 |
VOOZH | about |
|
VOOZH | about |
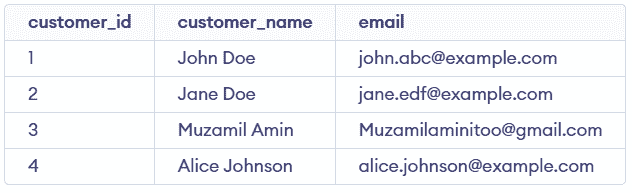
Duplicate rows in MySQL can lead to inaccurate results and make data analysis more difficult. Removing duplicates is essential to maintain data consistency and integrity in your database.
Note: Some features are only supported in MySQL 8.0 and later versions. If you are using an older version of MySQL, these features may result in errors.
There are multiple strategies for handling and removing duplicate rows in MySQL. First, let’s create a demo table with duplicate entries to demonstrate these methods:
The DELETE statement removes duplicate rows while keeping one occurrence of each customer_id. It uses ROW_NUMBER() to identify and remove duplicate rows.
Query:
WITH CTE AS (
SELECT customer_id,
customer_name,
email,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY customer_id
) AS row_num
FROM customers
)
DELETE FROM customers
WHERE (customer_id, customer_name, email) IN (
SELECT customer_id, customer_name, email
FROM CTE
WHERE row_num > 1
);Output:
Note: This method works correctly when duplicate rows are not completely identical. If all column values are exactly the same and no unique identifier exists, MySQL may delete all matching rows.
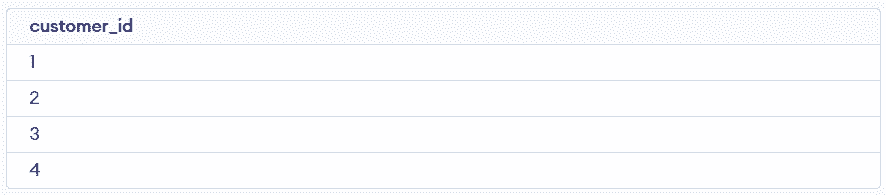
The DISTINCT keyword is used to retrieve unique values from a table by filtering out duplicates. It is useful when you want to view clean, non-repeated data without modifying the table.
Query:
SELECT DISTINCT customer_id
FROM customers;Output:
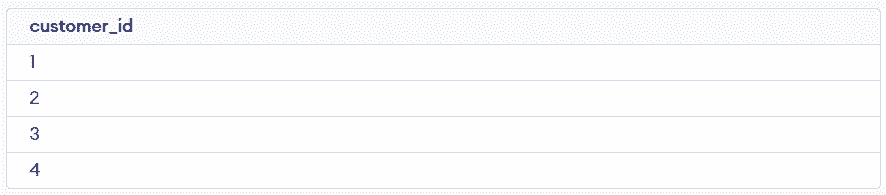
The GROUP BY clause groups rows based on a specific column to identify unique values. It is commonly used to organize data and perform aggregations.
Query:
SELECT customer_id
FROM customers
GROUP BY customer_id;Output:
The HAVING clause filters grouped results based on conditions applied to aggregated data. It is mainly used to identify duplicate entries by checking group counts.
Query:
SELECT customer_id
FROM customers
GROUP BY customer_id
HAVING COUNT(*) > 1;Output:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}