 |
VOOZH | about |
|
VOOZH | about |
Stacked RNNs refer to a special kind of RNNs that have multiple recurrent layers on top of one layer. Stacked RNNs are also called Deep RNNs for that reason. In this article, we will load the IMDB dataset and make multiple layers of SimpleRNN (stacked SimpleRNN) as an example of Stacked RNN.
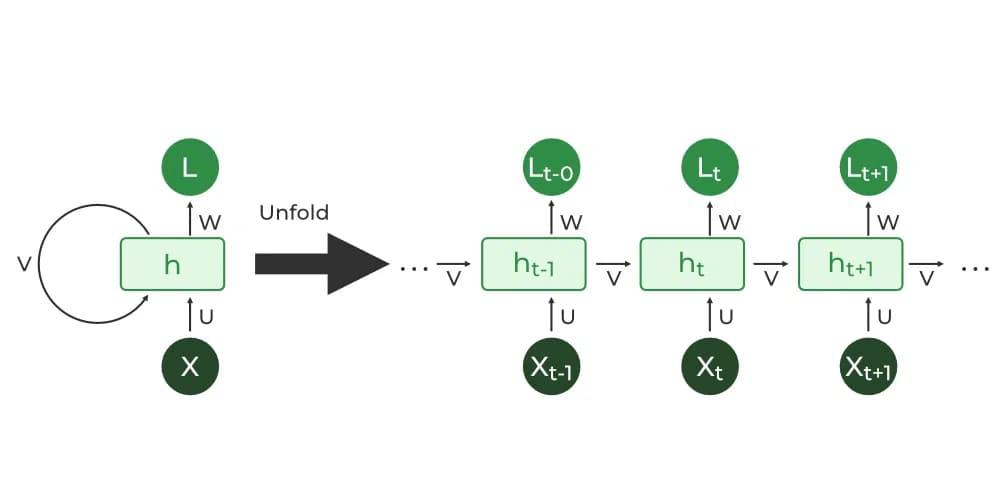
RNN or Recurrent Neural Network, belongs to the Neural Network family which is commonly used for Natural Language Processing (NLP) tasks. They specialize in handling any sequential data (be it video, text or time series as well). This is because of the presence of a Hidden state inside an RNN layer. The hidden state is responsible for memorizing the information from the previous timestep and using that for further adjustment of weights in Training a model.
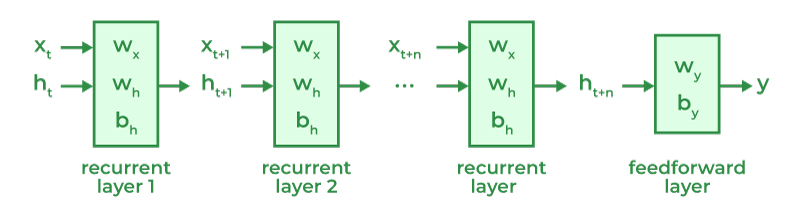
A single-layered RNN model has only a hidden layer which is liable to process sequential data. But Stacked RNN is a special kind of model that has multiple RNN layers one on each layer. This creates a 'Stack'. Each layer of this stack processes the input sequence.
This feature of Stacked RNNs enables to capture of both short-term and long-term patterns. For that reason, Stacked RNNs can learn and remember information patterns in longer sequences and at the same it can analyze their current state's information with just learned previous state's information. The more layers you add to your model, the stacked network will able to capture more complex patterns present in the sequential data. If your data is nested and has different types of complex patterns then Stacked RNNs will be a better model as its each layer can learn different abstractions present in your data.
First we will implement the Stacked RNN as code implementation where we will output the predicted value using the model's method.
Output:
1/1 [==============================] - 0s 344ms/step
Prediction from the neural network:
[[0.8465775]]
Now we will explore the mathematical concept behind the working of the stacked RNN
After the initial model is trained, we will get the weights associated with each layer in the architecture.
As per the equations used above, the present hidden state can be explained as a function of the activation function applied on the product of weights for input and respective inputs added to the product of weights for hidden states and hidden states with bias terms.
Output:
Prediction from manual computation:
[0.84657752]
Using Stacked RNNs can give us several benefits which are listed below-->
The architecture of Stacked RNNs can be divided into three parts which are discussed below-->
At first, we will import all necessary Python libraries like NumPy, TensorFlow , Matplotlib etc.
Now we will load IMDB dataset and define our desired maximum number of features (words) to consider in the vocabulary, maximum length of movie reviews (sequences) and the batch size for model training.
Now we will build a two layered stacked RNN model. Each RNN layer takes in units (here, we have taken it as 64) which is a positive integer and gives the output dimensionality of the layer. Since, we have not provided any activation function, it will take the default "Tanh" activation.
Output:
(Note: Here we are using Return_sequences = True, because this model is used for text generation. This is widely used in Sequence to sequence modelling.)
Here, we are optimizing our model with Adam optimizer, and for our metrics we are using accuracy. Since, this is a language model, we are choosing the loss function as Binary cross entropy. Binary Cross entropy is a useful loss function when doing a classification between two variables.
Output:
Epoch 1/5
782/782 [================] - 71s 86ms/step - loss: 0.5839 - accuracy: 0.6674 - val_loss: 0.4865 - val_accuracy: 0.7664
Epoch 2/5
782/782 [================] - 58s 74ms/step - loss: 0.3997 - accuracy: 0.8253 - val_loss: 0.4886 - val_accuracy: 0.7672
Epoch 3/5
782/782 [================] - 58s 74ms/step - loss: 0.2759 - accuracy: 0.8881 - val_loss: 0.5004 - val_accuracy: 0.8018
Epoch 4/5
782/782 [================] - 58s 74ms/step - loss: 0.1842 - accuracy: 0.9313 - val_loss: 0.5710 - val_accuracy: 0.7909
Epoch 5/5
782/782 [================] - 57s 73ms/step - loss: 0.1079 - accuracy: 0.9611 - val_loss: 0.7576 - val_accuracy: 0.7653
Now we will plot the metrics like Accuracy and loss (Binary Cross Entropy) with epochs.
Output:
Now we evaluate out stacked LSTM model on test set.
Output:
782/782 [==============================] - 12s 15ms/step - loss: 0.7576 - accuracy: 0.7653
Test Loss: 0.7575814723968506
Test Accuracy: 0.7653200030326843
So, from results we can say that out Stacked LSTM model is very efficient as it achieved 83.16% accuracy and Loss(MSE) and MAE both error functions is very low which shows the dependability a stacked RNN structure shows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}