 |
VOOZH | about |
|
VOOZH | about |
Token classification is a core task in Natural Language Processing (NLP) where each token (typically a word or sub-word) in a sequence is assigned a label. This task is important for extracting structured information from unstructured text. It does so by labeling tokens with specific categories such as entity types, parts of speech, or syntactic chunks. It helps models to better understand both the semantic meaning and the grammatical structure of the language.
Tokens are the smaller units of a text, typically separated by whitespace (like spaces or newlines) and punctuation marks (such as commas or periods). For example, Consider the sentence
"The quick brown fox jumps over the lazy dog."
The tokens for this sentence would be:
"The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."
1. In traditional NLP pipelines, tokenization is done at the word level, meaning each token corresponds directly to a word in the sentence.
Text: "running"
Tokens: ["running"]
This approach is simple, but has drawbacks as it struggles with :
2. Modern transformer-based models like BERT, RoBERTa, and GPT use sub-word tokenization algorithms such as WordPiece, Byte Pair Encoding (BPE) or Unigram models. These break words into smaller, meaningful fragments.
Text: "running"
Tokens: ["run", "##ing"]
"##ing" shows that it is a continuation of a previous sub-word. This method helps with:
The IOB tagging scheme also referred to as BIO (Beginning, Inside, Outside) is a widely used labeling format in token classification tasks such as Named Entity Recognition (NER), chunking, and semantic role labeling. This format helps models identify spans of consecutive tokens that together represent a meaningful entity (like a person’s name, organization, or location).
Components of IOB/BIO Tags
Each token is assigned one of these tags
Tags | Meaning |
|---|---|
B | Beginning of a chunk/entity |
I | Inside a chunk/entity |
O | Outside of any chunk/entity |
NER classified entities typically include categories such as person names, locations, organizations, dates, and more. The task involves assigning a specific label to each token in the text, indicating the type of entity it belongs to, or even a neutral label (often "O") if the token is not part of any named entity.
Code Example:
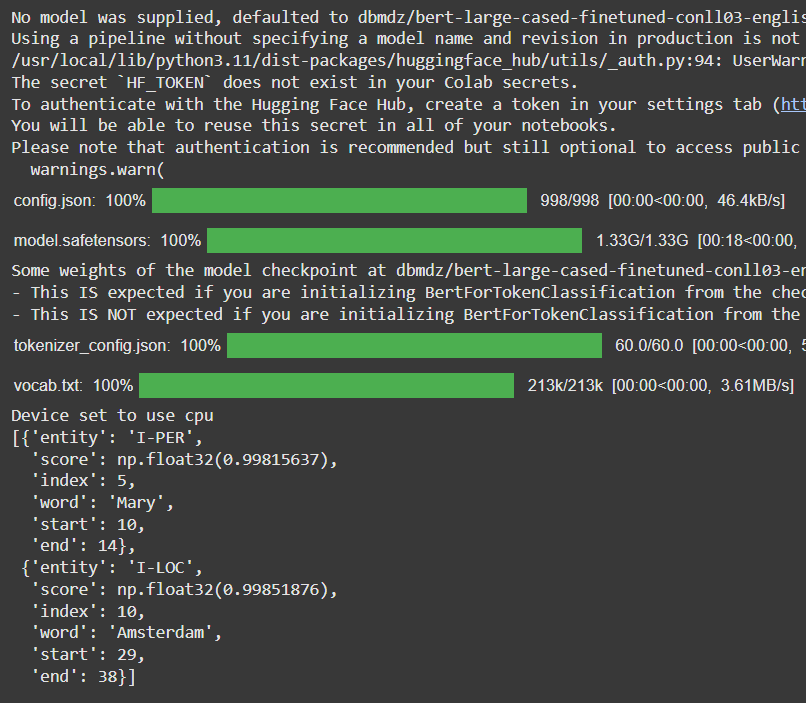
Output:
Interpretation:
I-PER) with 99.8% confidenceI-LOC) with 99.85% confidencePOS tagging is a classic token classification task, where the goal is to assign a grammatical category (such as noun, verb, adjective, etc.) to each word in a sentence. The model processes the input text and labels each token based on its syntactic role within the sentence.
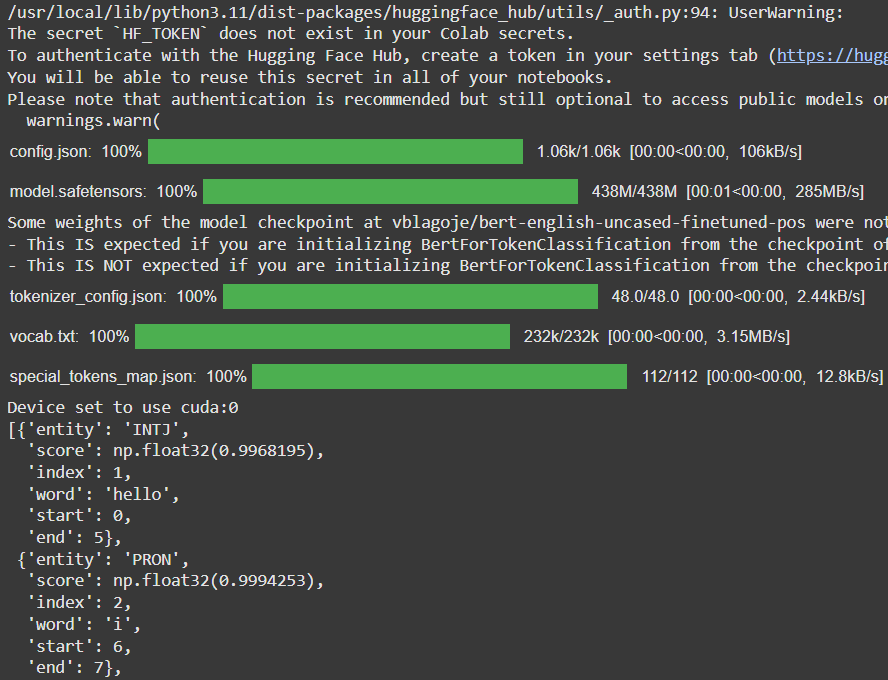
Code Example:
Output:
Interpretation:
| Token | POS Tag | Meaning | Confidence |
|---|---|---|---|
| hello | INTJ | Interjection (e.g., greetings) | 99.68% |
| i | PRON | Pronoun | 99.94% |
| ' | AUX | Auxiliary verb (part of "I'm") | 99.67% |
| m | AUX | Auxiliary verb ("am") | 99.65% |
| mary | PROPN | Proper noun | 99.85% |
| and | CCONJ | Coordinating conjunction | 99.92% |
| i | PRON | Pronoun | 99.95% |
| live | VERB | Main verb | 99.86% |
| in | ADP | Adposition (preposition) | 99.94% |
| amsterdam | PROPN | Proper noun | 99.88% |
. | PUNCT | Punctuation | 99.96% |
{kind=link}
{kind=link}
{kind=link}