 |
VOOZH | about |
|
VOOZH | about |
Fake news is a type of misinformation that can mislead readers, influence public opinion, and even damage reputations. Detecting fake news prevents its spread and protects individuals and organizations. Media outlets often use these models to help filter and verify content, ensuring that the news shared with the public is accurate.
In this article we'll build a deep learning model using TensorFlow in Python to detect fake news from text.
We will be building the model with following steps to make our model:
The libraries we will be using are numpy, pandas, scikit learn and tenserflow
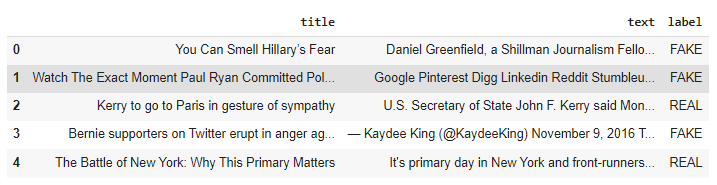
We will be using fake news dataset, which contains News text and corresponding label (FAKE or REAL). Dataset can be downloaded from this link.
Output:
As we can see the dataset contains one unnamed column. So we drop that column from the dataset.
Output:
Now that data is cleaned we can go for data encoding.
It converts the categorical column (label in out case) into numerical values.
le.fit(data['label']): Fits the encoder on the 'label' column to learn the unique categories.data['label'] = le.transform(data['label']): Transforms the categorical labels into numerical format (0 for REAL, 1 for FAKE).These are some variables required to be setup for the model training.
This process divides a large piece of continuous text into distinct units or tokens. Here we use columns separately for a temporal basis as a pipeline just for good accuracy.
tokenizer1.fit_on_texts(title): Fits the tokenizer on the 'title' column to create a vocabulary.pad_sequences(sequences1): Pads the sequences to ensure they all have the same length.training_sequences1, test_sequences1: Splits the tokenized and padded data into training and testing sets.training_labels, test_labels: Splits the corresponding labels into training and testing labels.We will be using LSTM(Long Short Term Memory) model for prediction and for that we need to reshape padded sequence. We are converting it into np.array() as we need training and test sequences into NumPy arrays which are required by TensorFlow models.
Embeddings allows words with similar meanings to have a similar representation. Here each individual word is represented as real-valued vectors in a predefined vector space. For that we will be using glove.6B.50d.txt.
!wget: Downloads the pre-trained GloVe embeddings from the following link.!unzip: Unzips the downloaded file containing the GloVe embeddings.Output:
Now that our glove embeddings are downloaded we can use them for word embedding.
Here we use the TensorFlow embedding technique with Keras Embedding Layer where we map original input data into some set of real-valued dimensions.
Embedding: The embedding layer uses pre-trained GloVe embeddings.Conv1D: A 1D convolutional layer to detect patterns in the text.LSTM(64): An LSTM layer to capture long-term dependencies in the data.Output :
Now that our model architecture is ready we can use this to train our model.
Output:
For each epoch training accuracy improves reaching around 97% by the 50th epoch while the validation accuracy is around 75%. The validation loss gradually decreases, indicating that the model is learning from the data but it also shows signs of some overfitting as the validation accuracy is lower than the training accuracy. To avoid this we can further fine tune the model.
We will test model accuracy with a sample of text to see how our model is working.
Output:
This news is False
As we can see our model is working fine and now can be used to detect of any information is fake or not.
By following these steps we successfully built a fake news detection model using TensorFlow in Python. This model can be further improved by fine-tuning the hyperparameters, trying different architectures or using more advanced techniques like attention mechanisms. In real-world applications such models can be integrated into news websites or social media platforms to automatically flag fake news.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}