 |
VOOZH | about |
|
VOOZH | about |
Feature Engineering in R means creating new features or modifying existing ones to make models work better. It includes cleaning, transforming, scaling, encoding and selecting features for machine learning.
In R, this is done using packages like dplyr, tidyr, caret and data.table.
Output:
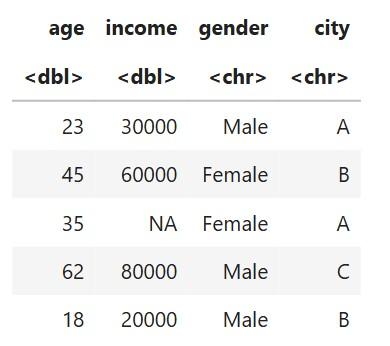
This dataset has:
We will use this small data to explain each concept.
The dataset contains a missing value in income.
Example (add NA for explanation):
Output:
Explanation:
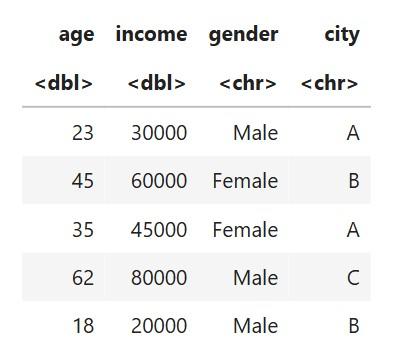
mean(..., na.rm = TRUE) calculates mean without NA.Label Encoding (for binary categories: gender)
Output:
Explanation:
One-Hot Encoding (for multi-class: city)
Output:
Explanation:
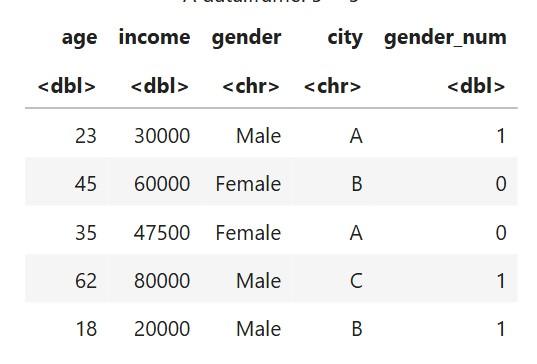
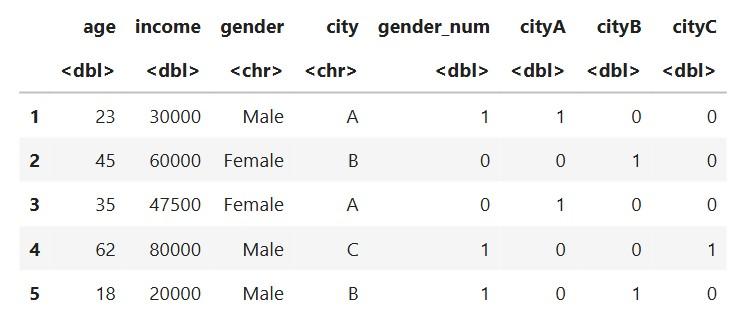
City A, B and C become separate columns:
Each gets 0/1 depending on membership.
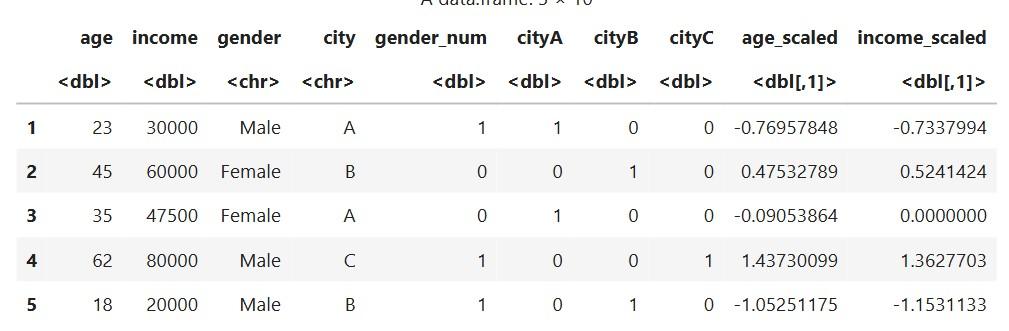
Scaling helps numeric values stay on similar ranges.
Using standard scaling (mean = 0, sd = 1)
Output:
Explanation:
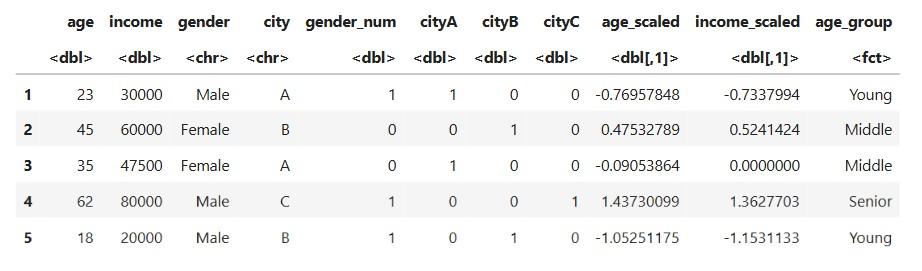
Create age groups:
Output:
Explanation:
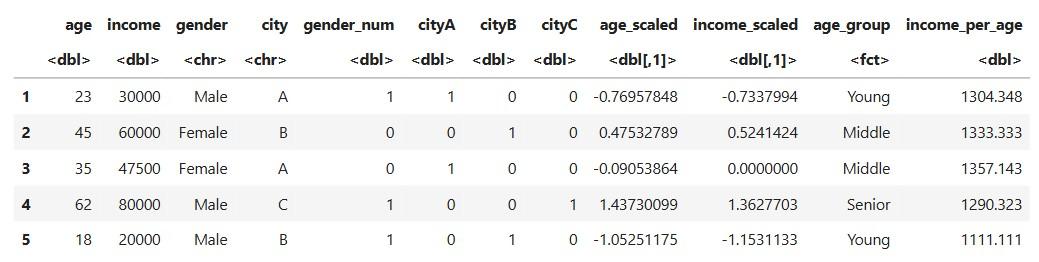
Create a new feature: income per year of age
Output:
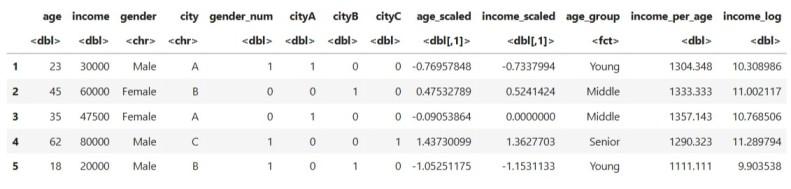
Apply log transformation to reduce skew in income:
Output:
Explanation:
After all steps, the dataset now looks like this:
This feature rich dataset is now ready for modeling.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}