 |
VOOZH | about |
|
VOOZH | about |
Cross-attention mechanism is a key part of the Transformer model. It allows the decoder to access and use relevant information from the encoder. This helps the model focus on important details, ensuring tasks like translation are accurate.
Imagine generating captions for images (decoder) from a detailed description (encoder). Cross-attention helps the caption generator focus on key details, ensuring accuracy in the caption.
Cross-attention enables different parts of the model to communicate and share useful information for better results.
Let's use a simple analogy to explain the process:
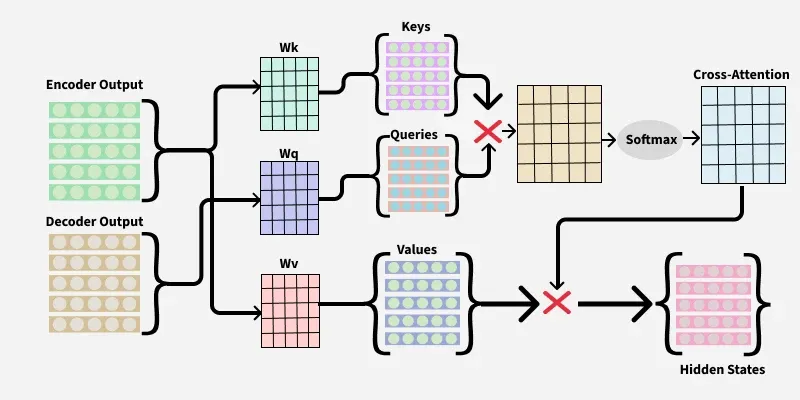
In the above image, the first red cross represents the dot product of queries and keys and the second red cross represents dot product of cross-attention and values.
The formula for Cross-attention is very similar to self-attention, except the query () comes from the decoder's output and the key (), value () come from the encoder's output.
Here, is the dimensionality of the keys.
Cross-attention can get pretty complex, and it mostly depends on how long the input is and how many attention heads the model has. The main things it does are calculating dot products and using the softmax function to figure out the attention weights. For cross-attention, the complexity usually looks like this:
Cross-Attention takes about time.
The part comes from comparing each word with every other word, which makes a big × matrix.
Cross-Attention needs about space. This is because it has to store the attention matrix, which is ×.
As the sequence gets longer, the complexity grows fast, making the Transformer model use a lot of computing power. But, new ideas like sparse attention and efficient transformers are helping to make this less of a problem.
Cross-attention assists the decoder in focusing on the encoder's most important information. Whether you're translating a sentence, creating a novel or even describing an image, this makes the entire process more accurate and efficient.
In tasks like machine translation, cross-attention helps the system align words from the source language with the most relevant words in the target language. This alignment is crucial for creating accurate and natural translations.
For example, when translating "I like eating ice cream" into another language, cross-attention helps the system understand that "ice cream" is important and should be translated correctly.
Aspect | Cross-attention | Self-attention |
|---|---|---|
Definition | Allows the decoder to use information from the encoder. | Allows each word in a sequence to focus on other words in the same sequence. |
Uses | Used in tasks like translation, where the model must look at the entire input (encoder) while generating output. | Used to understand relationships within a single input (e.g. text) without external context. |
Focus | Focuses on picking useful information from another part of the model. | Focuses on how words in the same sentence relate to each other. |
Data Flow | Involves interaction between two different data parts (encoder and decoder). | Data flows within the same sequence (internal attention). |
Example | In translation, cross-attention helps the decoder choose the right words from the encoder. | In text analysis, self-attention helps the model understand how words in the sentence connect. |
Cross-attention mechanism in transformers not only enhances current model capabilities but also opens avenues for future advancements in interpretability, adaptability and scalability, enabling richer interactions with external knowledge bases and other systems.
{kind=link}
{kind=link}