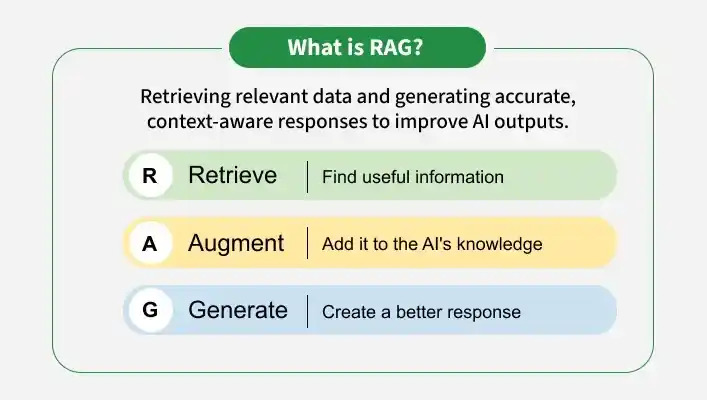
Retrieval-Augmented Generation (RAG) is an architecture that enhances LLMs by combining them with external knowledge sources, enabling access to up to date and domain specific information for more accurate and relevant responses while reducing hallucinations.
The retrieval component identifies relevant data to assist in generating accurate responses. Dense Passage Retrieval (DPR) is a common model that is used to perform retrieval.
Query Encoding: Converts the input query into a vector representing its semantic meaning.
Passage Encoding: Encodes documents into vectors and stores them for fast retrieval.
Retrieval: Compares the query vector with stored vectors to find the most relevant passages.
2. Generative Component
After retrieval, the relevant data is passed to the generative model (like BART or GPT), which combines it with the query to generate the final response.
FiD (Fusion-in-Decoder): Combines retrieved data during decoding, keeping retrieval and generation separate for more flexibility.
FiE (Fusion-in-Encoder): Merges query and retrieved data at the start, making it more efficient but less flexible.
FiD vs. FiE
Aspect
Fusion-in-Decoder(FiD)
Fusion-in-Encoder(FiE)
Fusion Point
Fusion occurs in the decoding phase.
Fusion happens at the encoding phase before decoding.
Process Separation
Retrieval and generation are kept separate.
Retrieval and generation are processed together.
Efficiency
Slower due to separate retrieval and generation steps.
Faster due to simultaneous process in encoder phase
Complexity
More Complex
Simpler
Performance
Higher-quality response
Quicker response generation
Working
RAG follows a structured workflow where a query is processed, relevant information is retrieved and a final response is generated using both retrieved data and model knowledge.
Query Processing: The input query is first pre-processed and prepared for further steps, ensuring it is in a suitable form for embedding.
Embedding Model: The query is passed through an embedding model that converts it into a vector capturing its semantic meaning.
Vector Database Retrieval: This vector is used to search a vector database to find documents that are most similar to the query.
Retrieved Contexts: The system retrieves the documents that are closest to the query. These documents are then forwarded to the generative model to help it craft a response.
LLM Response Generation: The LLM combines the original query with the retrieved context to generate a coherent and accurate response.
Response: The final response integrates both the model’s internal knowledge and the retrieved information, making it more relevant and up-to-date.
Implementation
This example demonstrates how RAG works by combining vector search with language models to generate accurate responses.
Step 1: Install Dependencies
We will install the required libraries and packages for our model,

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}