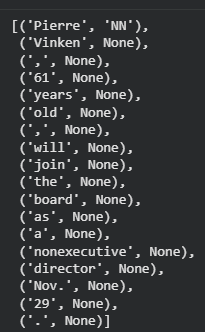
A unigram refers to a single token, such as hello, movie, or coding. A unigram tagger is a simple statistical model used for Part-of-Speech (POS) tagging in Natural Language Processing. It assigns a POS tag to each word independently of surrounding words, based solely on the word itself.
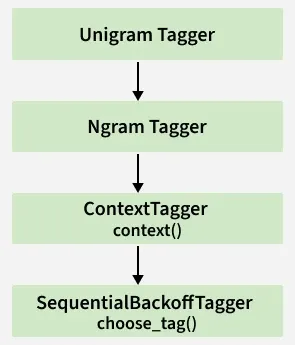
In NLTK, the UnigramTagger is implemented as a context-based tagger and inherits from NgramTagger and ContextTagger.
The context used by a UnigramTagger consists only of the single word (unigram).
it does not model linguistic context, such as neighboring words or previous POS tags.
Simplicity : A Unigram Tagger assigns Part-of-Speech (POS) tags based solely on the current word, ignoring surrounding context. Because of this simplicity, its applications are limited but important, primarily as foundational or supporting components in NLP systems.
Speed : Extremely fast due to no context window and simple dictionary lookup, useful when processing large corpora.
Baseline model : Baseline for comparison against modern taggers like (Bigram, Trigram and neural models).
Backoff Option : Used as a backoff option when advanced taggers fail due to its relative simplicity.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}