 |
VOOZH | about |
|
VOOZH | about |
Retrieval Augmented Generation (RAG) is LLM framework that combines information retrieval and text generation to produce more accurate, factual and context rich responses. Evaluation metrics help check if the system retrieves relevant information, gives accurate answers and meets performance goals while also guiding improvements and model comparisons.
Evaluating a RAG system means checking how well it retrieves and generates accurate, relevant and grounded responses.
1. Set Goals: Define what matters most—accuracy, relevance, fluency or groundedness.
2. Pick Metrics:
3. Automate: Use tools like NLTK, ROUGE-score, BERTScore or Textstat for quick evaluation.
4. Add Human Review: Rate responses for clarity, accuracy and informativeness.
5. Analyze Results: Visualize performance, compare models and find weak spots.
6. Iterate: Refine retrieval and generation steps to improve factuality and coherence.
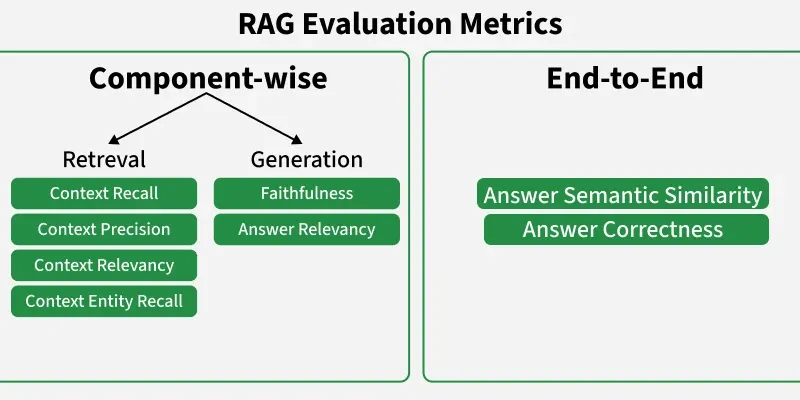
Some of the types of evaluation metrics are:
Some of the retrieval level metrices are Precision, Recall and F1-Score.
1. Precision: Portion of retrieved documents that are actually relevant.
2. Recall: Portion of relevant documents that were successfully retrieved.
3 F1-Score: Harmonic mean of precision and recall, balancing both.
Output:
Precision: 1.0, Recall: 0.6666666666666666, F1-Score: 0.8
4. Hit Rate: Shows how often retrieved answers exactly match the expected ones, higher is better.
Output:
Hit Rate: 0.5
5. Mean Reciprocal Rank (MRR): Measures how quickly the correct answer appears in the ranked results, higher is better.
Output:
MRR: 0.5
6. Mean Average Precision (MAP): Evaluates ranking quality across multiple queries.
Output:
MAP: 0.25
7. Normalized Discounted Cumulative Gain (nDCG): Rewards highly relevant documents appearing earlier in results.
Output:
nDCG@5: 0.3065735963827292
8. Recall@k and Precision@k: Check relevance within the top k retrieved items.
Output:
{'Recall@2': np.float64(0.25), 'Precision@2': np.float64(0.25)}
9. Similarity Measures (Cosine, BM25): Quantify how closely retrieved documents match the query.
Here we have illustrated cosine similarity.
Output:
Cosine Similarity: 0.24755053441657565
Some of the generation level metrices are:
1. BLEU, ROUGE, METEOR, BERTScore: Compare generated text with reference answers for similarity.
Here we have illustrated BLEU.
Output:
{'BLEU': np.float64(0.3939917666748808)}
2. Perplexity: Measures how well the model predicts the next word, lower perplexity is better.
Output:
Perplexity: 901.9484596252441
3. Factual Consistency: Checks if generated content aligns with retrieved information.
Output:
Factual Consistency: 0.5714285714285714
4. Fluency and Readability: Assesses how natural and easy to understand the text is.
Output:
{'Average Readability (Flesch)': np.float64(55.2089285714286), 'Average Fluency (words/sentence)': np.float64(7.5)}
5. Diversity and Novelty: Evaluates variety and originality in generated responses.
Output:
{'Distinct-Unigram': 0.8666666666666667, 'Distinct-Bigram': 1.0, 'Novelty': np.float64(0.9166666666666667)}
End to end evaluation looks at the overall performance of a RAG system considering both retrieval and generation together.
1. Answer Relevance and Context Utilization: Checks if the system’s answers address the user’s query and effectively use the retrieved information.
Output:
{'Answer Relevance': np.float64(0.6458333333333333), 'Context Utilization': np.float64(0.35416666666666663)}
2. Groundedness: Measures whether the generated text is supported by the retrieved sources reducing the risk of hallucinations.
Output:
Groundedness: 0.6666666666666667
3. Hallucination Rate: Tracks how often the system produces information that is incorrect or not backed by sources.
Output:
Hallucination Rate: 0.4875
4. Response Coherence and Readability: Ensures the generated answers are clear, logically structured and easy to understand.
Output:
{'Average Coherence (words/sentence)': np.float64(6.5), 'Average Readability (Flesch)': np.float64(28.20704545454545)}
5. Relevancy Score: Measures how well the system’s output matches the user’s query intent.
Output:
Relevancy Score: 0.3222222222222222
Human evaluation assesses the quality and usefulness of a RAG system’s responses from a real user perspective.
Criteria for Human Evaluation in RAG Systems:
Methods of Human Evaluation in RAG Systems:
Advanced and combined evaluation methods to get a more accurate performance are:
Comparison table of different RAG evaluation metrics:
Metric Type | Examples | Strengths | Weaknesses |
|---|---|---|---|
Retrieval Metrics | Hit Rate, MRR, Precision, Recall, nDCG | Simple, interpretable, directly measures relevance and ranking quality | Don’t evaluate answer quality, fluency or coherence |
Generation Metrics | BLEU, ROUGE, METEOR, BERTScore, Perplexity | Quantitative, widely used, easy to compute | May miss semantic meaning, context or factual correctness |
End-to-End Metrics | Answer Relevance, Groundedness, Hallucination Rate, Coherence | Holistic evaluation of system, includes factual grounding | Harder to compute automatically, may require human evaluation |
Human Evaluation | Rating scales, Pairwise comparison, Expert review | Captures nuance, context, readability and factual correctness | Time consuming, subjective, not easily scalable |
Some of the challenges faced during evaluating RAG Systems are:
We can follow these best practices to get reliable and meaningful results when evaluating RAG systems:
{kind=link}
{kind=link}
{kind=link}