 |
VOOZH | about |
|
VOOZH | about |
Positional encoding is a technique that adds information about the position of each token in the sequence to the input embeddings. This helps transformers to understand the relative or absolute position of tokens which is important for differentiating between words in different positions and capturing the structure of a sentence. Without positional encoding, transformers would struggle to process sequential data effectively.
Unlike traditional models which can struggle with long-term dependencies and varying sequence lengths, transformers with positional encoding can handle longer sequences effectively.
Suppose we have a Transformer model which translates English sentences into French.
"The cat sat on the mat."
Before the sentence is fed into the Transformer model it gets tokenized where each word is converted into a token. Let's assume the tokens for this sentence are:
["The", "cat" , "sat", "on", "the" ,"mat"]
After that each token is mapped to a high-dimensional vector representation through an embedding layer. These embeddings encode semantic information about the words in the sentence. However they lack information about the order of the words.
Embeddings ={}
where each is a 4-dimensional vector. This is where positional encoding plays an important role. To help the model to understand the order of words in a sequence these are added to the word embeddings and they assign each token a unique representation based on its position in the sequence.
The most common method for calculating positional encodings is based on sinusoidal functions. The intuition behind using sine and cosine functions is that they provide a smooth, periodic encoding of positions that allows for easy interpolation and generalization across sequences of varying lengths.
For each position () in the sequence and each dimension in the positional encoding vector, the following formula is used:
Where:
These formulas use sine and cosine functions to create wave-like patterns that changes across the sequence positions. Using sine for even indices and cosine for odd indices helps in getting a combination of features that can effectively represent positional information across different sequence lengths.
We will now calculate the positional encodings for the positions 1, 2 till 6 in a sequence. For simplicity, let's assume that we are working with a 4-dimensional embedding.
1. Positional Encoding for Token at Position 1: For (the first token), the positional encoding values will be:
Here the first pair of values is generated using the sine and cosine functions for the first dimension and the second pair is for the second dimension.
2. Positional Encoding for Token at Position 2: Similarly for (the second token), we calculate the positional encoding values:
These values provide positional information for the second token in the sequence. In the same way we will do till 5th position.
3. Positional Encoding for Token at Position 6: For (the sixth token), the positional encoding is calculated in the same way:
Once these positional encodings are calculated for each token at its corresponding position, they are added element-wise to the word embeddings. This process ensures that the final token embedding contains both semantic information (from the word embedding) and positional information (from the positional encoding).
Here we will be using Numpy and Tensorflow libraries for its implementations.
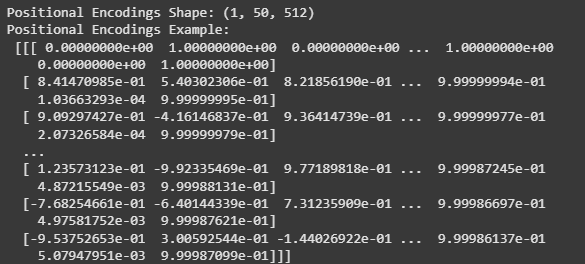
Output:
Array provided is the positional encodings generated by the positional_encoding function for a sequence of length 10 and a model dimensionality of 512. Each row in the array corresponds to a position in the sequence and each column represents a dimension in the model.
Positional encoding plays an important role in various transformer-based models particularly in tasks that involve sequential data. Some common applications include:
Positional encodings are important in Transformer models for various reasons:
Despite positional encoding has various advantages, it has a few limitations:
By adding important positional information, positional encodings allow Transformer models to understand the relationships and order of tokens which ensures it processes sequential data while parallel processing.
{kind=link}
{kind=link}