 |
VOOZH | about |
|
VOOZH | about |
Part of Speech (POS) tagging is the process of assigning a grammatical category to each word in a sentence based on its role in the context. These categories include noun, verb, adjective, adverb, preposition, and others. POS tagging helps computers understand the structure of language, making it easier for them to process and analyze text.
Example:
Sentence: “The cat is sitting on the mat.”POS tags:
- The → Determiner
- cat → Noun
- is → Verb
- sitting → Verb
- on → Preposition
- the → Determiner
- mat → Noun
POS tagging plays an important role in a wide range of Natural Language Processing (NLP) tasks. From text analysis and grammar checking to information retrieval, translation, and sentiment analysis, POS tags help systems understand sentence structure and word meaning in context. They are also important in more advanced processes like parsing and semantic analysis, acting as a foundational step for deeper language understanding.
Over the years, several approaches have evolved to perform POS tagging. These methods mainly fall into two broad categories which are Rule-Based and Stochastic or Probabilistic. More recently, Deep Learning has also made its mark in this area.
Rule-based systems rely on a set of manually written grammar rules and contextual cues. These rules help decide the correct tag for each word. A classic example might be If an unknown word ends in ‘ing’ and follows a verb, tag it as a verb. These models typically use dictionaries of words with possible tags and a set of disambiguation rules based on surrounding words which are also called context frames. While accurate in structured settings, rule-based taggers can struggle with exceptions and the dynamic nature of real-world language.
This is a hybrid between rule-based and statistical approaches. Initially, each word is tagged with a most-likely guess. Then, transformation rules learned from training data are applied iteratively to correct the tags based on context. The famous Brill Tagger is based on this method. It is an elegant balance between human intuition in the form of rules and machine learning in the form of pattern discovery.
These models use statistics derived from large annotated corpora. The simplest method assigns each word the most frequently occurring tag from training data. However, this can produce grammatically incorrect tag sequences. To fix this, probabilistic models consider tag sequences rather than individual words. A popular method is the Hidden Markov Model (HMM), which calculates the most probable sequence of tags for a sentence by considering both the word-tag likelihood and the likelihood of tag transitions. These models provide a good mix of accuracy and flexibility.
With the rise of deep learning, models like BiLSTM which stands for Bidirectional Long Short-Term Memory and Meta-BiLSTM have set new benchmarks in POS tagging accuracy. These models automatically learn complex patterns from large datasets and can capture long-distance dependencies in language which is something rule-based and HMM models often miss.
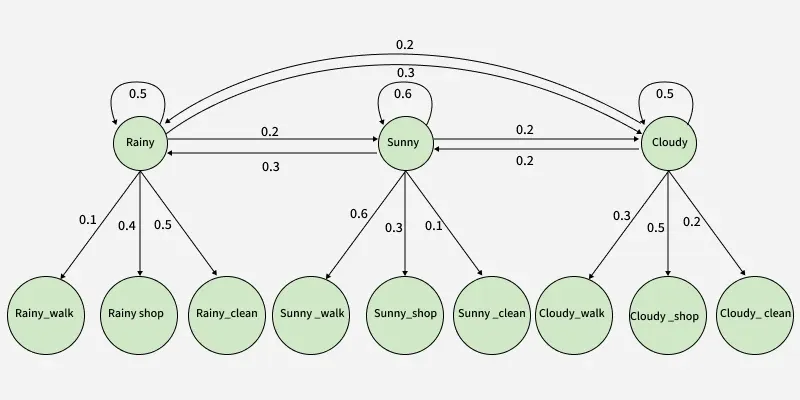
A Hidden Markov Model is a statistical model used to understand systems where the actual states are not directly visible, but we can see outcomes that depend on those hidden states. In simple terms, HMM helps us figure out what is going on behind the scenes based on what we observe.
Let’s understand this with an example. Suppose you are trying to guess the weather each day, but you can't look outside. Instead, you watch what people do. If someone is walking, shopping, or cleaning, these actions give you clues about what the weather might be like.
This HMM model helps determine the most likely sequence of hidden weather states based on a sequence of observed activities.
These represent the probability of the system remaining in the same weather state:
These indicate the likelihood of transitioning from one weather state to another:
These describe the probability of performing an activity given a specific weather condition:
Hidden Markov Models, or HMMs, are built around a few key ideas that help describe systems where we can observe some things, but not everything directly.
We start by creating a small dataset of sentences. Each word is labeled with its correct part of speech.
This step builds the statistical foundation for the HMM. The model counts how likely:
Then it converts these counts into probabilities, which are used by the Viterbi algorithm later.
This is the Viterbi algorithm. It uses the probabilities from Step 2 to figure out the most likely sequence of tags for a given sentence. At each word, it checks all possible tags and selects the path that has the highest probability so far. It continues this process until the end of the sentence and returns the best sequence of POS tags.
Now we test the HMM model on a new sentence. Even though the model hasn’t seen this exact sentence before, it will use what it learned to predict the most likely part of speech tags for each word.
Output
Sentence: ['a', 'cat', 'barked']
Predicted Tags: ['DET', 'NOUN', 'VERB']
You can download source code from here.
{kind=link}
{kind=link}