 |
VOOZH | about |
|
VOOZH | about |
Sentiment analysis is a NLP task used to determine the sentiment behind textual data. In context of product reviews it helps in understanding whether the feedback given by customers is positive, negative or neutral. It helps businesses gain valuable insights about customer experiences, product quality and brand perception. It helps in improving product quality and refining customer service strategies.
In this article, we will explore how to apply machine learning techniques to perform sentiment analysis on Flipkart reviews.
We will be using libraries like Pandas, Scikit-learn, NLTK, Matplotlib, Wordcloud and Seaborn for this. You can download the dataset by clicking this link.
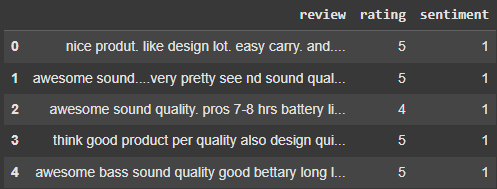
Output:
The next step is preprocessing the data which involves cleaning the review text and preparing the sentiment labels. We'll start by converting the reviews to lowercase and removing stopwords to make text more manageable. Then we will convert ratings (from 1 to 5) into binary sentiment labels like 1 for positive reviews (ratings 4 and 5) and 0 for negative reviews (ratings 3 and below).
Before we proceed with model making it's important to explore the dataset. We can visualize the distribution of sentiment labels and analyze the frequency of words in positive reviews.
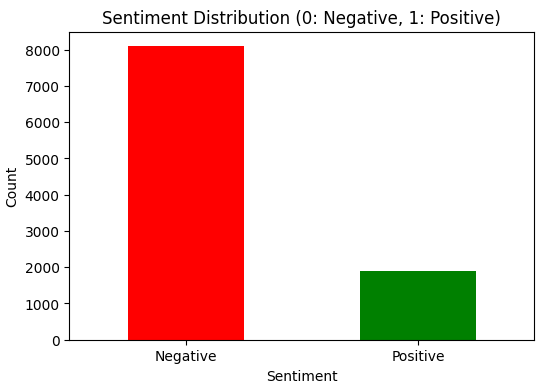
To understand the overall sentiment distribution, we will use a bar plot to visualize the counts of positive and negative reviews.
Output:
Next, we'll create a Wordcloud to visualize the most frequent words in positive reviews. This can help us understand the common themes in customer feedback.
Output:
Machine learning models require numerical input so we need to convert the textual reviews into numerical vectors. We will use TF-IDF (Term Frequency-Inverse Document Frequency) which helps converting these texts into vectors.
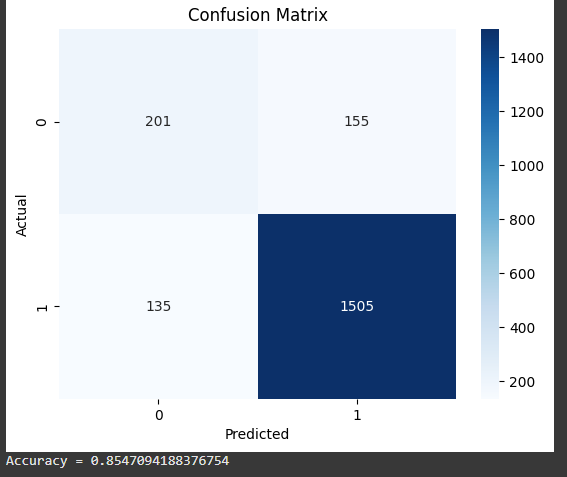
Now that the data is prepared we can split it into training and testing sets where 80% data is used for training and rest is used for testing. We will train a Decision Tree Classifier on the training data and evaluate its performance on the test data. We will also measure the model's accuracy and generate a confusion matrix to analyze the predictions.
Output:
We are able to classify reviews as positive or negative with an accuracy of approximately 86% which is great for a machine learning model but we can further fine tune this model to get better accuracy for more complex task. With this businesses can gain valuable insights into customer satisfaction and make data-driven decisions to improve their products and services.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}