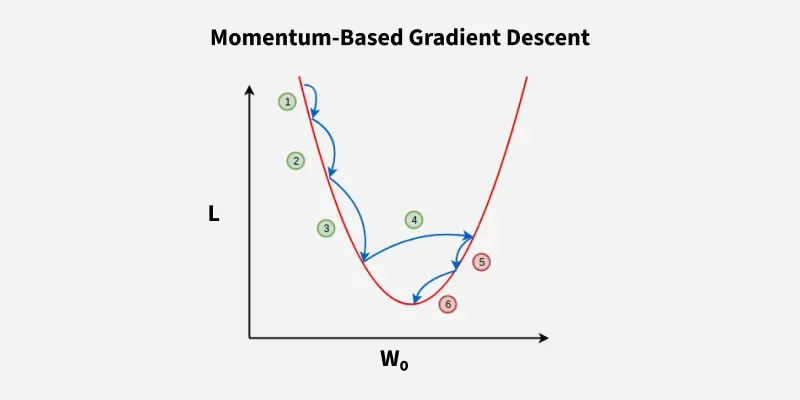
Momentum helps accelerate convergence by smoothing out the noisy gradients of SGD, thus reducing fluctuations and improving the speed of convergence.
Where:
Then, the model parameters are updated using:
Advantages: Mitigates oscillations, reduces variance and faster convergence.
Disadvantages: Requires tuning the momentum coefficient .
AdaGrad adapts the learning rate for each parameter based on the historical gradient information. The learning rate decreases over time, making AdaGrad effective for sparse features.
Where:
Advantages: Adapts the learning rate, improving training efficiency.
Disadvantages: Learning rate decays too quickly, causing slow convergence.
RMSProp improves upon AdaGrad by introducing a decay factor to prevent the learning rate from decreasing too rapidly.
Where:
Advantages: Prevents excessive decay of learning rates.
Disadvantages: Computationally expensive due to the additional parameter.
Adam combines the advantages of Momentum and RMSProp. It uses both the first moment (mean) and second moment (variance) of gradients to adapt the learning rate for each parameter.
Where:
Advantages: Fast convergence.
Disadvantages: Requires significant memory due to the need to store first and second moment estimates.
| Optimizer | Advantages | Disadvantages |
|---|---|---|
| SGD | Simple, easy to implement | Slow convergence, requires tuning |
| Mini-Batch SGD | Faster than SGD | Computationally expensive, stuck in local minima |
| SGD with Momentum | Faster convergence, reduces noise | Requires careful tuning of β |
| AdaGrad | Adaptive learning rates | Decays too fast, slow convergence |
| RMSProp | Prevents fast decay of learning rates | Computationally expensive |
| Adam | Fast, combines momentum and RMSProp | Memory-intensive, computationally expensive |
Each optimizer has its own strengths and weaknesses. The choice of optimizer depends on the specific problem, dataset characteristics and the computational resources available. Adam is often the default choice due to its robust performance, but each situation may call for a different optimizer to achieve optimal results.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}