Bidirectional Long Short-Term Memory (BiLSTM) is an extension of LSTM that processes sequences in both forward and backward directions, allowing the model to capture both past and future context.
Processes sequences in forward and backward directions
Captures both past and future contextual information
More effective than standard LSTMs for sequence understanding
Commonly used in NLP, speech processing and sequence analysis
Understanding Bidirectional LSTM (BiLSTM)
A Bidirectional LSTM (BiLSTM) consists of two separate LSTM layers:
Forward LSTM: Processes the sequence from start to end
Backward LSTM: Processes the sequence from end to start
The outputs of both LSTMs are then combined to form the final output. Mathematically, the final output at time t is computed as:
Where:
: Final probability vector of the network.
: Probability vector from the forward LSTM network.
: Probability vector from the backward LSTM network.
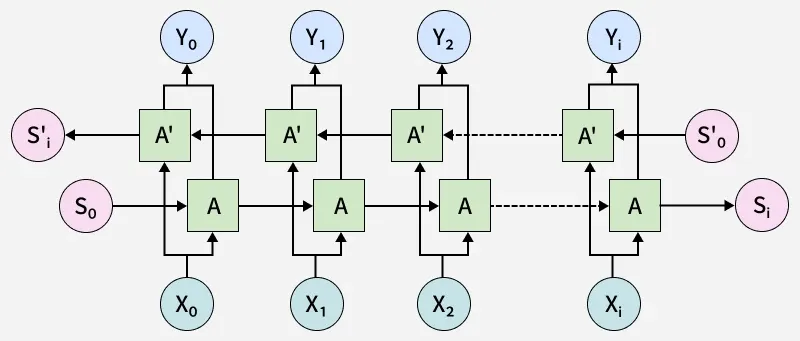
The following diagram represents the BiLSTM layer:
We will load IMDB dataset from tensorflow which contains 25,000 labeled movie reviews for training and testing. Shuffling ensures that the model does not learn patterns based on the order of reviews.
Printing a sample review and its label from the training set.
Output:
Text: b "Having seen men Behind the Sun ... 1 as a treatment of the subject)." Label: 0
3. Performing Text Vectorization
We will first perform text vectorization and let the encoder map all the words in the training dataset to a token. We can also see in the example below how we can encode and decode the sample review into a vector of integers.
vectorize_layer : tokenizes and normalizes the text. It converts words into numeric values for the neural network to process easily.
4. Defining Model Architecture (BiLSTM Layers)
The model uses BiLSTM layers for sentiment analysis by processing text sequences in both forward and backward directions.
TextVectorization converts text into token indices
Embedding maps words into trainable 32-dimensional vectors
First Bidirectional(LSTM(32)) captures sequence context and returns sequences
Dropout(0.4) reduces overfitting
Second Bidirectional(LSTM(16)) refines learned features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}