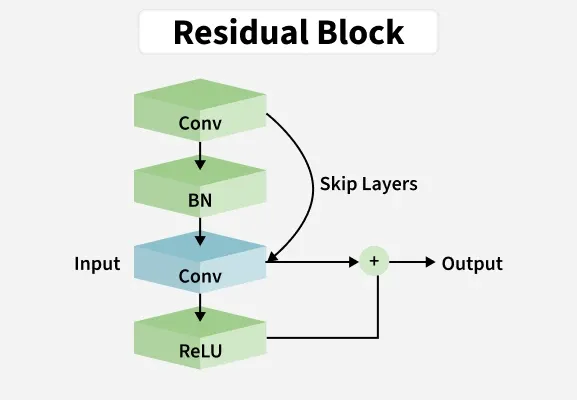
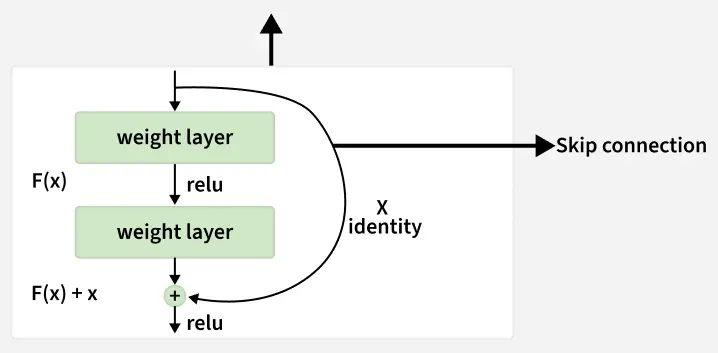
Residual Networks (ResNet) is a deep learning architecture designed to enable efficient training of very deep neural networks. It introduces skip (shortcut) connections, which allow the model to learn residual mappings instead of direct transformations.
Helps prevent vanishing gradient problems in very deep models
Allows information to flow directly across layers using skip connections
Enables building networks with hundreds or even thousands of layers
Deep Neural Networks are powerful models, but training them becomes difficult as network depth increases. Two major issues are:
1. Vanishing/Exploding Gradient Problem: As the number of layers increases, gradients can become extremely small (vanishing) or very large (exploding) during backpropagation, making training unstable.
2. Degradation Problem: Increasing network depth does not always improve performance and can even degrade it.
Performance Plateau: Training error stops decreasing after a certain depth
Accuracy Degradation: Validation error increases, leading to poor generalization
Key Features
Residual Connections: Enable very deep networks by allowing gradients to flow through identity shortcuts, reducing the vanishing gradient problem.
Identity Mapping: Simplifies training by learning residual functions instead of full mappings.
Depth: Supports extremely deep architectures for improved image recognition performance.
Fewer Parameters: Achieves high accuracy with fewer parameters hence improving computational efficiency.
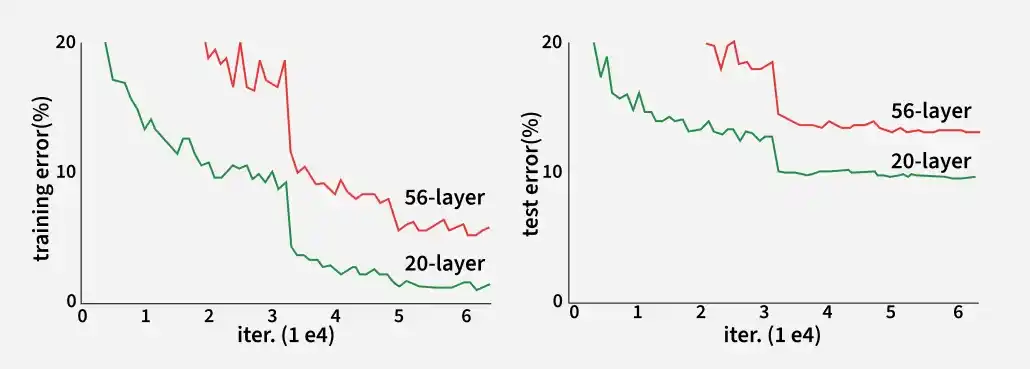
The following graph compares training and test errors of 20-layer and 56-layer networks, highlighting the limitations of deeper networks without residual connections.
Training error: The 56-layer network learns slowly and shows fluctuations, while the 20-layer network converges more smoothly
Test error: The deeper network has higher error (degradation problem), whereas the shallower network generalizes better
👁 resnet-1 Comparison of 20-layer vs 56-layer architecture
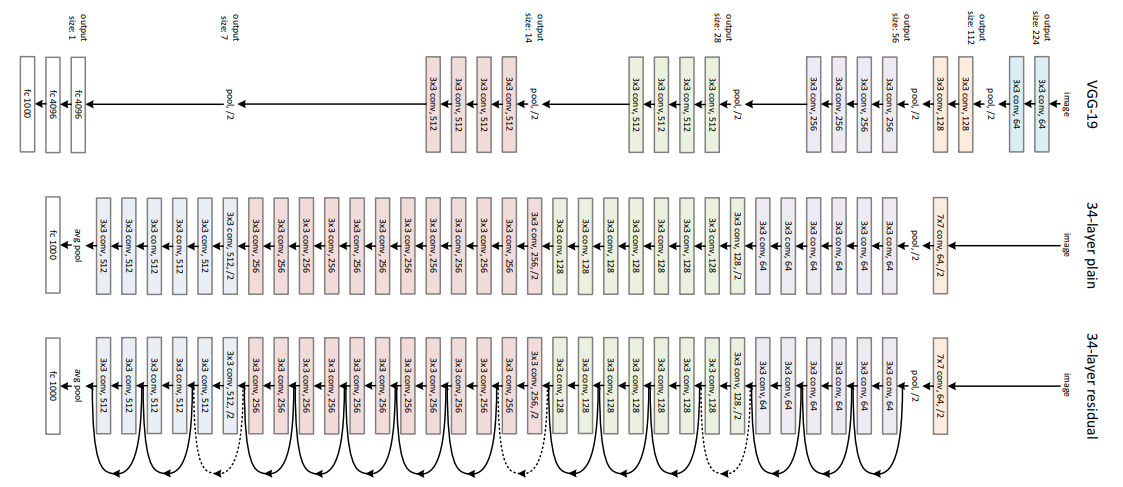
ResNet-34
ResNet-34 is a deep residual network built on a 34-layer plain network inspired by VGG-19, with shortcut connections forming 16 residual blocks. The architecture is organized into stages as follows:
First stage: 3 residual blocks, each with 2 convolution layers of 64 filters and identity skip connections
Second stage: 4 residual blocks, each with 2 convolution layers of 128 filters; uses 1×1 projection or padding for dimension matching
Third stage: 6 residual blocks, each with 2 convolution layers of 256 filters
Fourth stage: 3 residual blocks, each with 2 convolution layers of 512 filters
Output layer: Feature maps are passed through Global Average Pooling followed by a fully connected layer with softmax for classification
3. Handling Dimension Mismatch: When input and output dimensions differ
Zero Padding: Adds extra zeros to the input to match output dimensions
Linear Projection: Uses a learnable 1x1 convolution to match input and output dimensions for the skip connection.
4. Stacking Residual Blocks : Multiple residual blocks can be stacked to create deep architectures. This allows networks to go very deep without suffering from degradation.
5. Global Average Pooling (GAP): Before the final fully connected layer ResNet uses GAP
Converts each feature map to a single value by averaging
Reduces parameters less overfitting
Produces compact feature representation
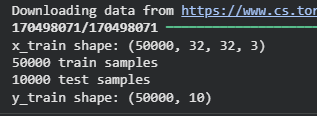
Implementation
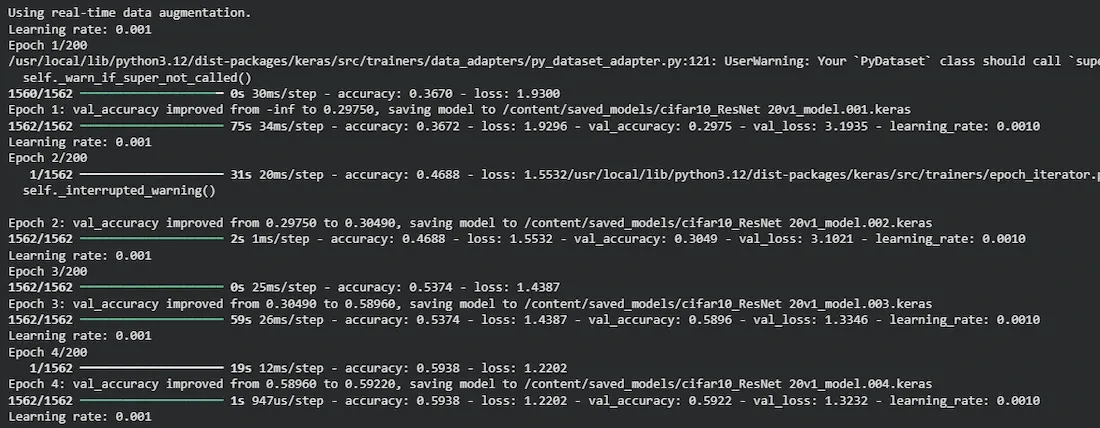
We will implement ResNet (v1 and v2) for CIFAR-10 and cover data preprocessing, model creation, training and plotting graphs step by step.
On the ImageNet dataset, a 152-layer ResNet, much deeper than VGG-19, achieved high accuracy with fewer parameters. An ensemble of ResNet models reached around 3.7% top-5 error. On the COCO dataset, ResNet showed a 28% relative improvement in object detection performance.
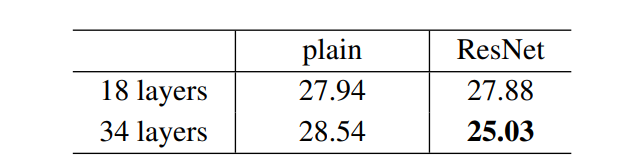
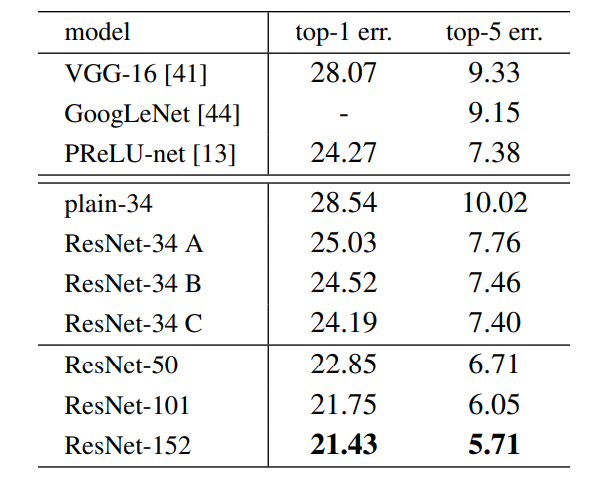
The results show that shortcut connections effectively address the problems caused by increasing network depth as increasing layers from 18 to 34 leads to a decrease in error rate on the ImageNet validation set unlike plain networks.
👁 Image top-1 and top-5 Error rate on ImageNet Validation Set.
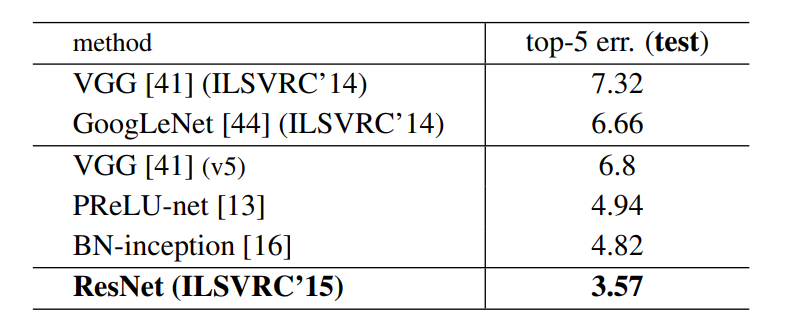
Below are the results on ImageNet Test Set. The 3.57% top-5 error rate of ResNet was the lowest and thus ResNet architecture came first in ImageNet classification challenge in 2015.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}