Association rules are a fundamental concept used to find relationships, correlations or patterns within large sets of data items. They describe how often itemsets occur together in transactions and express implications of the form:
Where and are disjoint sets of items. This rule suggests that when items in appear, items in tend to appear as well. Association rules originated from market basket analysis and help retailers and analysts understand customer behavior by discovering item associations in transaction data. For example, a rule stating
Indicates that customers who buy bread and butter also tend to buy milk.
Key Components
Antecedent (X): The "if" part representing one or more items found in transactions.
Consequent (Y): The "then" part, representing the items likely to be purchased when antecedent items appear.
Rules are evaluated based on metrics that quantify their strength and usefulness:
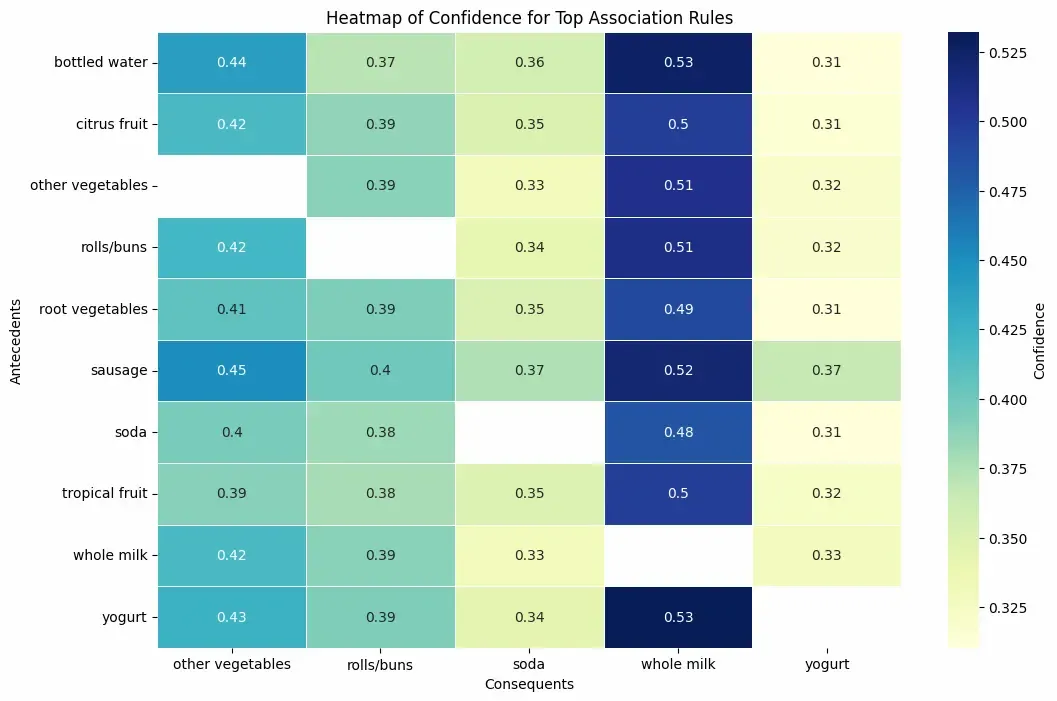
Rule Evaluation Metrics
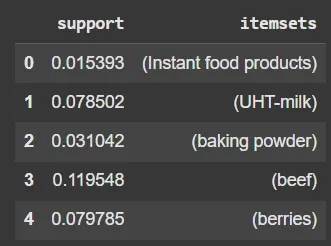
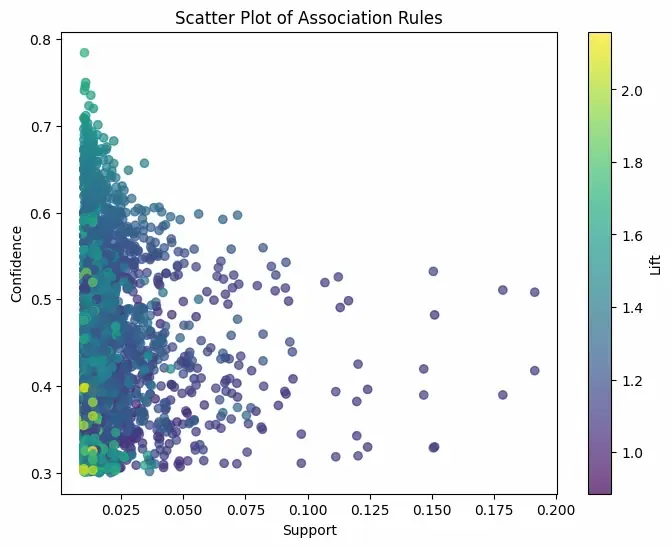
1. Support: Fraction of transactions containing the itemsets in both X and Y.
Support measures how frequently the combination appears in the data.
2. Confidence: Probability that transactions with X also include Y.
Confidence measures the reliability of the inference.
3. Lift: The ratio of observed support to that expected if X and Y were independent.
Lift > 1 implies a positive association — items occur together more than expected.
Lift = 1 implies independence.
Lift < 1 implies a negative association.
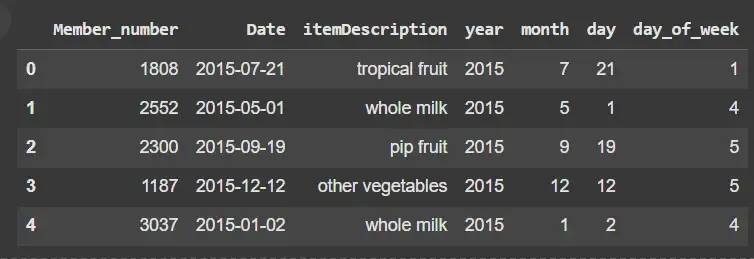
Example Transaction Data
Transaction ID
Items
1
Bread, Milk
2
Bread, Diaper, Beer, Eggs
3
Milk, Diaper, Beer, Coke
4
Bread, Milk, Diaper, Beer
5
Bread, Milk, Diaper, Coke
Considering the rule:
Calculations:
Support =
Confidence =
Lift = (positive association)
Implementation
Let's see the working,
Step 1: Install and Import Libraries
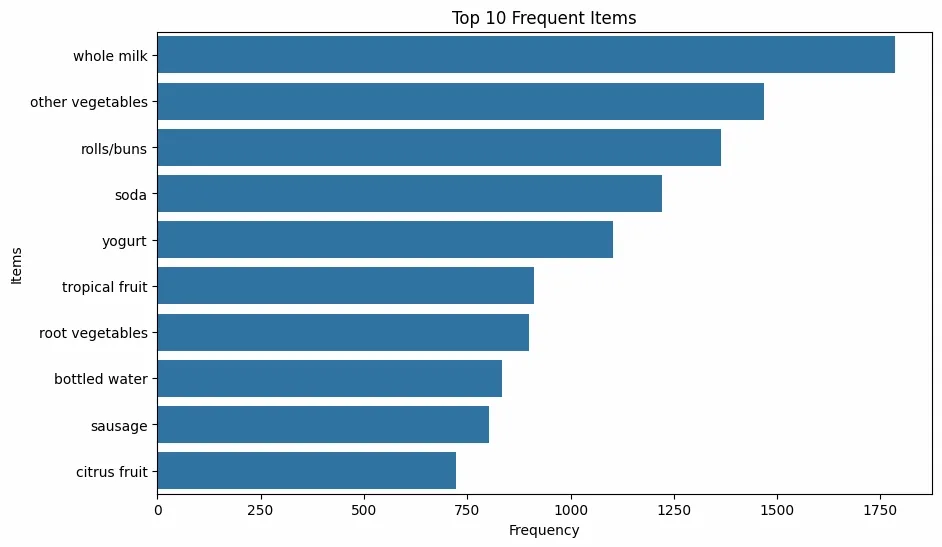
We will install and import all the required libraries such as pandas, mixtend, matplotlib, networkx.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}