 |
VOOZH | about |
|
VOOZH | about |
DistilBERT is a distilled version of BERT meaning it is trained using knowledge distillation a technique where a smaller model (student) learns from a larger model (teacher). It retains 97% of BERT’s performance while being 40% smaller and 60% faster making it highly efficient for NLP tasks such as text classification, sentiment analysis and question-answering.
DistilBERT focuses on the following key objectives:
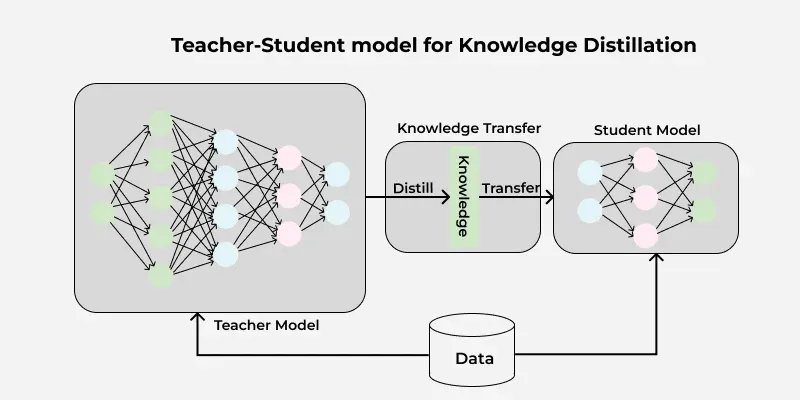
DistilBERT utilizes knowledge distillation where a smaller model (student) learns to replicate the behavior of a larger model (teacher). This process involves training the student model to mimic the predictions and internal representations of the teacher model.
In the above diagram the teacher model (BERT) is a large neural network with many parameters. The student model (DistilBERT) is a smaller network trained to replicate the teacher’s behavior using knowledge transfer. The distillation process involves minimizing the difference between the teacher’s soft predictions and the student’s output allowing the student model to retain most of the teacher’s knowledge while being significantly smaller.
DistilBERT is trained using a triple loss function which combines:
By combining these losses DistilBERT is able to learn efficiently from BERT while maintaining high performance.
Let’s implement DistilBERT for a text classification task using the transformers library by Hugging Face. We’ll use the IMDb movie review dataset to classify reviews as positive or negative.
First install the necessary libraries:
pip install transformers datasets torch
We'll use the IMDb dataset available in Hugging Face's datasets library.
DistilBERT requires input data to be tokenized. We’ll use the AutoTokenizer class to preprocess the text.
We’ll use the AutoModelForSequenceClassification class to load a pre-trained DistilBERT model fine-tuned for sequence classification.
We’ll use the Trainer API from Hugging Face to simplify the training process.
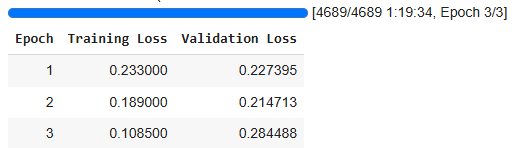
Output:
TrainOutput(global_step=4689, training_loss=0.17010223817522782, metrics={'train_runtime': 4774.8481, 'train_samples_per_second': 15.707, 'train_steps_per_second': 0.982, 'total_flos': 9935054899200000.0, 'train_loss': 0.17010223817522782, 'epoch': 3.0})
After training evaluate the model on the test dataset.
Output:
Evaluation Results: {'eval_loss': 0.28448769450187683, 'eval_runtime': 383.5344, 'eval_samples_per_second': 65.183, 'eval_steps_per_second': 4.075, 'epoch': 3.0}
You can use the trained model to make predictions on new data.
Output:
Positive
DistilBERT shines in a variety of NLP tasks:
While DistilBERT is impressive, it’s not without trade-offs. The reduction in size means it may struggle with extremely complex language tasks where BERT’s deeper architecture excels. For cutting-edge research or niche applications requiring peak performance, the original BERT or even larger models like RoBERTa might still be preferred.
DistilBERT offers an excellent balance between performance and efficiency, making it a go-to choice for many NLP applications. Whether you’re working on sentiment analysis, question answering, or any other NLP task DistilBERT is a powerful tool that can help you achieve great results without breaking the bank on computational resources.
{kind=link}
{kind=link}
{kind=link}