 |
VOOZH | about |
|
VOOZH | about |
Word embeddings have revolutionized the field of natural language processing (NLP) by enabling machines to understand the meaning and context of words. CBOW (Continuous Bag of Words) and Skip-Gram are two foundational architectures in Word2Vec for learning word embeddings. Both aim to capture semantic and syntactic relationships between words but differ in their approach, performance, and use cases.
Word Embeddings are essential in NLP as they convert text into numerical representations, enabling machines to understand and analyze human language. Popular approaches include Word2Vec, GloVe, and FastText. Word2Vec, developed by Mikolov and his team at Google, introduced the Continuous Bag of Words (CBOW) and Skip-Gram models, which significantly advanced text processing. CBOW predicts a target word from its context, while Skip-Gram predicts context words from a target word. These models are valued for their simplicity, computational efficiency, and ability to produce high-quality embeddings, making them foundational in modern NLP.
Continuous Bag of Words (CBOW) is a neural network model used for natural language processing tasks, primarily for word embedding. It belongs to the family of neural network architectures called Word2Vec, which aims to represent words in a continuous vector space.
In CBOW, the model predicts the current word based on the context of surrounding words. CBOW predicts the target word from its context. The architecture typically consists of an input layer, a hidden layer, and an output layer.
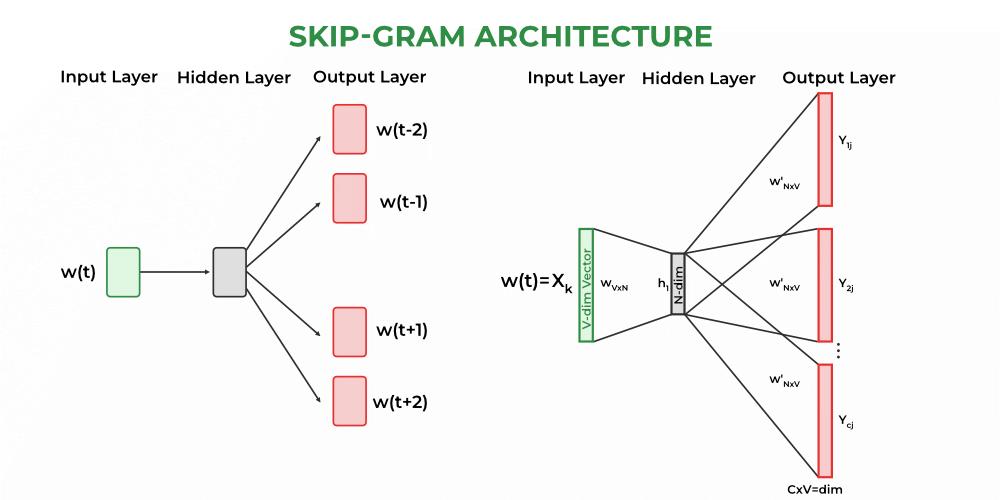
The Skip-Gram model is another neural network architecture within the Word2Vec framework for generating word embeddings. Unlike Continuous Bag of Words (CBOW), Skip-Gram predicts context words given a target word. It's designed to learn the representation of a word by predicting the surrounding words in its context.
["India", "wins", "next"] to predict the target word "world"."India" is the target word, Skip-Gram tries to predict its context words: ["wins", "next", "world"].Sentence:
["India", "wins", "next", "world", "cup"]CBOW Training Example
- Context:
["India", "wins", "next"]→ Target:"world"Skip-Gram Training Example
- Target:
"India"→ Context:["wins", "next", "world"]- Target:
"wins"→ Context:["India", "next", "world"]- Target:
"next"→ Context:["wins", "world", "cup"]
Aspect | CBOW (Continuous Bag of Words) | Skip-Gram |
|---|---|---|
Concept | Predicts a target word based on context words. | Predicts context words given a target word. |
Context Window | Typically smaller (2-5 words) | Can handle larger windows (5-20 words) |
Training Process | Minimizes cross-entropy loss to predict the target word. | Maximizes the likelihood of context words around a target word using techniques like negative sampling or hierarchical softmax. |
Training Speed | Faster (single prediction per context window) | Slower (multiple predictions per target word) |
Performance | Better for frequent words, syntactic relationship | Better for rare words, semantic relationships. |
Overfitting | Can overfit frequent words | Less prone to overfitting frequent words |
Model Size | Smaller | Larger |
Data Requirements | Needs less data | Needs more data, works well with large datasets |
Use Cases | Suitable for tasks requiring speed over detailed word representations, like text classification and sentiment analysis. | Ideal for tasks needing high-quality embeddings and detailed semantic relationships, such as word similarity tasks, named entity recognition, and machine translation. |
The code uses the Gensim library to train Word2Vec models on a sample sentence. Gensim is a Python library for efficient topic modeling and creating word embeddings from large text data.
Output
Below is the code where it creates two models:
sg=0): Predicts a target word based on its surrounding context words. For example, given the context ["wins", "next", "world"], it tries to predict "India".sg=1): Predicts the context words given a target word. For example, given the target word "India", it tries to predict its surrounding words like "wins", "next", and "world".Output
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}