 |
VOOZH | about |
|
VOOZH | about |
A Pandas DataFrame is a two-dimensional data structure made up of rows and columns, similar to a spreadsheet or SQL table. In Pandas, you can easily select, add, delete or rename rows and columns to manage and analyze your data efficiently.
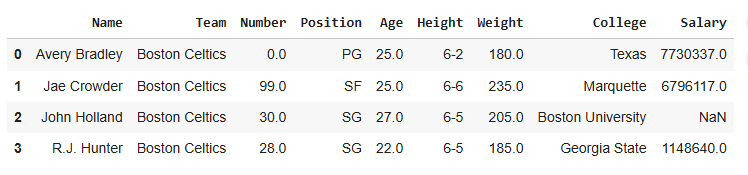
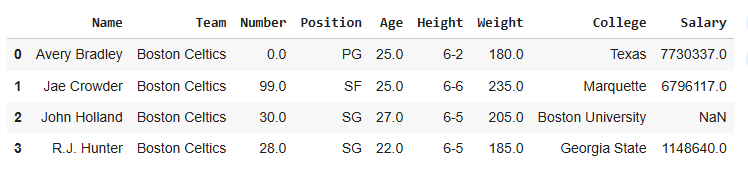
Below is the Sample DataFrame used in this article:
To Download the Sample DataFrame used in this article, click here
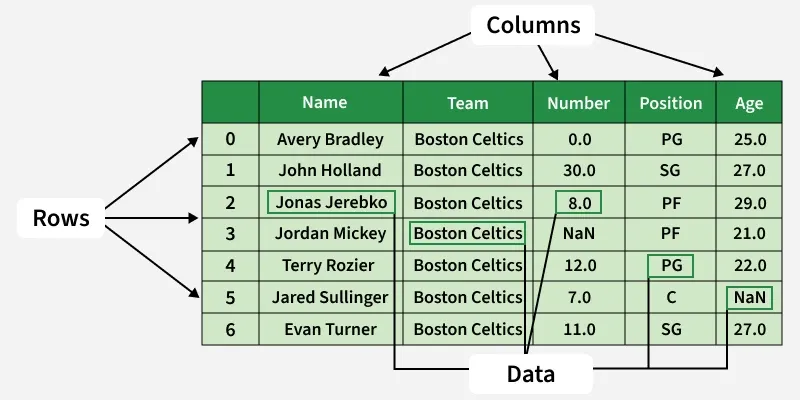
Below image shows a sample Pandas DataFrame with rows and columns labeled. The rows represent individual records (like players), while the columns represent attributes such as Name, Team, Number, Position and Age.
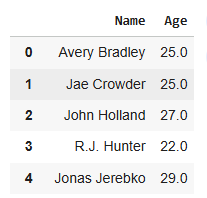
You can access one or more columns using their column names.
Output:
Explanation:df[['Name', 'Age']]: selects the specified columns and returns a new DataFrame with only those columns.
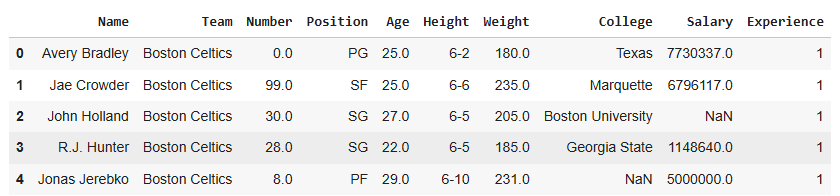
New columns can be added by assigning a list or series to a column name.
Output:
Explanation:df['Experience'] = [...]: adds a new column Experience with the given values.
You can delete a column from the DataFrame using the drop() method.
Output:
Explanation: df.drop('Experience', axis=1, inplace=True): removes the 'Experience' column from the DataFrame permanently.
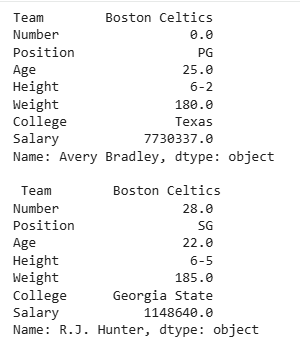
Rows can be selected using .loc[] by row label or index.
Output:
Explanation:.loc[row_label]: returns a Series corresponding to the row. You can select multiple rows similarly by passing a list.
New rows can be added using pd.concat().
Output:
Explanation:
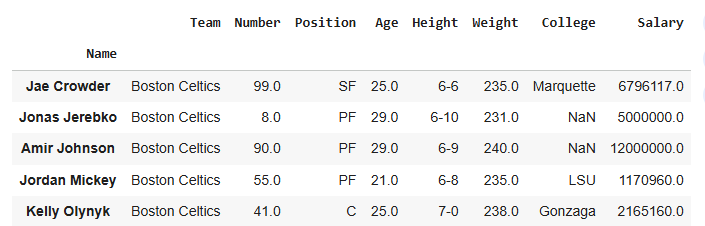
Rows can be removed using drop() with row labels.
Output:
Explanation: data.drop(["Avery Bradley", "John Holland", "R.J. Hunter"], inplace=True): deletes the specified rows from the DataFrame permanently.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}