Training deep learning models for too long on the same data can lead to overfitting where the model performs well on training data but poorly on unseen data. Dropout Regularization helps overcome this by randomly deactivating a portion of neurons during training hence forcing the model to learn more robust and independent features.
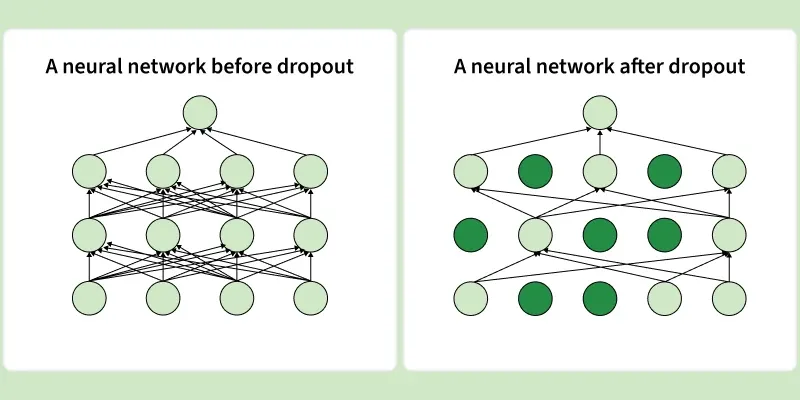
This image shows how dropout works by randomly deactivating neurons during training, forcing the network to rely on multiple paths and preventing overfitting
Why Dropout is needed
Dropout is needed because it prevents the network from relying too much on specific neurons, hence improving generalisation by training and reducing co-adaptation among neurons. Below are the key features of dropout:
Randomly deactivates a set percentage of neurons in each training step.
Works with dense, convolutional and recurrent layers.
Dropout rate controls how many neurons are dropped.
Remaining active neurons are scaled to maintain output stability.
Reduces co-dependency among neurons and improves generalization.
How it Works
Dropout works by randomly turning off a fraction of neurons during each training pass. When a neuron is dropped it sends no output and receives no weight updates for that batch. The dropout rate determines the probability of removing a neuron. A neuron output is modified as
where
: Dropout mask randomly sampled for each neuron.
: neuron is kept
: neuron is dropped
To keep activation values consistent during training inverted dropout is used where active neurons are scaled as:
where
: Original output of a neuron before dropout.
: Output after applying dropout (scaled or zeroed out).
This ensures that the expected output remains stable even when some neurons are dropped.
Note: During testing dropout is disabled meaning all neurons remain active and no randomness is applied. The network uses its full capacity and activations are scaled appropriately to match the expected values from training.
Types of Dropout Regularization
Standard Dropout: Randomly removes individual neurons during training to reduce overfitting.
Spatial Dropout: Drops entire feature maps in CNNs to preserve spatial structure.
Dropout2D / Dropout3D: Applies dropout across 2D or 3D feature channels for images and volumetric data.
DropConnect: Randomly drops weights instead of neurons, offering stronger regularization.
Alpha Dropout: Maintains activation statistics and works best with SELU-based networks.
Variational Dropout: Uses the same dropout mask across time steps in RNNs for stable learning.
Monte Carlo Dropout: Keeps dropout active at inference to estimate prediction uncertainty.
Step-by-step implementation
Here we build and compare two CNNs on MNIST one without dropout and one with dropout train and validate both evaluate on test data and visualize accuracy and sample predictions to show the effect of dropout.
Step 7: Visualize training curves & sample predictions
Plot training and validation loss and accuracy curves for both models.
Output:
Above graphs show that while the model without dropout achieves lower training loss and higher training accuracy it overfits quickly whereas the model with dropout maintains lower validation loss and higher validation accuracy, demonstrating better generalization.

{kind=link}
{kind=link}