 |
VOOZH | about |
|
VOOZH | about |
Decision Tree is a machine learning algorithm that assigns new observations to predefined categories based on a training dataset. Its goals are to predict class labels for unseen data and identify the features that define each class. It has a flowchart-like tree structure in which the internal node represents feature(or attribute), the branch represents a decision rule and each leaf node represents the outcome.
A Decision Tree consists of
Example:
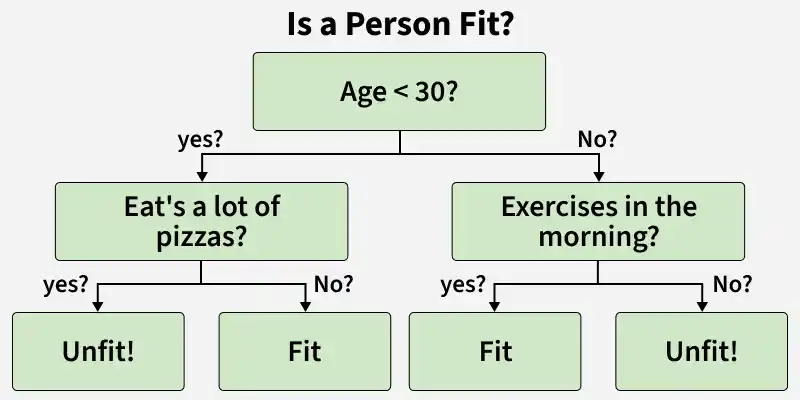
The diagram shows a decision tree that classifies a person as fit or unfit based on age, eating habits and exercise. If the person is under 30 and eats a lot of pizzas, they are unfit. If they do not eat a lot of pizzas, they are fit. If the person is 30 or older and exercises in the morning, they are fit. If they do not exercise, they are unfit.
We will implement a decision tree classifier in R programming language to predict whether a person purchases a product based on their age and estimated salary, using the rpart package. The steps include data preprocessing, model training, evaluation and visualization.
We install and load the necessary libraries to build and visualize the decision tree.
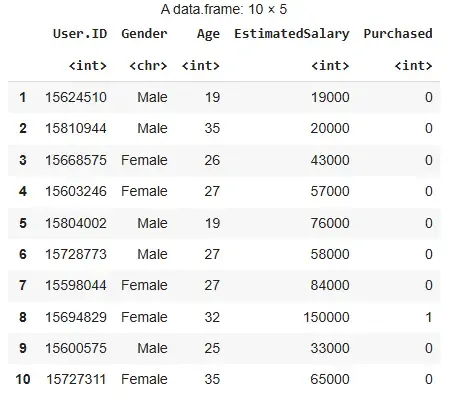
We will use the Advertisement dataset which contains advertising expenditures across different media channels and their corresponding impact on product Sales. We will load the CSV file containing the dataset and preview the first few records. You can download the dataset from here.
Output:
We encode the target variable as a factor and split the dataset into training and test sets.
We standardize the numerical features to ensure all values have the same scale.
We train the decision tree classifier on the training data.
We predict the class labels for the test data using the trained model.
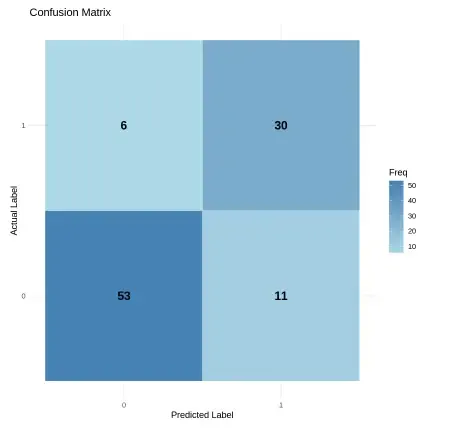
We generate a confusion matrix and visualize it to understand the model’s performance.
Output:
We create a grid of values and plot the decision boundary over the training data.
Output:
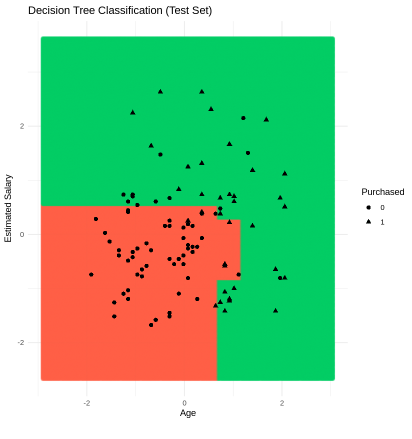
We repeat the visualization process for the test dataset to see how well the model generalizes.
Output:
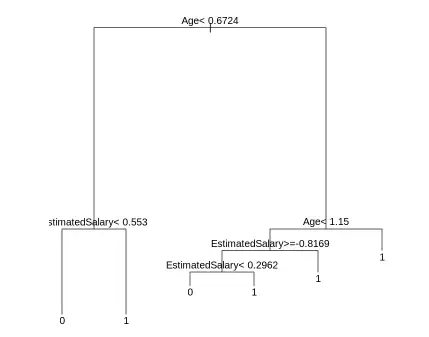
We plot the actual structure of the decision tree showing split criteria and class assignments.
Output:
The diagram shows a decision tree that classifies whether a person will purchase a product based on their age and estimated salary. It first checks if age is less than or equal to 44.5 and then further splits based on salary values. Each path ends in a prediction, either class 0 or 1, representing the model’s final decision.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}