 |
VOOZH | about |
|
VOOZH | about |
In this article, we will explore how to implement a basic transformer model using PyTorch , one of the most popular deep learning frameworks. By the end of this guide, you’ll have a clear understanding of the transformer architecture and how to build one from scratch.
Transformersare neural network architectures introduced in the paper "Attention is All You Need" (2017). Unlike traditional recurrent neural networks (RNNs), Transformers use the attention mechanism to process sequences in parallel, significantly improving efficiency and scalability. They are particularly effective in NLP tasks like text generation, language translation, and sentiment analysis.
Attention mechanismallows models to weigh the importance of different words in a sequence. In self-attention, each word in a sentence considers all other words computing a score to determine how much attention it should pay to each word. This enables the model to capture relationships between words effectively.
Now lets start building our transformer model.
To construct the Transformer model, we need to follow these key steps:
This block imports the necessary libraries and modules such as PyTorch for neural network creation and other utilities like math and copy for calculations.
This block defines the MultiHeadAttention class. It splits the input into multiple attention heads, computes scaled dot-product attention, and then combines the outputs.
nn.Linear(d_model, d_model): Initializes a linear transformation for the query, key and value vectors in multi-head attention.torch.matmul(Q, K.transpose(-2, -1)): Calculates the dot product between the query and key vectors used for attention scoring.torch.softmax(attn_scores, dim=-1): Applies the softmax function on attention scores to get the normalized attention probabilities.torch.matmul(attn_probs, V): Uses the attention probabilities to weight the value vectors and compute the final output of the attention mechanism.This block defines a position-wise feed-forward network which consists of two linear layers and a ReLU activation to process each position of the input sequence independently.
self.fc1 = nn.Linear(d_model, d_ff): Initializes a linear transformation to map input embeddings to a higher-dimensional space (d_ff) used in the feed-forward network.self.relu = nn.ReLU(): Defines the ReLU activation function to introduce non-linearity between the two fully connected layers.self.fc2 = nn.Linear(d_ff, d_model): Maps the output back to the model’s original dimension (d_model).This block defines the Positional Encoding class which adds positional information to the token embeddings allowing the model to retain information about word positions in the input sequence.
torch.sin(position * div_term): Applies the sine function to compute positional encoding values for even indices.torch.cos(position * div_term): Applies the cosine function to compute positional encoding values for odd indices.self.register_buffer('pe', pe.unsqueeze(0)): Registers the positional encoding as a buffer so that it is part of the model but not considered a parameter during optimization.This block defines the Encoder Layer class which contains the multi-head attention mechanism and the position-wise feed-forward network, with layer normalization and dropout applied.
attn_output = self.self_attn(x, x, x, mask): Performs self-attention on the input, where the input sequence attends to itself.self.norm1(x + self.dropout(attn_output)): Adds the attention output to the input and applies layer normalization.self.feed_forward(x): Passes the result through a position-wise feed-forward network to refine the embeddings.This block defines the Decoder Layer class, which is similar to the encoder layer but also includes a cross-attention mechanism to attend to the encoder’s output.
attn_output = self.self_attn(x, x, x, tgt_mask): Performs self-attention on the target sequence attending to the target sequence itself.attn_output = self.cross_attn(x, enc_output, enc_output, src_mask): Performs cross-attention where the target sequence attends to the encoder's output sequence.self.norm2(x + self.dropout(attn_output)): Adds the attention output from the cross-attention mechanism to the input and applies layer normalization.This block defines the main Transformer class which combines the encoder and decoder layers. It also includes the embedding layers and the final output layer.
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model): Initializes the embedding layer for the source sequence, mapping tokens to continuous vectors of size d_model.self.fc = nn.Linear(d_model, tgt_vocab_size): Maps the final output embeddings from the decoder to the target vocabulary size to predict the output tokens.self.generate_mask(src, tgt): Generates source and target masks to prevent attention to certain parts of the input, such as padding or future tokens in the target sequence.This block defines the training loop using Cross-Entropy loss and the Adam optimizer then trains the model for 100 epochs.
optimizer.zero_grad(): Clears the gradients of all optimized tensors before the backward pass.loss.backward(): Computes the gradients of the loss with respect to the model parameters.optimizer.step(): Updates the model parameters based on the gradients computed during backpropagation.Output:
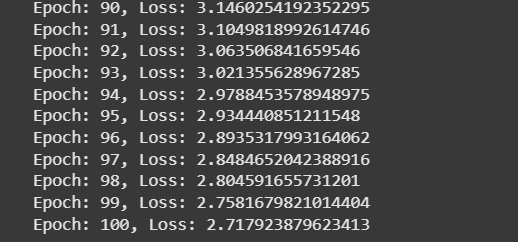
This indicates that the model is learning effectively as the loss decreases with each epoch meaning the model is becoming better at making predictions. The gradual decline in loss suggests that the model is improving its accuracy and minimizing errors over time.
This block evaluates the trained model on validation data by calculating the validation loss.
torch.no_grad(): Disables gradient calculation during the evaluation phase to save memory and computational resources.val_output = transformer(val_src_data, val_tgt_data[:, :-1]): Performs a forward pass on the validation data to obtain model predictions.criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1)): Computes the loss between the model's predictions and the true target values for evaluation.Output:
Validation Loss: 8.820590019226074
Transformers have proven highly effective in a variety of NLP tasks:
Building LLMs from scratch requires an understanding of the Transformer architecture and the self-attention mechanism. By following the steps outlined in this article you can implement your own Transformer model using PyTorch and can further fine tune it for specific tasks. Though transformers have their limitations and it’s important to consider their computational costs and data requirements in real-world applications.
You can download Source code from here.
{kind=link}
{kind=link}
{kind=link}