 |
VOOZH | about |
|
VOOZH | about |
Latent Text Analysis (LTA) is a technique used to discover the hidden (latent) structures within a set of documents. This approach is instrumental in natural language processing (NLP) for identifying patterns, topics, and relationships in large text corpora. This article will explore using whole documents using the Isa Package in R programming language for Latent Text Analysis.
When performing Latent Text Analysis (LTA), treating the text as a whole document means that the analysis is done on the full text without breaking it down into smaller sub-components like paragraphs or sentences like research papers, customer feedback, Emails, News Articles, etc. This technique reduces the dimension of finding the underlying themes that are not usually visible.
LSA uses Singular Value Decomposition (SVD) for analysis of the term-document matrix. The document term is divided into three components or matrices:
A=UΣVT
where,
LTA can be used for many purposes, some of which are:
The lsa package in R provides tools for performing Latent Semantic Analysis. It allows users to create a latent semantic space and perform various analyses such as term associations, document similarities, and topic modeling. The package integrates seamlessly with the "tm" package in R.
In this article, we will be using a fictional dataset and perform LTA on it. This article will contain news article information on different topics.
In this step, we will create a fictional dataset and understand it before performing analysis on it.
Creating and Preprocessing the Corpus(a collection of words). The next step is to preprocess the text data by converting it to lowercase, removing punctuation, numbers, and stopwords, and stripping whitespace.
The corpus now consists of clean, preprocessed text data ready for analysis.
Now we will perform Exploratory Data Analysis (EDA) on our dataset.
We create a Term-Document Matrix (TDM) which represents the frequency of terms in each document.
Output:
Docs
Terms 1 2 3 4 5 6 7 8 9 10
downturn 1 0 0 0 0 0 0 0 0 0
experiencing 1 0 0 0 0 0 0 0 0 0
inflation 1 0 0 0 0 0 0 0 0 0
market 1 0 0 0 0 0 0 0 0 0
rates 1 0 0 0 0 0 0 0 0 0
rise 1 0 0 0 0 0 0 0 0 0
significant 1 0 0 0 0 0 0 0 0 0
stock 1 0 0 0 0 0 0 0 0 0
advances 0 1 0 0 0 0 0 0 0 0
artificial 0 1 0 0 0 1 0 0 0 0
industries 0 1 0 0 0 0 0 0 0 0
intelligence 0 1 0 0 0 1 0 0 0 0
revolutionizing 0 1 0 0 0 0 0 0 0 0
various 0 1 0 0 0 0 0 0 0 0
election 0 0 1 0 0 0 1 0 0 0
healthcare 0 0 1 0 0 0 0 0 0 0
hot 0 0 1 0 0 0 0 0 0 0
reform 0 0 1 0 0 0 0 0 0 0
topic 0 0 1 0 0 0 0 0 0 0
upcoming 0 0 1 0 0 0 0 0 0 0
developments 0 0 0 1 0 0 0 0 0 0
energy 0 0 0 1 0 0 0 0 0 1
new 0 0 0 1 0 0 0 0 0 0
promising 0 0 0 1 0 0 0 0 0 0
renewable 0 0 0 1 0 0 0 0 0 1
sustainability 0 0 0 1 0 0 0 0 0 0
technologies 0 0 0 1 0 0 0 0 0 0
economy 0 0 0 0 1 0 0 0 0 0
growth 0 0 0 0 1 0 0 0 0 0
increased 0 0 0 0 1 0 0 0 0 0
job 0 0 0 0 1 0 0 0 0 0
recovery 0 0 0 0 1 0 0 0 0 0
showing 0 0 0 0 1 0 0 0 0 0
signs 0 0 0 0 1 0 0 0 0 0
area 0 0 0 0 0 1 0 0 0 0
companies 0 0 0 0 0 1 0 0 0 0
continues 0 0 0 0 0 1 0 0 0 0
focus 0 0 0 0 0 1 0 0 0 0
key 0 0 0 0 0 1 0 0 0 0
tech 0 0 0 0 0 1 0 0 0 0
approaches 0 0 0 0 0 0 1 0 0 0
day 0 0 0 0 0 0 1 0 0 0
debates 0 0 0 0 0 0 1 0 0 0
heating 0 0 0 0 0 0 1 0 0 0
political 0 0 0 0 0 0 1 0 0 0
advancements 0 0 0 0 0 0 0 1 0 0
automotive 0 0 0 0 0 0 0 1 0 0
driving 0 0 0 0 0 0 0 1 0 0
forward 0 0 0 0 0 0 0 1 0 0
industry 0 0 0 0 0 0 0 1 0 0
technological 0 0 0 0 0 0 0 1 0 0
economic 0 0 0 0 0 0 0 0 1 0
horizon 0 0 0 0 0 0 0 0 1 0
indicators 0 0 0 0 0 0 0 0 1 0
may 0 0 0 0 0 0 0 0 1 0
recession 0 0 0 0 0 0 0 0 1 0
suggest 0 0 0 0 0 0 0 0 1 0
becoming 0 0 0 0 0 0 0 0 0 1
costeffective 0 0 0 0 0 0 0 0 0 1
sources 0 0 0 0 0 0 0 0 0 1
The TDM matrix shows the frequency of each term in each document.
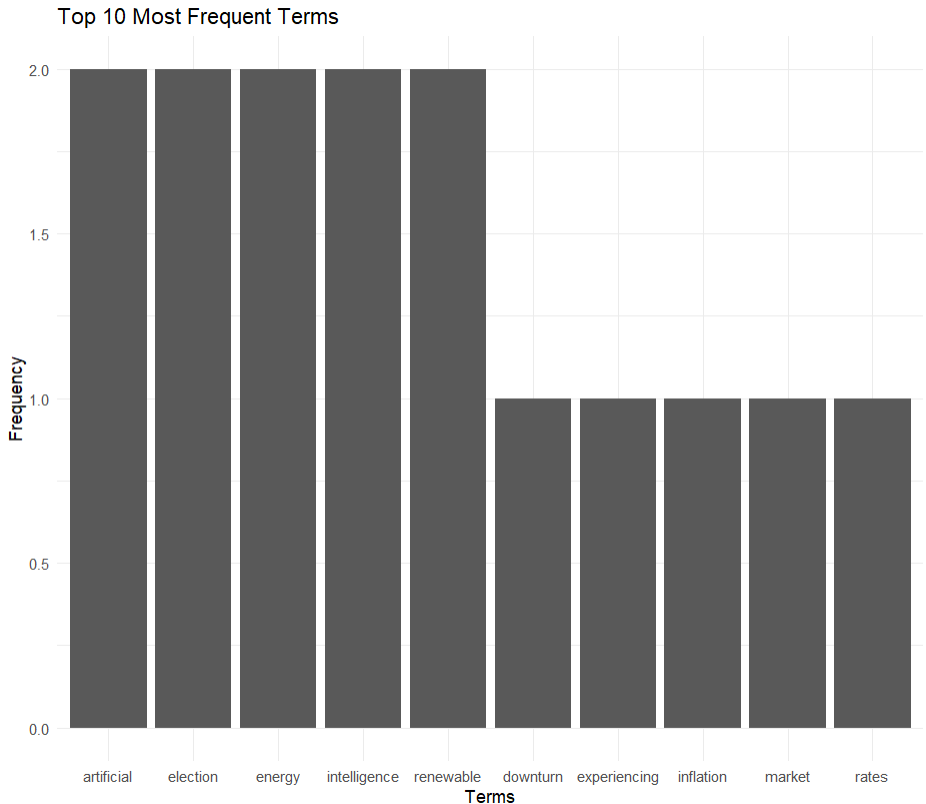
Lets plot the most frequent terms of our whole document to understand it better.
Output:
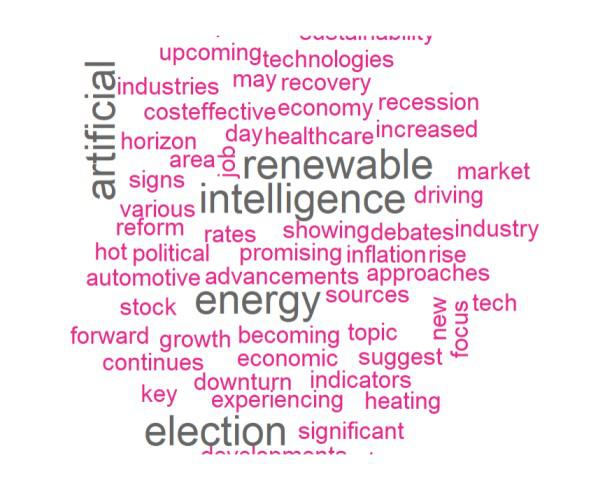
We visualize word frequencies using a word cloud to identify the most frequent terms in the corpus.
Output:
The word cloud highlights the most frequent words in the dataset, providing a quick visual summary of the corpus content.
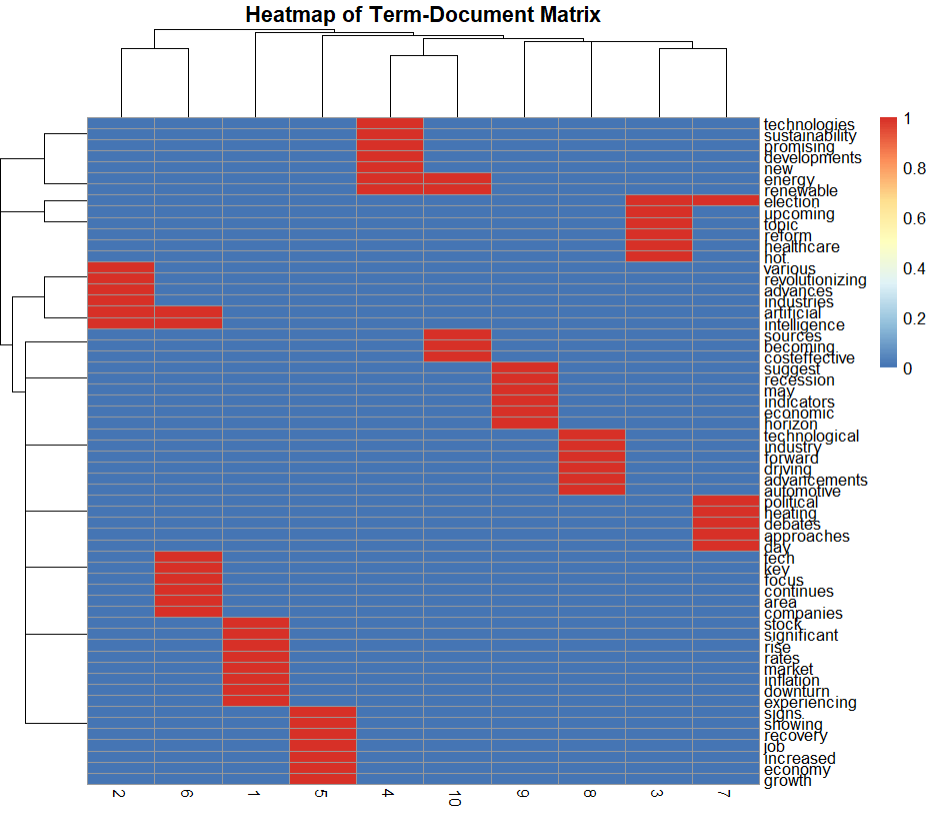
We plot a heatmap to show the distribution of terms across documents.
Output:
The heatmap displays the term frequencies across documents, with clustering indicating groups of similar terms and documents.
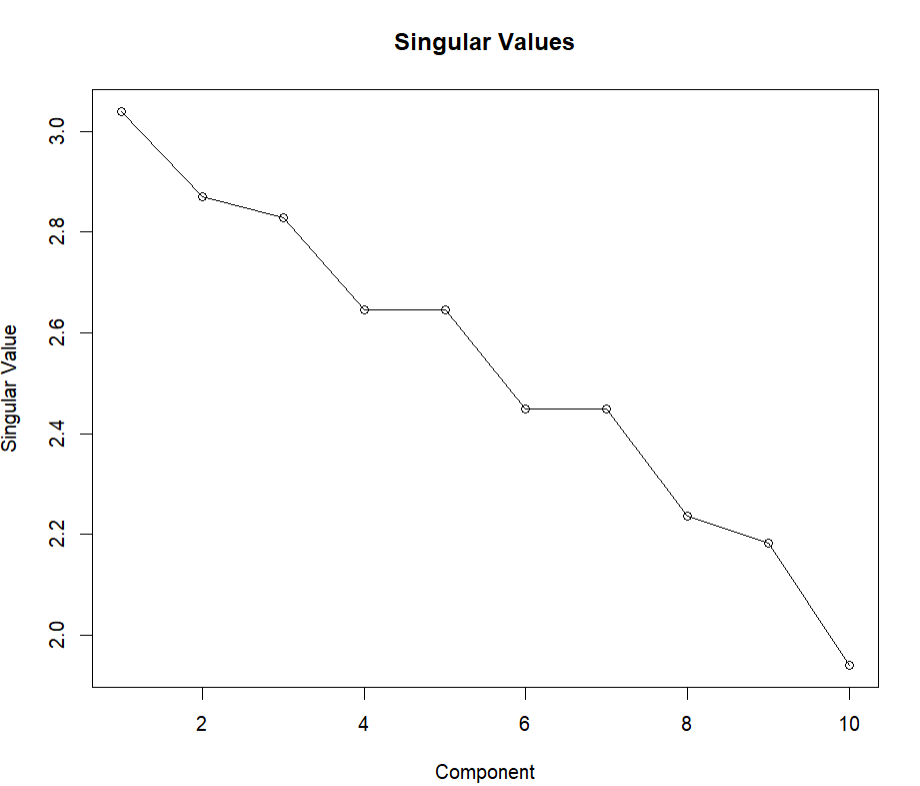
We perform Singular Value Decomposition (SVD) to identify the importance of each component.
Output:
We perform LSA on the TDM matrix to reduce its dimensionality and extract meaningful patterns. We extract the top and bottom terms for each LSA component to understand the main topics represented.
Output:
Component 1
Top terms: election hot topic upcoming healthcare
Bottom terms: new computing latest opened possibilities
Component 2
Top terms: artificial intelligence healthcare reform applications
Bottom terms: developments energy new promising renewable
This reveals the key terms for each topic.
In this article, we discussed how to use Isa package in R for Latent Text Analysis for a whole document. We used multiple graphs to visualize our data and processing. We also learnt how to use other packages to perform analysis over a news article to find sub topics and frequent words.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}