 |
VOOZH | about |
|
VOOZH | about |
Seaborn is a Python library for creating attractive statistical visualizations. Built on Matplotlib and integrated with Pandas, it simplifies complex plots like line charts, heatmaps and violin plots with minimal code.
Seaborn makes it easy to create clear and informative statistical plots with just a few lines of code. It offers built-in themes, color palettes, and functions tailored for different types of data.
Let’s see various types of plots with simple code to understand how to use it effectively.
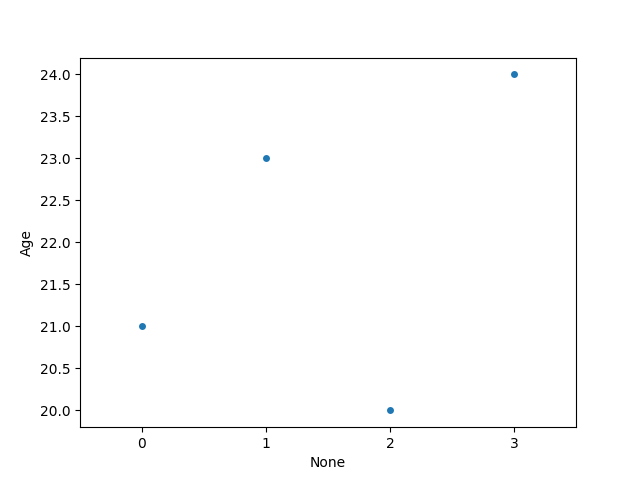
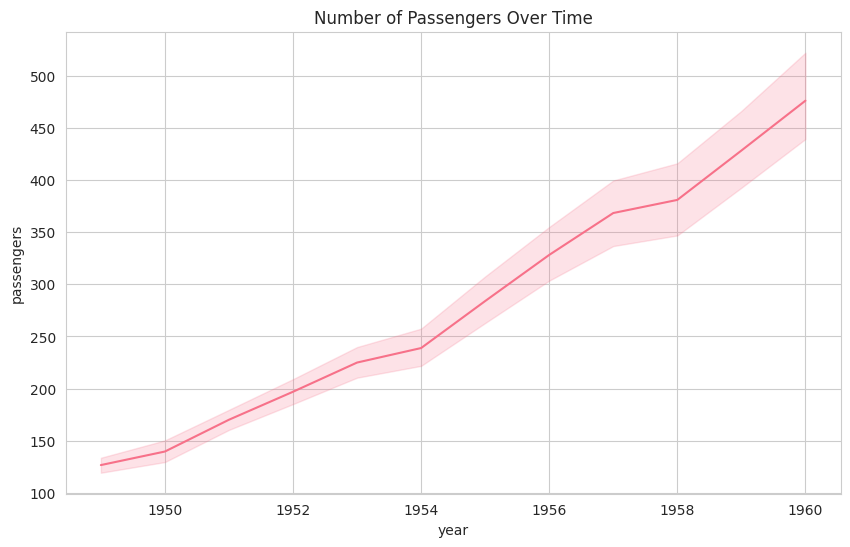
A line plot shows the relationship between two numeric variables, often over time. It can also compare multiple groups using different lines.
Syntax:
sns.lineplot(x=None, y=None, data=None)
Parameters:
Example:
Output
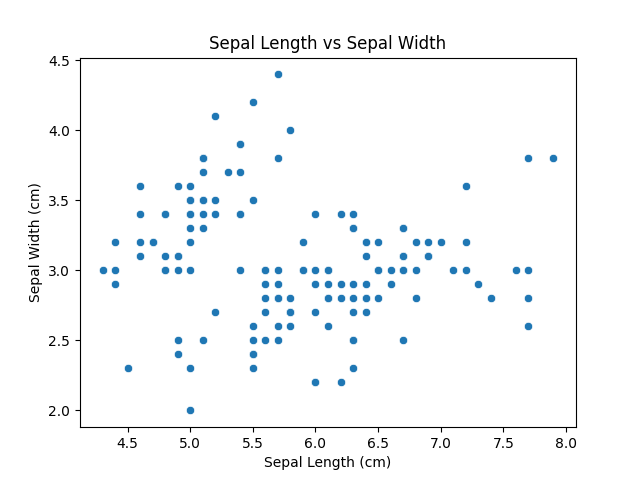
Scatter plots are used to visualize the relationship between two numerical variables. They help identify correlations or patterns. It can draw a two-dimensional graph.
Syntax:
sns.scatterplot(x=None, y=None, data=None)
Parameters:
Returns: An Axes object with the scatter plot.
Example:
Output
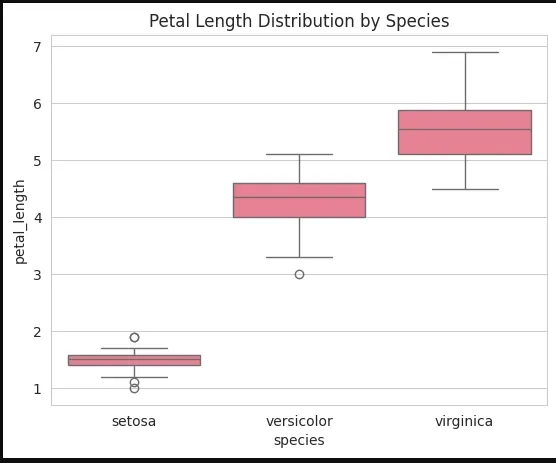
A box plot is the visual representation of the depicting groups of numerical data with their quartiles against continuous/categorical data.
It consists of 5 key statistics: Minimum ,First Quartile or 25% , Median (Second Quartile) or 50%, Third Quartile or 75% and Maximum
Syntax:
sns.boxplot(x=None, y=None, hue=None, data=None)
Parameters:
Returns: An Axes object with the box plot.
Example:
Output
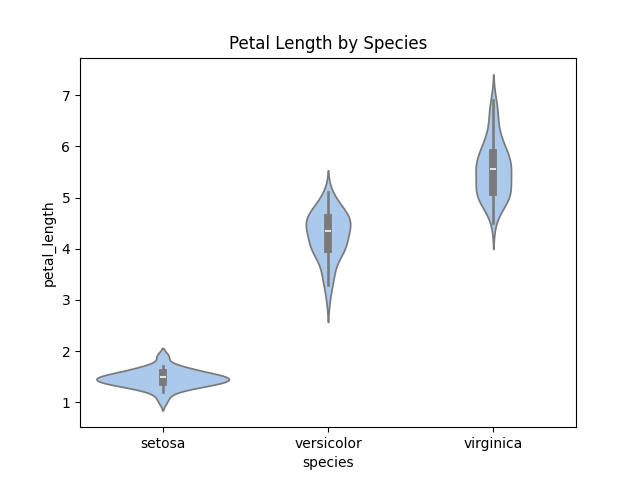
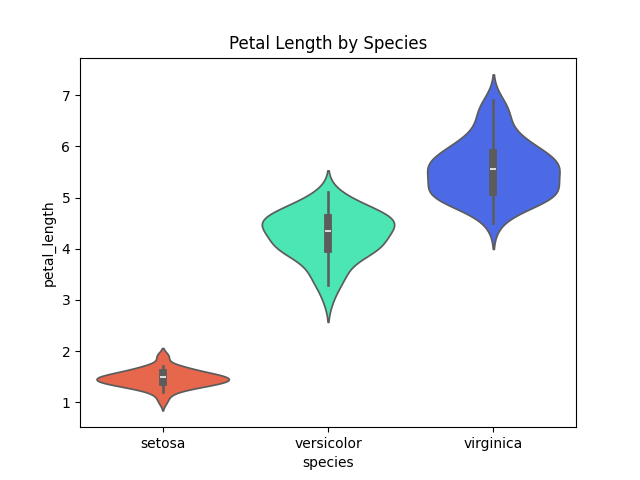
A violin plot is similar to a boxplot. It shows several quantitative data across one or more categorical variables such that those distributions can be compared.
Syntax:
sns.violinplot(x=None, y=None, hue=None, data=None)
Parameters:
Example:
Output
A swarm plot displays individual data points without overlap along a categorical axis which provides a clear view of distribution density.
Syntax:
sns.swarmplot(x=None, y=None, hue=None, data=None)
Parameters:
Example:
Output
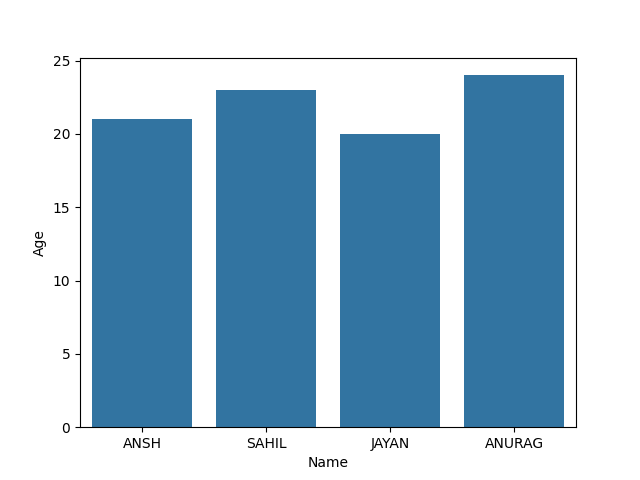
Barplot represents an estimate of central tendency for a numeric variable with the height of each rectangle and provides some indication of the uncertainty around that estimate using error bars.
Syntax:
sns.barplot(x=None, y=None, hue=None, data=None)
Parameters :
Returns: Axes object with the bar plot.
Example:
Output
Point plot show point estimates and confidence intervals using scatter glyphs which represents the central tendency of a numeric variable.
Syntax:
sns.pointplot(x=None, y=None, hue=None, data=None)
Parameters:
Return: Axes object with the point plot.
Example:
Output
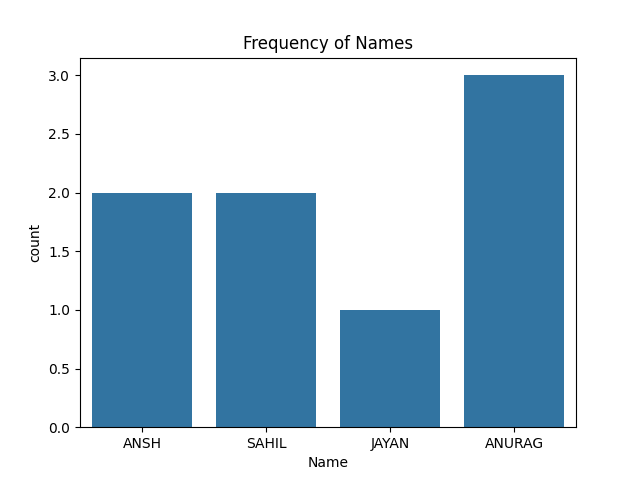
A Count plot displays the number of occurrences of each category using bars to visualize the distribution of categorical variables.
Syntax :
sns.countplot(x=None, y=None, hue=None, data=None)
Parameters :
Returns: Axes object with the count plot.
Example:
Output
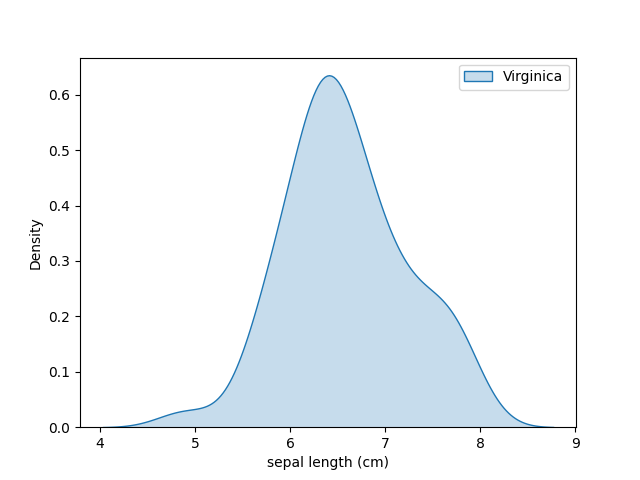
KDE Plot (Kernel Density Estimate) is used for visualizing the Probability Density of a continuous variable at different values in a continuous variable. We can also plot a single graph for multiple samples which helps in more efficient data visualization.
Syntax:
sns.kdeplot(data=None, x=None, y=None, fill=False)
Parameters:
Example:
Output
Customizing Seaborn plots increases their readability and visual appeal which makes the data insights clearer and more informative. Here are several ways we can customize our plots in Seaborn:
Adding descriptive titles and axis labels makes our plots more understandable and informative. Using Matplotlib's plt.title(), plt.xlabel() and plt.ylabel() to set titles and axis labels.
Output
Seaborn provides built-in styles that control the background and grid of your plots. These styles improve readability and can be chosen based on your presentation needs.
Available Styles:
Output
Seaborn makes it easy to enhance the appearance of plots using color palettes. You can choose from built-in palettes like "deep", "muted", or "bright" or define your own using sns.color_palette(). Customizing colors improves clarity and helps match your data’s theme or purpose.
a) Using a Built-in Palette:
Output
b) Using a Custom Palette:
We can adjust the figure size using plt.figure(figsize=(width,height)) to control the plot's dimensions. This allows for better customization to fit different presentation or reports.
Output
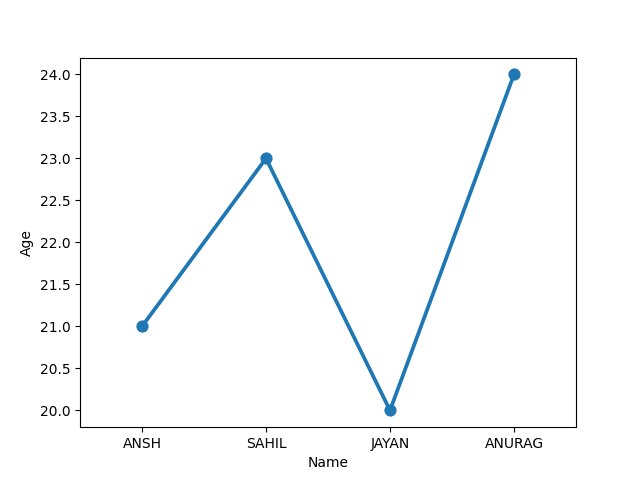
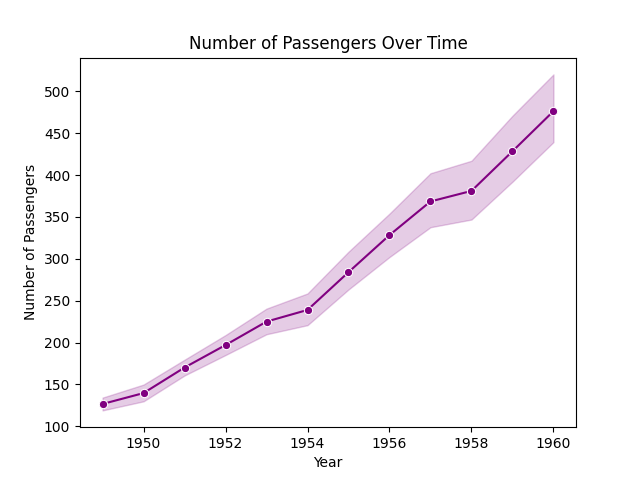
Markers can be added to Seaborn line plots using the marker argument to highlight data points. For example adding circular markers to the line plot using sns.lineplot(x='x', y='y' ,marker='o')
Output
We’ll see various plots in Seaborn for visualizing relationships, distributions and trends across our dataset. These visualizations help to find hidden patterns and correlations in datasets with multiple variables.
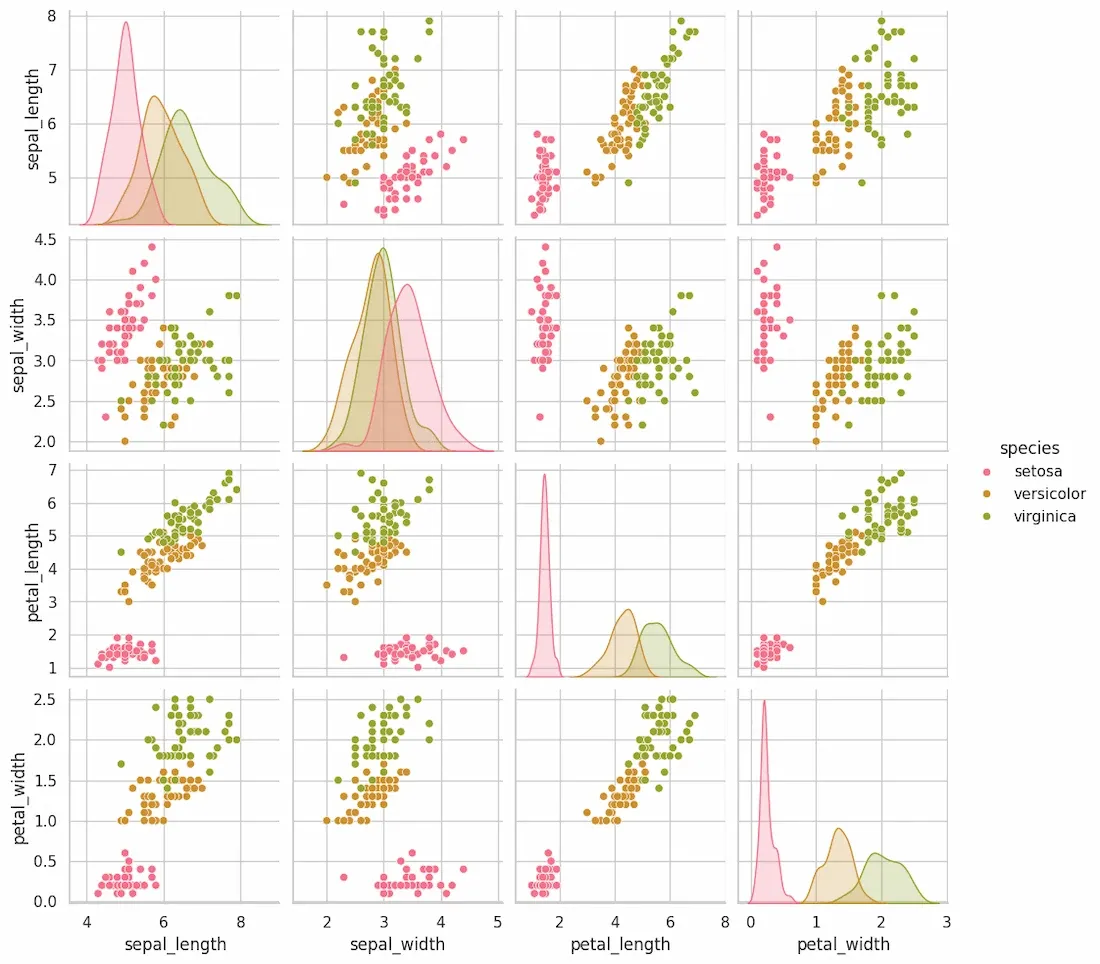
Pair plots are used explore relationships between several variables by generating scatter plots for every pair of variables in a dataset along with univariate distributions on the diagonal. This is useful for exploring datasets with multiple variables and seeing potential correlations.
Syntax:
sns.pairplot(data, hue=None)
Parameters:
Returns: An array of Axes objects containing the scatter plot grid and distributions.
Example:
Output
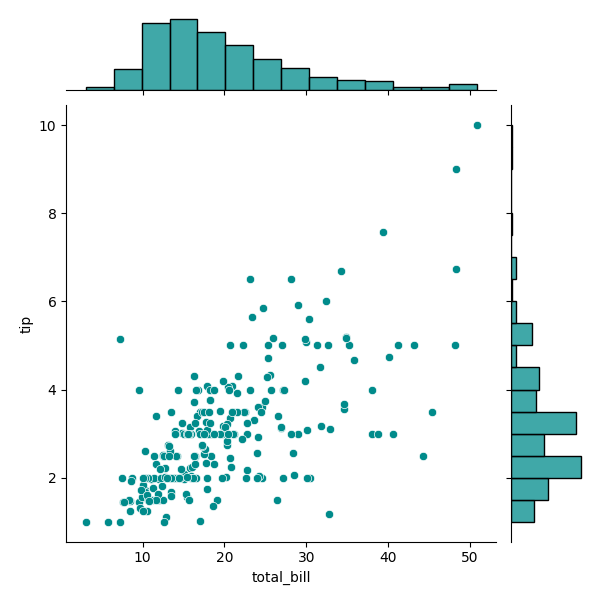
Joint plots combine a scatter plot with the distributions of the individual variables. This allows for a quick visual representation of how the variables are distributed individually and how they relate to one another.
Syntax:
sns.jointplot(x, y, data, kind='scatter')
Parameters:
Returns:
An Axes object with the joint plot including scatter plot and distribution plots on the margins.
Example:
Output
This creates a scatter plot between total_bill and tip with histograms of the individual distributions along the margins. The kind parameter can be set to 'kde' for kernel density estimates or 'reg' for regression plots.
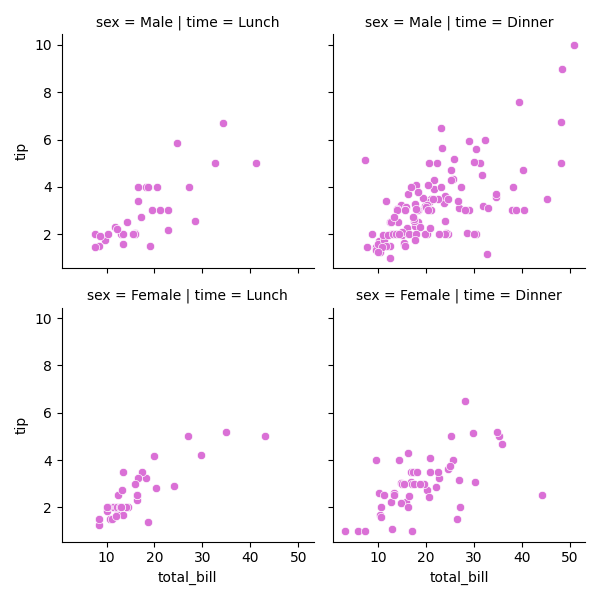
Grid plots in Seaborn are used to create multiple subplots in a grid layout. Using Seaborn's FacetGrid we can visualize how variables interact across different categories which makes it easier to compare groups or conditions within our dataset.
Syntax:
g = sns.FacetGrid(data, col='column_name', row='row_name')
g.map(sns.scatterplot, 'x', 'y')
Parameters:
Returns: A FacetGrid object with the grid of plots.
Example: To use FacetGrid, we first need to initialize it with a dataset and specify the variables that will form the row, column or hue dimensions of the grid. Here is an example using the tips dataset:
Output
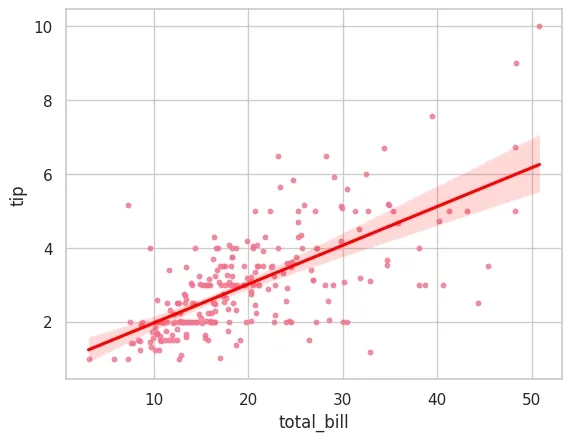
Seaborn simplifies the process of performing and visualizing regressions specifically linear regressions which is important for identifying relationships between variables, detecting trends and making predictions. It supports two primary functions for regression visualization:
Example: Let’s use a simple dataset to visualize a linear regression between two variables: x (independent variable) and y (dependent variable).
Output:
As we explore Seaborn functions and techniques we can create clear, customized and insightful visualizations that helps us to understand our data better.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}