 |
VOOZH | about |
|
VOOZH | about |
Spring Data JPA interview questions are mainly asked to test your understanding of database operations using JPA + Hibernate in Spring Boot. These questions focus on entities, repositories, query methods, JPQL, pagination, sorting, transactions, relationships, and performance best practices.
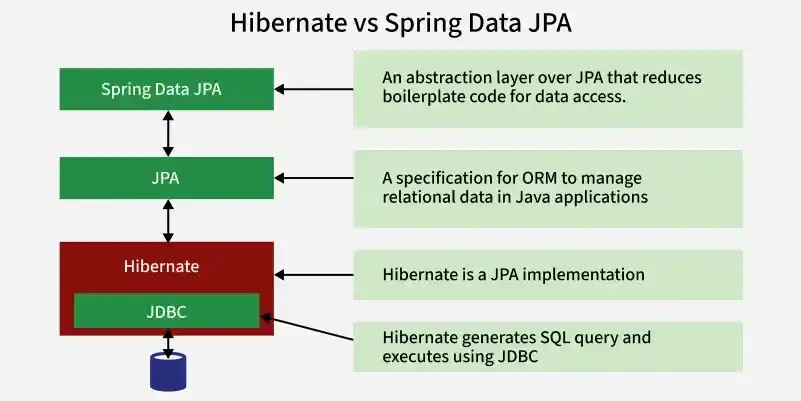
Spring Data JPA is a Spring framework module that simplifies database operations by providing ready-made repository interfaces for performing CRUD operations without writing SQL queries. It works on top of JPA (Java Persistence API) and internally uses Hibernate as the default ORM provider.
JPA and Hibernate are both used for ORM (Object Relational Mapping) in Java, but the main difference is that JPA is a specification, while Hibernate is a framework (implementation) that provides the actual working code.
| Feature | JPA | Hibernate |
|---|---|---|
| Type | Specification (Rules) | ORM Framework (Implementation) |
| Provided by | Java / Jakarta EE | Red Hat Community |
| Purpose | Defines ORM standards | Implements JPA + extra features |
| Dependency | Needs implementation | Works directly as ORM tool |
| Extra Features | Limited | Caching, HQL, extra annotations |
An Entity in Spring Data JPA is a Java class that represents a table in the database. Each object of the entity class represents one row (record), and its fields represent the table columns.
@Id is a JPA annotation used to define the primary key of an entity class. It tells JPA/Hibernate which field uniquely identifies each record (row) in the database table.
@GeneratedValue is a JPA annotation used to automatically generate values for the primary key field. It helps in auto-incrementing the @Id column without manually assigning values.
A Repository in Spring Data JPA is an interface that provides built-in methods to perform database operations like save, update, delete, and fetch records. It removes the need to write DAO classes and SQL queries for common CRUD tasks.
Example:
import org.springframework.data.jpa.repository.JpaRepository;
public interface StudentRepository extends JpaRepository<Student, Long> {
}
JpaRepository is a Spring Data JPA interface that provides complete database operations like CRUD, pagination, and sorting. It is mainly used to avoid writing DAO classes and common SQL queries.
CrudRepository and JpaRepository both are used to perform database operations in Spring Data JPA. The main difference is that CrudRepository provides only basic CRUD methods, while JpaRepository provides extra features like pagination, sorting, and batch operations.
| Feature | CrudRepository | JpaRepository |
|---|---|---|
| CRUD Support | Basic CRUD only | CRUD + many extra features |
| Pagination | Not available | Available (Pageable) |
| Sorting | Not available | Available (Sort) |
| Batch Operations | Not available | Available (saveAll(), etc.) |
| Flush | Not available | Available (flush()) |
| Best Use | Small/simple apps | Large/real projects |
The save() method in Spring Data JPA is used to store an entity in the database. It can perform both insert and update depending on whether the entity already has an ID value.
The findById() method in Spring Data JPA is used to retrieve an entity from the database using its primary key. It returns an Optional containing the entity if found, or empty if not.
Derived query methods in Spring Data JPA are methods in a repository interface whose names define the query automatically. Spring parses the method name and generates the corresponding SQL or JPQL behind the scenes.
The @Query annotation in Spring Data JPA is used to define custom JPQL or SQL queries directly on repository methods. It is helpful when derived query methods are not sufficient for complex queries.
Example:
@Query("SELECT s FROM Student s WHERE s.name = :name")
List<Student> findByStudentName(@Param("name") String name);
JPQL and SQL are both used to query databases, but the main difference is that JPQL works with entity objects, while SQL works directly with database tables. JPQL is object-oriented and database-independent.
| Feature | JPQL | SQL |
|---|---|---|
| Query Target | Works with Java entities | Works with database tables |
| Syntax | Object-oriented | Table/column-based |
| Database Dependency | Database-independent | Database-specific |
| Joins | Uses entity relationships | Uses table relationships |
| Return Type | Returns entity objects | Returns raw table rows |
In Spring Data JPA, nativeQuery is used with the @Query annotation to execute plain SQL queries directly on the database instead of using JPQL. It is helpful when JPQL cannot handle complex database-specific queries.
Example:
@Query(value = "SELECT * FROM student WHERE name = :name", nativeQuery = true)
List<Student> findByNameNative(@Param("name") String name);
Pagination in Spring Data JPA is a technique to fetch a subset of records from the database instead of retrieving all at once. It helps improve performance and manage large datasets efficiently.
Sorting in Spring Data JPA is used to arrange query results in a specific order based on one or more fields. It can be combined with pagination to get ordered subsets of data.
Example:
findAll(Sort.by(Sort.Direction.ASC, "name"))
@Transactional in Spring Data JPA is an annotation used to manage database transactions automatically. It ensures that all operations within a method are executed in a single transaction, and can be rolled back if an exception occurs.
Lazy and Eager loading are strategies in JPA to fetch related data from the database. They control when associated entities are loaded to optimize performance.
The N+1 problem in JPA occurs when loading a collection of entities causes an extra query for each associated entity, leading to performance issues. It happens mostly with lazy loading in relationships.
In Spring Data JPA, both save() and saveAndFlush() are used to persist entities, but the main difference is when changes are written to the database.
| Feature | save() | saveAndFlush() |
|---|---|---|
| Database Write | May delay until transaction commit | Immediately writes to database |
| Return | Saved entity | Saved entity |
| Use Case | Batch inserts/updates | Immediate persistence needed |
| Performance | Faster for multiple operations | Slightly slower due to immediate flush |
{kind=link}
{kind=link}
{kind=link}