 |
VOOZH | about |
|
VOOZH | about |
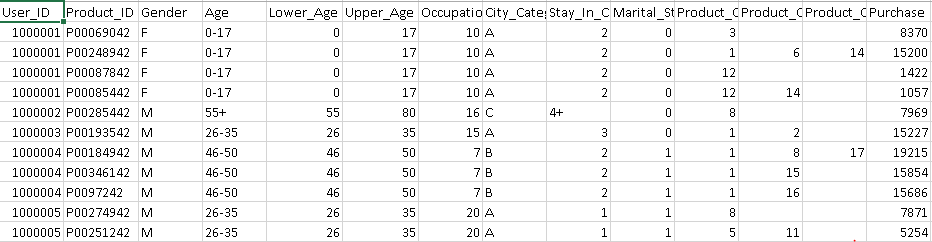
Categorical variables are known to hide and mask lots of interesting information in a data set. It’s crucial to learn the methods of dealing with such variables. If you won’t, many a times, you’d miss out on finding the most important variables in a model. It has happened with me. Initially, I used to focus more on numerical variables. Hence, never actually got an accurate model. But, later I discovered my flaws and learnt the art of dealing with such variables.
If you are a smart data scientist, you’d hunt down the categorical variables in the data set, and dig out as much information as you can. Right? But if you are a beginner, you might not know the smart ways to tackle such situations. Don’t worry. I am here to help you out.
After receiving a lot of requests on this topic, I decided to write down a clear approach to help you improve your models using categorical variables.
Note: This article is best written for beginners and newly turned predictive modelers. If you are an expert, you are welcome to share some useful tips of dealing with categorical variables in the comments section below.
👁 deal with categorical variables levels
I’ve had nasty experience dealing with categorical variables. I remember working on a data set, where it took me more than 2 days just to understand the science of categorical variables. I’ve faced many such instances where error messages didn’t let me move forward. Even, my proven methods didn’t improve the situation.
But during this process, I learnt how to solve these challenges. I’d like to share all the challenges I faced while dealing with categorical variables. You’d find:
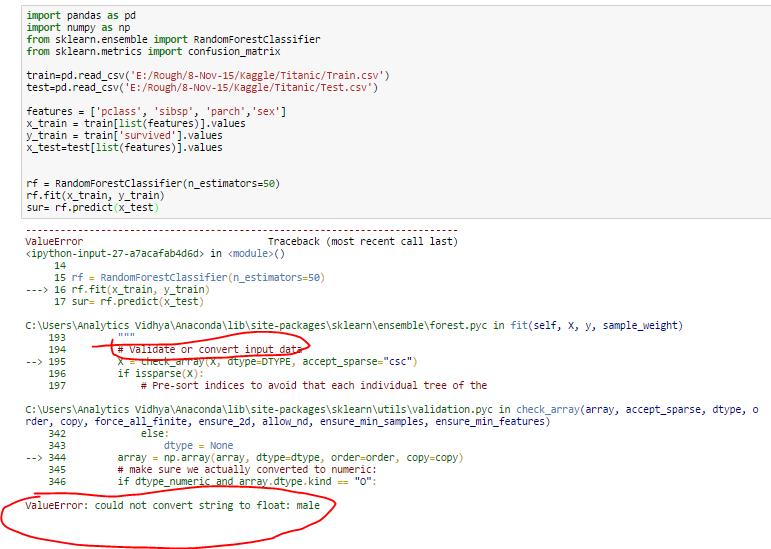
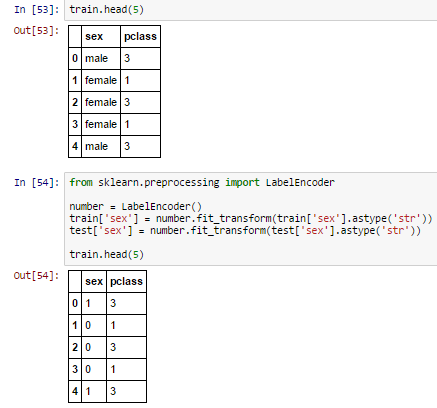
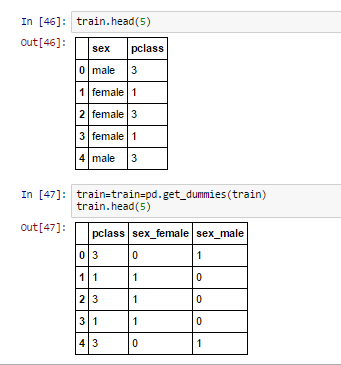
import pandas as pd
import numpy as np
import sklearn as sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
features = ['pclass','sibsp','parch','sex']
x_train = train[list(features)].values
y_train = train['survived'].values
x_test = test[list(features)].values
rf = RandomForestClassifier(n_estimators=50)
rf.fit(x_train, y_train)
sur=rf.predict(x_test)
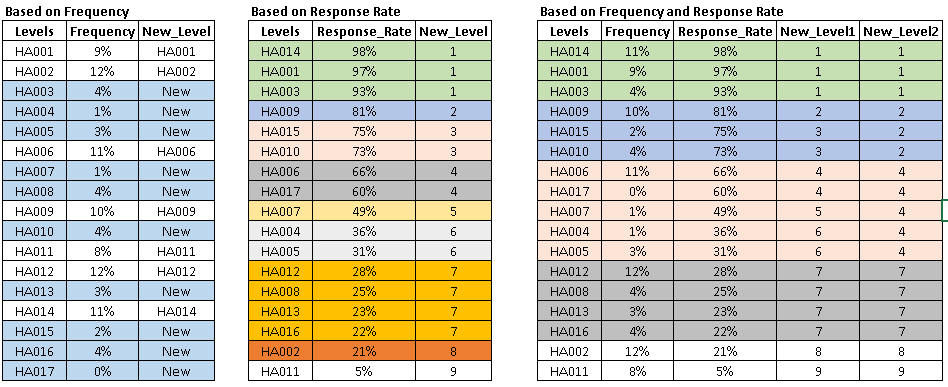
Here are some methods I used to deal with categorical variable(s). A trick to get good result from these methods is ‘Iterations’. You must know that all these methods may not improve results in all scenarios, but we should iterate our modeling process with different techniques. Later, evaluate the model performance. Below are the methods:
In this article, we discussed the challenges you might face while dealing with categorical variable in modelling. We also discussed various methods to overcome those challenge and improve model performance. I’ve used Python for demonstration purpose and kept the focus of article for beginners.
In order to keep article simple and focused towards beginners, I have not described advanced methods like “feature hashing”. I will take it up as a separate article in itself in future.
You must understand that these methods are subject to the data sets in question. I’ve seen even the most powerful methods failing to bring model improvement. Whereas, a basic approach can do wonders. Hence, you must understand the validity of these models in context to your data set. If you still face any trouble, I shall help you out in comments section below.
Did you find this article helpful ? Do you know of other methods which work well with categorical variables? Please share your thoughts in the comments section below. I’d love to hear you.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions.
I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya.
Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles.
Industry exposure: Insurance, and EdTech
Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Sunil, Thanks for sharing your thoughts and experience on how to treat Categorical Variables in a dataset! Can you elaborate more on combining levels based on Response Rate and Frequnecy Distribution? Or any pointers is highly appreciated. Thanks!
I would also appreciate the answer to this question. What do you mean by "response rate' in this context?
Hi Sunil, Thank you for great article. Can you explain how to calculate response rate or what does response rate mean ?. I tried googling but I am unable to relate to this particular data science context.
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}