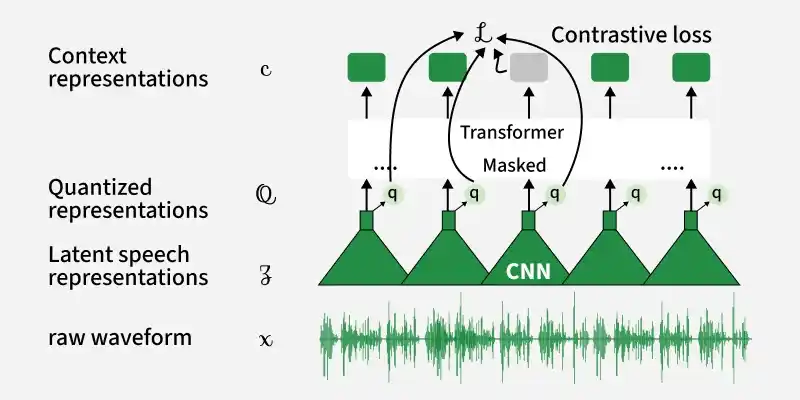
Wav2Vec2 is a self-supervised learning model designed for speech recognition. It learns meaningful representations directly from raw audio using large amounts of unlabeled data, and can later be fine-tuned for tasks such as transcription with minimal labeled data.
Learns speech patterns and features directly from raw audio
Builds a general understanding of spoken language that can be reused across tasks
Requires less labeled data due to self-supervised pre-training
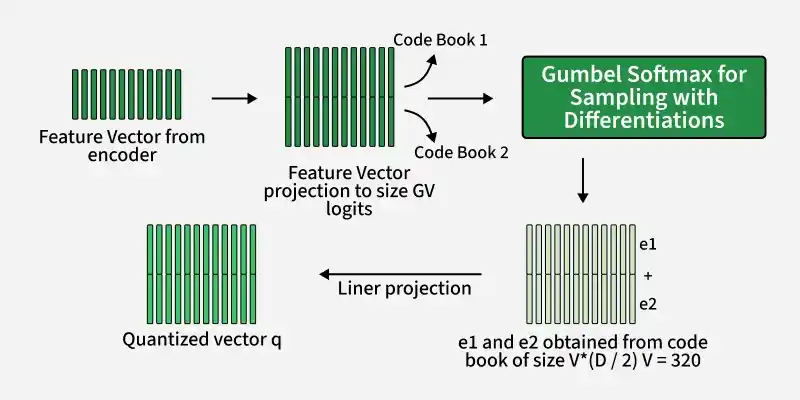
Represents audio as discretized vector embeddings (speech units) for efficient processing
The feature encoder is the first component of Wav2Vec2 that processes raw audio input. It takes the audio waveform and converts it into a sequence of meaningful features.
Takes raw audio as input
Uses convolution layers to extract important patterns from sound
Converts continuous audio into compact feature representations
Reduces the length of the audio sequence while preserving useful information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}