How WordPiece Tokenization Addresses the Rare Words Problem in NLP
Last Updated : 23 Jul, 2025
One of the key challenges in Natural Language Processing is handling words that models have never seen before. Traditional methods often fail to address this effectively making them unsuitable for modern applications. There are several problems with existing methods:
Out-of-vocabulary(OOV) words (rare or new words) break model predictions completely
Character-level tokenization loses semantic meaning
Models must learn word formation from scratch which is inefficient
WordPiece tokenization offers a solution that has become the foundation of transformer models like BERT and GPT. It strikes the balance between vocabulary size and semantic preservation.
Vocabulary Explosion and Rare Words
Consider processing the sentence "The bioengineering startup developed unbreakable materials." A traditional word-level tokenizer would need separate entries for "bioengineering", "startup", "unbreakable" and "materials". If any of these words weren't in the training vocabulary, the model would fail.
Key challenges in traditional tokenization:
Vocabulary grows exponentially with text corpus size
Technical terms and proper nouns create endless edge cases
Memory requirements become prohibitive for large vocabularies
Model training becomes computationally expensive
WordPiece solves this by breaking words into meaningful subunits. Instead of treating "unbreakable" as a single unknown token, it breaks it down into recognizable pieces: ["un", "##break", "##able"]. The "##" prefix indicates that a token continues from the previous piece, preserving word boundaries and also enabling flexible decomposition.
This approach ensures that even completely new words can be understood through their constituent parts which results in improving model robustness and generalization.
How WordPiece Tokenization Works
The algorithm follows a data-driven approach to build its vocabulary. It starts with individual characters and gradually merges the most frequently occurring pairs until reaching a target vocabulary size.
Algorithm steps:
Initialize vocabulary with all individual characters
Count frequency of all adjacent symbol pairs in the corpus
Merge the most frequent pair into a single token
Update the corpus with the new merged token
Repeat until reaching desired vocabulary size (typically 30K-50K tokens)
During actual tokenization, WordPiece uses a greedy longest-match strategy. For each word, it finds the longest possible subword that exists in its vocabulary then marks it as a token and repeats for the remaining characters.
Tokenization process:
Start from the beginning of each word
Find the longest matching subword in vocabulary
Add it to the token list with appropriate prefix
Move to the next unprocessed characters
Continue until the entire word is processed
This statistical foundation ensures that common patterns naturally emerge as single tokens while rare combinations get broken into more familiar components.
Wordpiece Implementation
Let's implement basic WordPiece tokenization using the transformers library. This example focuses on core functionality without unnecessary complexity.
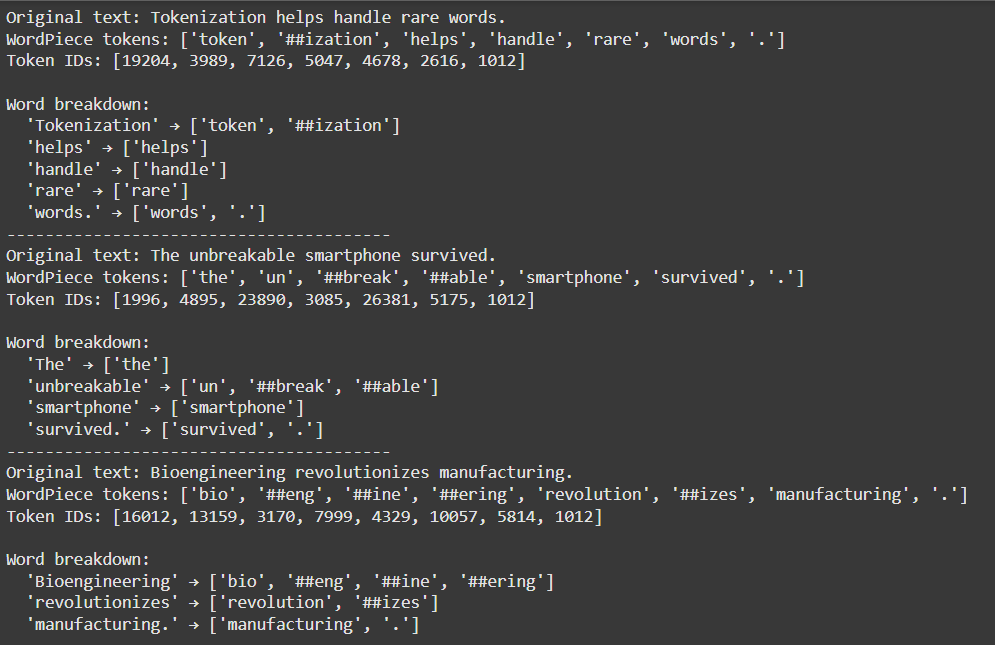
Imports BertTokenizer and loads the pre-trained bert-base-uncased model which applies WordPiece tokenization and lowercases input text.
Defines a function simple_tokenize(text) to show how BERT tokenizes input into subwords and maps them to token IDs.
Tokenizes the full sentence, prints the resulting WordPiece tokens and converts them into their corresponding vocabulary IDs.
Splits the input into individual words and shows how each word is broken down into subword tokens by BERT.
Tests the function on three sample sentences to illustrate handling of rare, compound and complex words, with clear separation between examples.
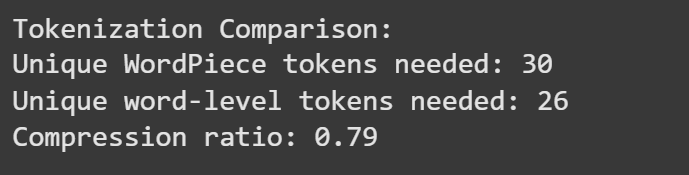
The compression ratio shows WordPiece's representational efficiency. While word-level tokenization might need 1000+ unique tokens for a technical corpus, WordPiece achieves the same coverage with 300-400 tokens.
Practical Limitations
WordPiece tokenization has limitations that we should understand before implementation.
1. Character handling issues:
Unknown Unicode characters map to [UNK] tokens
Information loss occurs with unsupported character sets
Emoji and special symbols may not tokenize intuitively
To resolve this ensure training data covers expected character ranges
2. Language-specific challenges:
Struggles with languages lacking clear word boundaries (Chinese, Japanese)
Morphologically rich languages may over-segment
Languages that form words by combining many smaller units often produce long token sequences during processing.
3. Vocabulary limitations:
Fixed vocabulary cannot adapt to new domains without retraining
Specialized terminology may produce many [UNK] tokens
Domain shift can significantly degrade performance
Medical/legal texts often require domain-specific vocabularies
WordPiece tokenization has enabled the success of modern transformer models by balancing vocabulary coverage with computational efficiency. Its approach ensures that language patterns emerge naturally while maintaining robustness against unknown words.

{kind=link}
{kind=link}
{kind=link}