 |
VOOZH | about |
|
VOOZH | about |
The Convolutional Vision Transformer (CvT) is a state of the art deep learning architecture that combines the strengths of convolutional neural networks (CNNs) and vision transformers (ViTs) to efficiently process visual data for tasks such as image classification, object detection and beyond.
CNNs have long been celebrated for their prowess in capturing local, shift-invariant features through convolutional kernels, supporting models like ResNet in achieving remarkable results on image benchmarks. Traditional Vision Transformers (ViT), on the other hand, excel at modeling long-range dependencies and global context via self-attention, but can be computationally expensive and may lack inductive bias for local patterns, sometimes struggling with efficient scaling and generalization when trained from scratch on limited data.
CvT aims to bridge these gaps merging convolution’s efficiency and locality with the flexibility and power of transformers.
CvT presents two key architectural modifications to the standard ViT design:
The Convolutional Vision Transformer (CvT) architecture integrates the strengths of convolutional neural networks (CNNs) and Vision Transformers (ViTs) to enhance visual recognition tasks. The pipeline begins with the input image being processed through a hierarchical, multi-stage structure. At each stage, the image or feature map is first passed through a convolutional token embedding layer, where overlapping convolutions and layer normalization are applied to efficiently reduce spatial resolution while increasing feature richness mirroring CNN behavior and capturing important local information.
Unlike traditional Transformers, CvT does not add explicit positional embeddings, instead relying on convolutional operations to capture spatial relationships. Each stage then utilizes stacks of Convolutional Transformer Blocks, which apply depth-wise separable convolutions for generating queries, keys and values providing improved spatial modeling compared to standard linear projections used in ViT. The classification token, introduced only at the final stage, aggregates the learned information, after which a fully connected MLP head predicts the output class.
CvT builds a multi-stage, hierarchical transformer and CNN progress from local to global features through repeated pooling and convolution:
Several CvT model variants exist, tuning the number/width of stages and blocks:
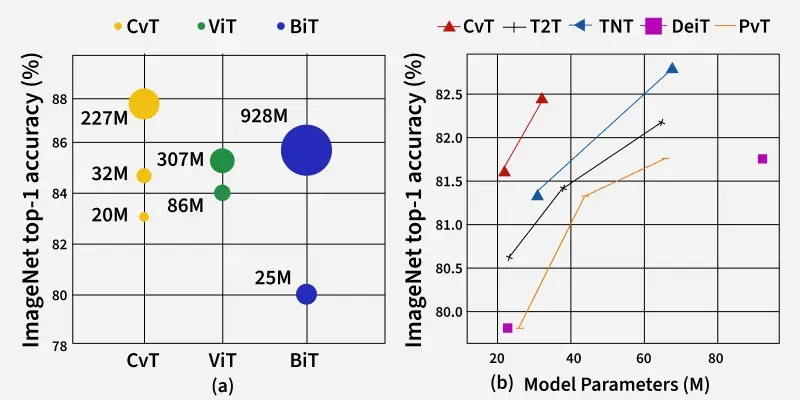
1. State-of-the-art results on ImageNet and other large-scale datasets, with:
2. Versatile backbone for classification, detection, segmentation and even specialized applications like galaxy morphology classification and steganography
3. Key properties brought by convolutional integration:
| Aspect | CNN | Vision Transformer (ViT) | CvT |
|---|---|---|---|
Local Inductive Bias | Strong | Weak | Strong (via convolutions) |
Hierarchical Structure | Yes | No (unless added) | Yes |
Positional Encoding | No | Required | Not required |
Attention Mechanism | None | Global Self-Attention | Convolutional Self-Attention |
Efficiency on High-Res | High | Low | High |
{kind=link}
{kind=link}