Cluster sampling is a sampling technique used in statistics and research methodology where the population is divided into groups or clusters and then a random sample of these clusters is selected for analysis. Instead of individually sampling each element of the population, cluster sampling involves selecting entire groups or clusters and then sampling within those clusters.
How to Perform Cluster Sampling
Defining the Population: We identify the target population we want to study, such as households, schools, hospitals or other relevant units.
Defining the Clusters: We divide the population into clusters, which are naturally occurring groups like cities, states, schools or hospitals.
Randomly Selecting Clusters: We use a random sampling method to choose a subset of clusters, ensuring each cluster has an equal chance of being selected to avoid bias.
Collecting Data from Selected Clusters: We collect data from all units within the selected clusters or from a sample within each cluster, using surveys, interviews, observations or existing records.
Implementation of Cluster Sampling in R
We implement cluster sampling in R programming language by selecting groups (clusters) from a population and optionally sampling individual elements within them using one-stage, two-stage or multi-stage approaches.
1. Performing Single-Stage Cluster Sampling
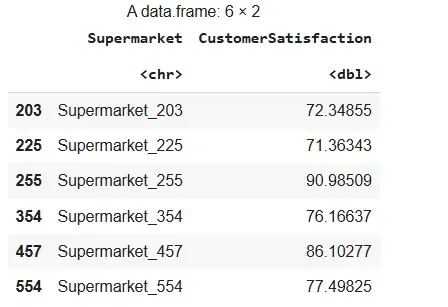
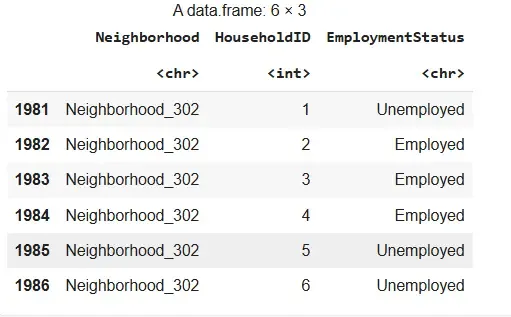
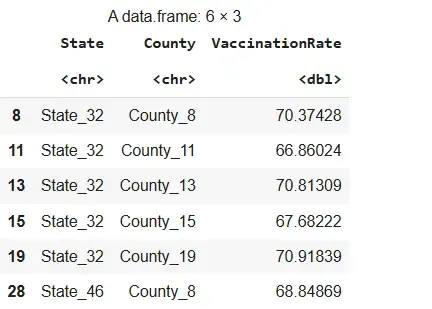
We randomly select clusters and include all elements within those selected clusters.
set.seed: Ensures reproducibility of random results.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}