 |
VOOZH | about |
|
VOOZH | about |
Music generation involves creating musical compositions using various methods, including manual composition, algorithmic processes, and digital tools. ABC Notation is a text-based music notation system that allows users to write and share musical scores using simple ASCII characters.
ABC Notation is crucial for easily transcribing, sharing, and converting musical pieces into different formats, making it widely used in both traditional and digital music composition.
In this article, we are going to work a project to generate music using the ABC version of the Nottingham Music Database.
Recurrent Neural Networks (RNNs), and their more advanced variants like Long Short-Term Memory (LSTM) networks, are well-suited for music generation due to their ability to model sequential data and capture temporal dependencies.
Here are the key reasons why RNNs are used for music generation:
The first step of the project is to download the file from the given URL and save it to a local directory using Python's requests and os modules. The process ensures the target directory exists, retrieves the file content from the URL, and writes it to the specified local path. Finally, it reads and prints the content from the saved file.
Output:
X: 1
T:Raggety Anne
% Nottingham Music Database
S:Kevin Briggs, via EF
M:4/4
L:1/4
K:D
A/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|"D"D/2F/2A/2F/2 BA/2F/2\
|"A7"A/2cA/2 c3/2B/2|
"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|\
"A7"A/2B/2c/2d/2 e/2g/2f/2e/2|
"D"d/2c/2d/2e/2 "A7"d/2B/2A/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|\
"D"D/2F/2A/2F/2 BA/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|
"A7"A/2cA/2 c3/2B/2|"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|\
"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|"A7"A/2B/2c/2d/2 e/2g/2f/2e/2|
"D"d3f/2g/2|"D"a/2f/2A/2a/2 f/2A/2a/2A/2|"D"f/2d/2A/2f/2 d/2A/2f/2A/2|\
"D7"d/2=c/2A/2d/2 "e"^c"f#"=c|
"G"B3e/2f/2|"A7"g/2f/2e/2f/2 g/2f/2e/2f/2|"A7"g/2f/2e/2d/2 ce/2f/2|\
"A7"g/2f/2e/2d/2 cB|
"A7"A3f/2g/2|"D"a/2f/2A/2a/2 f/2A/2a/2A/2|"D"f/2d/2A/2f/2 d/2A/2f/2A/2|\
"D7"d/2=c/2A/2d/2 "e"^c"f#"=c|
"G"B3e/2f/2|"A7"g/2f/2e/2f/2 g/2f/2e/2f/2|"A7"g/2f/2e/2f/2 g2|\
"A7"A/2^G/2A/2^A/2 Bc|"D"d3||
. . .
This code processes a list of ABC notation tunes by removing metadata lines and formatting the notation for conversion to MIDI. It splits the file content into individual tunes, preprocesses each tune to clean up unnecessary lines, and prepares the notation for conversion. The music21 library is used to parse the first tune and convert it into a MIDI file for playback.
Output:
90M:4/4
L:1/4
K:D
A/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|"D"D/2F/2A/2F/2 BA/2F/2\
|"A7"A/2cA/2 c3/2B/2|
"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|"A7"A/2B/2c/2B/2 A/2B/2c/2B/2|\
"A7"A/2B/2c/2d/2 e/2g/2f/2e/2|
"D"d/2c/2d/2e/2 "A7"d/2B/2A/2F/2|"D"D/2F/2A/2F/2 BA/2F/2|\
. . .
This step involves creating a vocabulary of unique characters from the preprocessed ABC notation tunes, mapping each character to an index, and printing a sample of this mapping. The process ensures each unique character in the tunes is identified and can be referenced by its index, facilitating further analysis or processing.
Output:
60
{
'\n': 0,
' ' : 1,
'!' : 2,
'"' : 3,
'#' : 4,
"'" : 5,
'(' : 6,
.
.
.
'v' : 56,
'w' : 57,
'z' : 58,
'|' : 59,
...
}
This step prepares the data for training a sequence model by creating input sequences (x_train) and corresponding target values (y_train) from the preprocessed tunes. The data is reshaped to match the input requirements of sequence models, such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks.
This step constructs an LSTM-based neural network model for sequence prediction using TensorFlow's Keras API. The model architecture includes an embedding layer for input representation, multiple LSTM layers for capturing sequential patterns, and dropout layers to prevent overfitting. The model is compiled with a sparse categorical cross-entropy loss function and the Adam optimizer.
Output:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ embedding (Embedding) │ (None, 85, 100) │ 6,000 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm (LSTM) │ (None, 85, 256) │ 365,568 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout (Dropout) │ (None, 85, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_1 (LSTM) │ (None, 85, 256) │ 525,312 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_1 (Dropout) │ (None, 85, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_2 (LSTM) │ (None, 85, 512) │ 1,574,912 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_2 (Dropout) │ (None, 85, 512) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_3 (LSTM) │ (None, 256) │ 787,456 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_3 (Dropout) │ (None, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 60) │ 15,420 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 3,274,668 (12.49 MB)
Trainable params: 3,274,668 (12.49 MB)
Non-trainable params: 0 (0.00 B)
Output:
Epoch 1/5
1256/1256 ━━━━━━━━━━━━━━━━━━━━ 3215s 3s/step - loss: 2.9330
We will use any tune in dataset and store it in a text file. We will then preprocess it and convert it to numerical data which will be fed into the RNN. The generated numbers will be stored in a list which will be then converted back into words.
Note: The generated tune may have some inconsistencies in bar lines ie (|: or :|) which can be easily rectified manually. I used Chat GPT to save time.
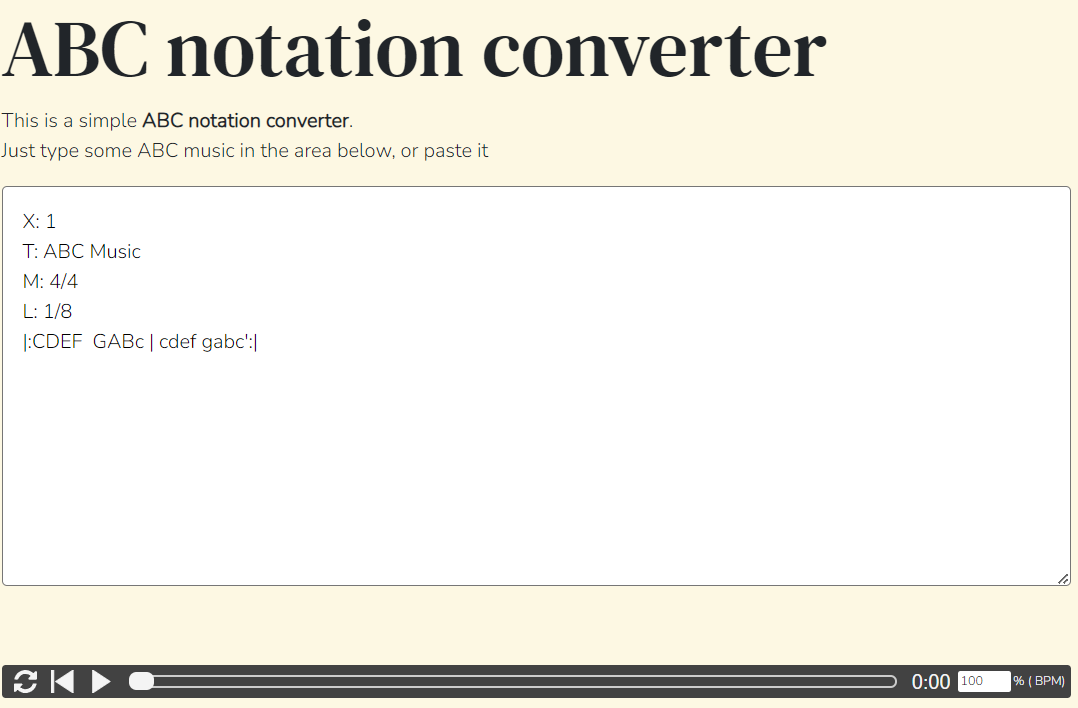
The music will be played and downloaded using this ABC Notation converter on web. Any website will work.
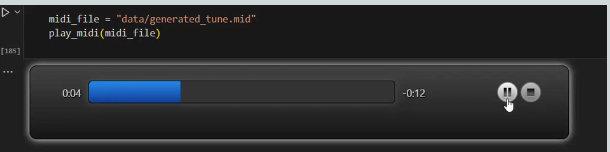
After pasting the generated ABC Notation we will download it by clicking on download button. Then we will play the music using music21 library.
Output:
You can check the generated music here.
The project demonstrates the potential of combining traditional music notation with modern machine learning techniques to create new musical compositions. The process, from data retrieval and preprocessing to model training and music generation, highlights how technology can be used to innovate in the field of music. While the generated music may require some manual adjustments, the overall approach showcases a powerful method for algorithmic composition and creative exploration in music.
{kind=link}
{kind=link}
{kind=link}
{kind=link}