 |
VOOZH | about |
|
VOOZH | about |
In classification problems, a machine learning model predicts the probability of each class for any given input. Because each data point truly belongs to only one class (probability 1 for one class, 0 for others). Cross-entropy loss is a way to measure how close a model’s predictions are to the correct answers in classification problems.
It helps train models to make more confident and accurate predictions by rewarding correct answers and penalizing wrong ones. This makes it a key part of building reliable machine learning classifiers.
Lets see types of Cross Entropy Loss functions:
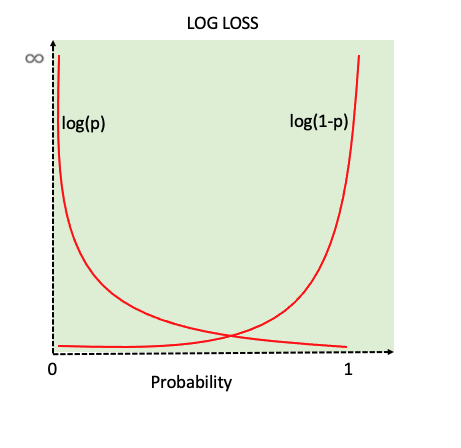
Binary Cross-Entropy Loss is a widely used loss function in binary classification problems. For a dataset with N instances, the Binary Cross-Entropy Loss is calculated as:
where
Multiclass Cross-Entropy Loss, also known as categorical cross-entropy or softmax loss is a widely used loss function for training models in multiclass classification problems. For a dataset with N instances, Multiclass Cross-Entropy Loss is calculated as
where
The cross-entropy loss is a scalar value that quantifies how far off the model's predictions are from the true labels. For each sample in the dataset, the cross-entropy loss reflects how well the model's prediction matches the true label. A lower loss for a sample indicates a more accurate prediction, while a higher loss suggests a larger discrepancy.
Interpretability for Binary Classification:
Interpretability for Multiclass Classification:
Let's see the differences between Hinge loss and Cross-Entropy loss:
| Feature | Hinge Loss | Cross Entropy Loss |
|---|---|---|
| Used In | Mainly in SVM (Support Vector Machines) | Mostly in classification with neural networks |
| Output Requirement | Works with labels as -1 and +1 | Works with labels as probabilities (0 or 1 for binary) |
| Formula (binary) | max(0, 1 - y·f(x)) | -y·log(p) - (1-y)·log(1-p) |
| Penalty Type | Penalizes wrong classifications with a margin | Penalizes based on probability difference |
| Prediction Type | Margin-based classification | Probability-based classification |
| Smoothness | Not differentiable at margin | Smooth and fully differentiable |
| Better For | When a large margin is important | When confidence in predictions is important |
| Loss Value Behavior | Becomes 0 when prediction is beyond margin | Always greater than 0 unless prediction is perfect |
Step 1: Load and Prepare the Data
ContractType to convert them to numeric features.X) and target (y).Step 2: Split Data and Convert to PyTorch Tensors
X_train) and labels (y_train) to PyTorch tensors.Step 3: Create DataLoader for the Training Loop and Define the Neural Network
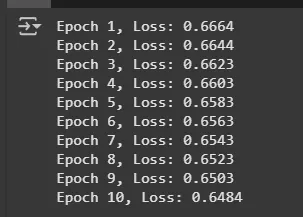
Step 4: Specify Loss Function and Optimizer Training Loop
Step 1: Load and Standardize Data
Step 2: Split Data and Convert to Tensors and Create DataLoader
Step 3: Define Neural Network and Specify Loss and Optimizer
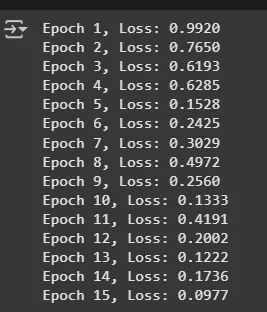
Step 4: Training Loop
For each epoch:
Cross-entropy loss is the standard metric for training and evaluating classification models. It drives models to give accurate, confident probability predictions by sharply penalizing wrong outputs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}