 |
VOOZH | about |
|
VOOZH | about |
Self-attention mechanism enables each word or token in a sequence to focus on other relevant words or tokens within the same sequence, allowing for relationships between elements to be dynamic and context-dependent.
For example, in the sentence "The cat sat on the mat", the word "sat" has to notice "cat" to know who is sitting and notice "mat" in order to know where the action is taking place.
Self-Attention Mask is like a set of instructions for the model. It tells the model which words to pay attention to and which ones to skip over. Sometimes, there are words in a sentence that aren't important for the task at hand like extra padding words that are just there to fill space or future words that the model shouldn't look at yet.
The mask helps the model stay focused on the right words and ignore the ones that aren't useful. This way, the model can do its job more efficiently and accurately, without getting confused by unnecessary information.
Padding words are special tokens added to sequences in NLP tasks to make all sequences the same length. This is important for many machine learning models, including neural networks, which require consistent input lengths.
Padding tokens don't carry meaningful information, they are just placeholders to ensure uniform sequence length.
For example,
Sentence : "The horse ran quickly."
Padded Sentence : "The horse ran quickly [PAD]"
Here, "[PAD]" is the padding token that fills the space to make both sentences the same length.
1. Making Attention Scores:
2. Applying the Mask:
3. Adjusting Attention:
4. Generating Final Output:
Before applying the mask, the attention mechanism considers all words equally.
Token | The | cat | sat | on | the | mat |
|---|---|---|---|---|---|---|
The | 1.0 | 0.8 | 0.6 | 0.4 | 0.5 | 0.3 |
Cat | 0.8 | 1.0 | 0.9 | 0.4 | 0.5 | 0.2 |
Sat | 0.6 | 0.9 | 1.0 | 0.8 | 0.7 | 0.6 |
After applying a future word mask, the model cannot "see" future tokens:
Token | The | cat | sat | on | the | mat |
|---|---|---|---|---|---|---|
The | 1.0 | 0.8 | 0.6 | -∞ | -∞ | -∞ |
Cat | 0.8 | 1.0 | 0.9 | -∞ | -∞ | -∞ |
Sat | 0.6 | 0.9 | 1.0 | -∞ | -∞ | -∞ |
In this example, let's assume we are using PyTorch to implement a basic self-attention layer and apply a mask to prevent attention to future positions (in a causal or autoregressive setting).
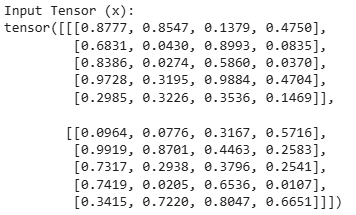
The first step is to create a random input tensor representing token embeddings. This tensor has dimensions (batch_size, seq_len, embedding_dim) where:
Output:
Next, we create a self-attention mask that controls how each token can attend to other tokens. In this case, we use a causal mask, which ensures that tokens cannot attend to future positions (i.e., tokens ahead of them in the sequence). This is commonly used in autoregressive models where the model must not look ahead in the sequence.
The mask is an upper triangular matrix (torch.tril) where:
Output:
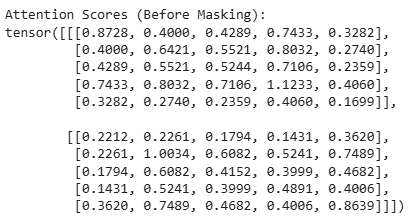
Now, we compute the attention scores, which represent the similarity between each pair of tokens. This is done by performing a dot product between the input tensor (x) and its transpose. The scores are then scaled by the square root of the embedding dimension (embedding_dim ** 0.5) to stabilize gradients during training.
Output:
In this step, we apply the mask to the attention scores. We use the mask to set the attention scores for masked positions (where the mask is 0) to a very large negative value (-1e9). This ensures that when we apply the softmax in the next step, the masked positions will have an attention weight of zero.
Output:
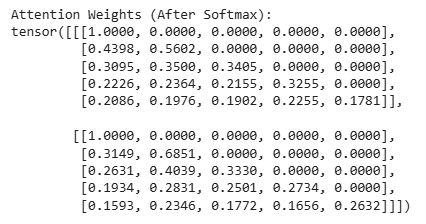
Explanation: Once the mask is applied, we perform a softmax operation on the attention scores to get the attention weights. This operation converts the scores into probabilities, ensuring that the sum of the attention weights for each token equals 1. The softmax is applied along the sequence dimension (dim=-1), so each token's attention distribution over all other tokens is computed.
Output:
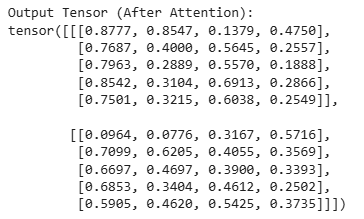
Finally, we compute the output of the self-attention mechanism by taking a weighted sum of the input tensor (x) based on the attention weights. This is done by performing a matrix multiplication between the attention weights and the input tensor.
Output:
Self-attention masks are essential for making Transformers efficient and context-aware. As NLP advances, newer masking techniques will further improve large-scale models, enabling better accuracy and faster computations in text and speech processing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}