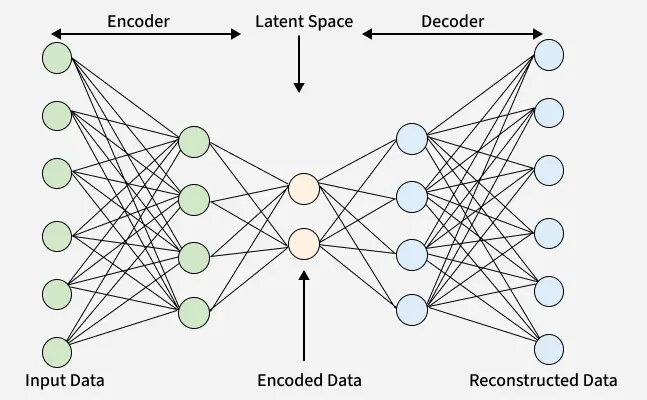
Autoencoders are a type of neural network designed to learn efficient data representations. They work by compressing input data into a smaller, dense format called the latent space using an encoder and then reconstructing the original input from this compressed form using a decoder. This makes autoencoders useful for tasks such as dimensionality reduction, feature extraction and noise removal.
Let’s see common types of autoencoders which are designed with unique features to handle specific challenges and tasks in data representation and learning.
1. Vanilla Autoencoder
Vanilla Autoencoder are the simplest form used for unsupervised learning tasks. They consist of two main parts an encoder that compresses the input data into a smaller, dense representation and a decoder that reconstructs the original input from this compressed form.
Training minimizes reconstruction error which measures the difference between input and output. This optimization is done via backpropagation which helps in updating the network weights to improve reconstruction accuracy.
They are foundational models helps in serving as building blocks for more complex variants.
Applications
Some key applications include:
Data Compression: They learn a compact version of the input data making storage and transmission more efficient.
Feature Learning: It extract important patterns from data which is useful in image processing, natural language processing and sensor analysis.
Anomaly Detection: If the reconstructed output is different from the original input, it can show an anomaly or outlier which makes autoencoders useful for fraud detection and system monitoring.
Now lets see the practical implementation.
Here we will be using Numpy, Matplotlib and Tensorflow libraries for its implementation and also we are using inbuilt dataset for this.
(x_train, _), (x_test, _) = fashion_mnist.load_data(): Loads Fashion MNIST dataset into training and testing sets, ignoring labels.
encoded = tf.keras.layers.Dense(encoding_dim, activation='relu')(input_img): Encodes input into 32-dimensional vector with ReLU activation.
decoded = tf.keras.layers.Dense(784, activation='sigmoid')(encoded): Decodes the compressed vector back to 784 dimensions with sigmoid activation.
autoencoder = tf.keras.Model(input_img, decoded): Creates the autoencoder model connecting input to output.
Sparse Autoencoder add sparsity constraints that encourage only a small subset of neurons in the hidden layer to activate at once helps in creating a more efficient and focused representation.
Unlike vanilla models, they include regularization methods like L1 penalty and dropout to enforce sparsity.
KL Divergence is used to maintain the sparsity level by matching the latent distribution to a predefined sparse target.
This selective activation helps in feature selection and learning meaningful patterns while ignoring irrelevant noise.
Applications
Feature Selection: Highlights the most relevant features by encouraging sparse activation helps in improving interpretability.
Dimensionality Reduction: Creates efficient, low-dimensional representations by limiting active neurons.
Noise Reduction: Reduces irrelevant information and noise by activating only key neurons helps in improving model generalization.
Now lets see the practical implementation.
encoded = tf.keras.layers.Dense(encoding_dim, activation='relu', activity_regularizer=tf.keras.regularizers.l1(1e-5))(input_img): Creates the encoded layer with ReLU activation and adds L1 regularization to encourage sparsity.
Variational Autoencoder (VAEs) extend traditional autoencoders by learning probabilistic latent distributions instead of fixed representations. Training optimizes the Evidence Lower Bound (ELBO) which balances:
Reconstruction loss to ensure accurate data reconstruction.
KL Divergence to regularize the latent space towards a standard Gaussian helps in preventing overfitting and smooth latent structure.
By balancing these two terms VAEs can generate meaningful outputs while keeping the latent space structured.
Applications
Here are some common applications:
Image Generation: Creates new realistic images by sampling from learned latent distributions.
Anomaly Detection: Identifies anomalies by measuring how well input data is reconstructed.
Dimensionality Reduction: Produces low-dimensional latent spaces useful for visualization and clustering.
Now lets see the practical implementation.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) : Reshapes training images to 28x28 with 1 channel for Conv2D input.
input_img = tf.keras.Input(shape=(28, 28, 1)) : Defines input layer for grayscale images with shape 28x28x1.
tf.keras.layers.MaxPooling2D((2, 2), padding='same')(x) : Reduces spatial dimensions by half using max pooling with same padding.
decoded = tf.keras.layers.Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) : Outputs reconstructed image with 1 channel and sigmoid activation for pixel values between 0 and 1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}