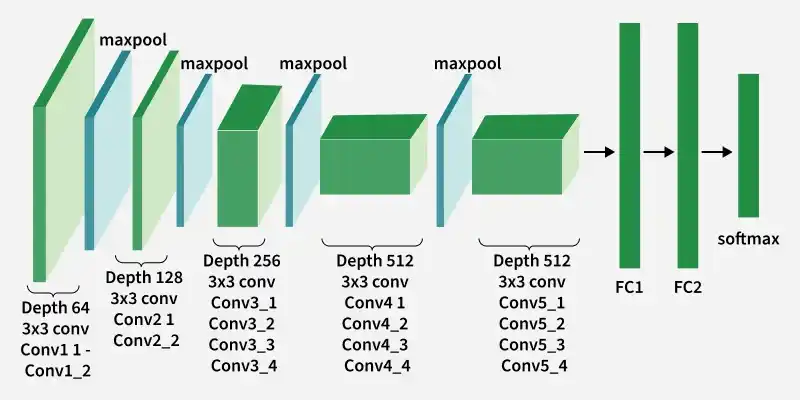
VGG-19 is a deep convolutional neural network with 19 weight layers, comprising 16 convolutional layers and 3 fully connected layers. The architecture follows a straightforward and repetitive pattern, making it easier to understand and implement. Key components of the VGG-19 architecture are:
Convolutional Layers: 3x3 filters with a stride of 1 and padding of 1 to preserve spatial resolution.
Activation Function: ReLU (Rectified Linear Unit) applied after each convolutional layer to introduce non-linearity.
Pooling Layers: Max pooling with a 2x2 filter and a stride of 2 to reduce the spatial dimensions.
Fully Connected Layers: Three fully connected layers at the end of the network for classification.
Softmax Layer: Final layer for outputting class probabilities.
Detailed Layer-by-Layer Architecture of VGG-Net 19
VGG-19 consists of 5 convolutional blocks followed by 3 fully connected layers. The model follows a simple and repetitive design where convolutional layers extract features, pooling layers reduce spatial dimensions, and fully connected layers perform classification.
FC3: 1000 neurons with Softmax activation for classification
As the network gets deeper, the number of filters increases from 64 to 512, enabling the model to learn more complex image features while pooling layers gradually reduce feature map size.
Architectural Design Principles
Uniform convolution filters: Uses consistent 3×3 filters across all layers for simplicity and uniformity.
Deep architecture: Increased depth helps learn complex and hierarchical features.
ReLU activation: Adds non-linearity, enabling the model to learn complex patterns.
Max pooling: Reduces spatial dimensions while retaining important features.
Fully connected layers: Combine extracted features for final classification.

{kind=link}
{kind=link}