Sentiment Analysis is a Natural Language Processing (NLP) technique used to determine the emotional tone behind text. In this article, we will explore how sentiment analysis on IMDB movie reviews to help us classify them as positive or negative.
IMDB movie reviews dataset is a common benchmark dataset for binary sentiment classification. Each review in the dataset is labeled as either positive or negative. You can download the dataset from kaggle which includes:
Size: 50,000 reviews (25,000 for training, 25,000 for testing)
Label Type: Binary (positive = 1, negative = 0)
Steps to Perform Sentiment Analysis
Below are the step by step procedure to do sentiment analysis in python:
Step 1: Install Necessary Libraries
Install required Python libraries:
Pandas: for managing data efficiently using data frames.
NumPy: for powerful array operations and numerical tasks.
Matplotlib: for creating visualizations to gain insights from the data.
Dataset is in CSV format with columns review and sentiment. Use pandas to read the CSV file and inspect the structure, missing values and basic statistics.
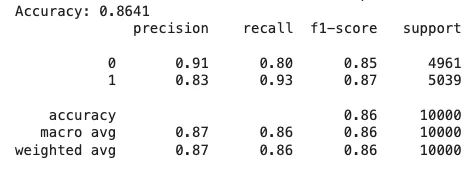
We can see that our model is working fine with 86.41% accuracy and we can further fine tune the model to increase its accuracy.
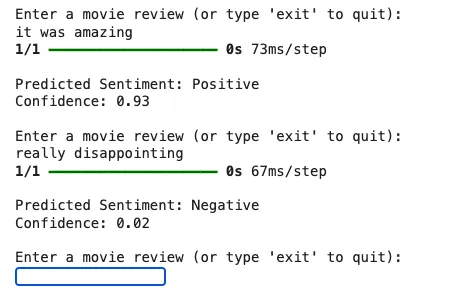
Step 10: Making predictions
This loop takes user input a movie review, cleans and tokenizes it
Then uses the trained LSTM model to predict whether the sentiment is positive or negative and displays the result. It runs until the user types 'exit'.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}