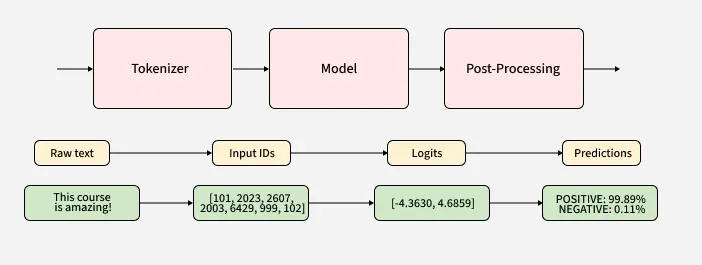
The Hugging Face pipeline is an easy-to-use tool that helps people work with advanced transformer models for tasks like language translation, sentiment analysis, or text generation. It takes care of the complicated steps behind the scenes like breaking up the text into tokens, loading the right model, and formatting the results properly. This way, users can focus on what they want to do, without worrying about the technical details. Using powerful AI models becomes much easier and more accessible for everyone.
ner_pipe = pipeline("ner"): Sets up an NER model ready to identify named entities like organizations, locations, or monetary values.
result = ner_pipe("Apple is looking at buying U.K. startup for $1 billion"): Feeds the sentence to the NER model.
print(result): Shows the identified entities (e.g., "Apple" as an organization, "U.K." as a location, "$1 billion" as money) along with their types and positions in the sentence.
Use Cases: Information extraction, document tagging, compliance, news analytics.
2. Translation
translation_pipe = pipeline("translation_en_to_fr"): Sets up a pre-trained model for English-to-French translation.
result = translation_pipe("Hugging Face is creating a tool that democratizes AI."): Translates the given English sentence.
Output
[{'translation_text': "Hugging Face crée un outil qui démocratise l'IA."}]
Use Cases: Multilingual support, content localization, cross-border communication.
3. Sentiment Analysis
sentiment_pipe = pipeline("sentiment-analysis"): Sets up a model of sentiment analysis to determine if text expresses positive, negative, or neutral sentiment.
result = sentiment_pipe("I love using Hugging Face models!"): Analyzes the sentiment of the input sentence.
Output
[{'label': 'POSITIVE', 'score': 0.9998}]
Use Cases: Customer feedback, social media monitoring, brand analysis.
4. Fill-Mask (Masked Language Modeling)
fill_mask_pipe = pipeline("fill-mask"): Sets up a model to fill in a "masked" (missing) word.
result = fill_mask_pipe("Hugging Face is creating a <mask> that democratizes AI."): Provides the sentence with a <mask> token.
print(result): Shows the most probable words that fit in the masked position, along with their scores in masked language modelling.
Output
[{'sequence': 'Hugging Face is creating a tool that democratizes AI.', 'score': ...}, ...]
Use Cases: Text autocompletion, grammar correction, language understanding.

{kind=link}
{kind=link}
{kind=link}