 |
VOOZH | about |
|
VOOZH | about |
In Natural Language Processing, evaluating generated text is essential to understand how well a model performs. Metrics such as BLEU and ROUGE are commonly used to compare machine-generated output with human-written reference text. These metrics quantify how closely the generated content matches the expected result in terms of accuracy and relevance.
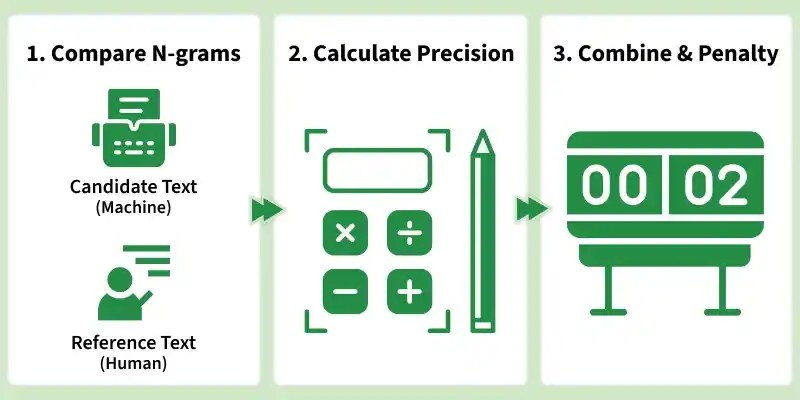
The BLEU (Bilingual Evaluation Understudy) score is a metric mainly used to evaluate machine translation systems. It measures how closely a machine-generated translation matches one or more human-written reference translations. The basic idea is that the more similar the candidate text is to the reference text, the better the translation quality.
This metric works by:
BLEU is based on modified n gram precision combined with a brevity penalty. First, the modified n gram precision for n grams is calculated as:
To prevent very short translations from receiving high precision scores, BLEU applies a brevity penalty (BP):
Where is the candidate length and is the reference length.
The final BLEU score combines the geometric mean of n gram precisions with the brevity penalty:
Here, are weights (usually equal) and represents n gram precision.
The ROUGE (Recall Oriented Understudy for Gisting Evaluation) score is mainly used to evaluate text summarization and other text generation tasks. It measures how much of the important information from the reference text is captured in the generated output. The final ROUGE score ranges from 0 to 1, where higher values indicate better content coverage and similarity to the reference text.
Unlike BLEU, which focuses more on precision, ROUGE emphasizes recall, meaning it checks how much relevant content is covered.
ROUGE works through different variants:
ROUGE focuses on recall rather than precision. For ROUGE N, the formula is:
ROUGE-L is based on the Longest Common Subsequence (LCS). Its recall version is:
ROUGE-S is based on skip bigrams, which are pairs of words that appear in the same order in a sentence, but not necessarily consecutively. This allows the metric to capture flexible word ordering while preserving sequence structure. The recall-based ROUGE-S formula is:
Both BLEU and ROUGE are automated evaluation metrics, but they measure text quality from different perspectives. The comparison below highlights their primary differences in focus, usage and evaluation strategy.
Aspect | BLEU | ROUGE |
|---|---|---|
Main Focus | Precision (how much generated text matches reference) | Recall (how much reference content is covered) |
Primary Use Case | Machine Translation | Text Summarization |
Matching Method | n gram overlap with precision calculation | n gram, LCS and skip bigram overlap with recall emphasis |
Length Handling | Uses brevity penalty for short outputs | No strict brevity penalty mechanism |
Score Range | 0 to 1 (higher is better) | 0 to 1 (higher is better) |
In this section, we evaluate the output of a real pretrained language model using BLEU and ROUGE. Instead of comparing dummy strings, we generate text from a model and measure how closely it matches a human written reference.
Run the following command in your command prompt
pip install transformers torch nltk rouge-score
This code loads the FLAN-T5 base model for sequence to sequence text generation. The tokenizer converts text into model ready tokens and the model loads its pretrained weights to generate outputs for evaluation.
Output:
This code generates text from the pretrained model using a given prompt.
Output:
Generated Text: Machine learning is a technique for detecting patterns in data.
This code prepares the human written reference and the model generated output for evaluation.
This code calculates the BLEU score between the reference text and the model generated output.
Output:
BLEU Score: 0.124
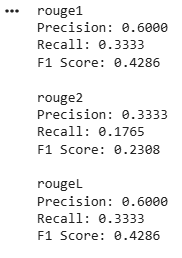
This code evaluates the generated text using ROUGE metrics.
Output:
You can download the full code from here
Although BLEU and ROUGE are widely used for automatic evaluation, they have inherent limitations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}