 |
VOOZH | about |
|
VOOZH | about |
This article was published as a part of the Data Science Blogathon.
Missing data in machine learning is a type of data that contains null values, whereas Sparse data is a type of data that does not contain the actual values of features; it is a dataset containing a high amount of zero or null values. It is a different thing than missing data.
Sparse datasets with high zero values can cause problems like over-fitting in the machine learning models and several other problems. That is why dealing with sparse data is one of the most hectic processes in machine learning.
Most of the time, sparsity in the dataset is not a good fit for the machine learning problems in it should be handled properly. Still, sparsity in the dataset is good in some cases as it reduces the memory footprint of regular networks to fit mobile devices and shortens training time for ever-growing networks in deep learning.
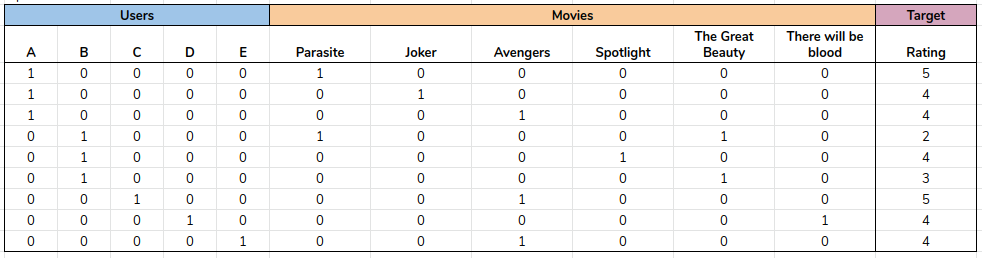
In the above Image, we can see the dataset with a high amount of zeros, meaning that the dataset is sparse. Most of the time, while working with a one-hot encoder, this type of sparsity is observed due to the working principle of the one-hot encoder.
Several problems with the sparse datasets cause problems while training machine learning models. Due to the problem associated with sparse data, it should be handled properly.
A common problem with sparse data is:
1. Over-fitting:
if there are too many features included in the training data, then while training a model, the model with tend to follow every step of the training data, results in higher accuracy in training data and lower performance in the testing dataset.
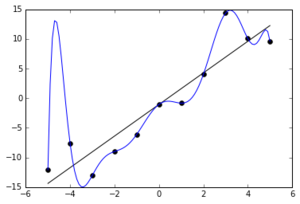
In the above image, we can see that the model is over-fitted on the training data and tries to follow or mimic every trend of the training data. This will result in lower performance of the model on testing or unknown data.
2. Avoiding Important Data:
Some machine-learning algorithms avoid the importance of sparse data and only tend to train and fit on the dense dataset. They do not tend to fit on sparse datasets.
The avoided sparse data can also have some training power and useful information, which the algorithm neglects. So it is not always a better approach to deal with sparse datasets.
3. Space Complexity
If the dataset has a sparse feature, it will take more space to store than dense data; hence, the space complexity will increase. Due to this, higher computational power will be needed to work with this type of data.
4. Time Complexity
If the dataset is sparse, then training the model will take more time to train compared to the dense dataset on the data as the size of the dataset is also higher than the dense dataset.
5. Change in Behavior of the algorithms
Some of the algorithms might perform badly or low on sparse datasets. Some algorithms tend to perform badly while training them on sparse datasets. Logistic Regression is one of the algorithms which shows flawed behavior in the best fit line while training it on a space dataset.
As discussed above, sparse datasets can be proven bad for training a machine learning model and should be handled properly. There are several ways to deal with sparse datasets.
1. Convert the feature to dense from sparse
It is always good to have dense features in the dataset while training a machine learning model. If the dataset has sparse data, it would be a better approach to convert it to dense features.
There are several ways to make the features dense:
1. Use Principle Component Analysis:
PCA is a dimensionality reduction method used to reduce the dimension of the dataset and select important features only in the output.
Example:
# using iris dataset for implementing PCA
# Loading The Dataset
import pandas as pd
import numpy as np
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
df = pd.read_csv(url, names=['SepalLength','SepalWidth','PetalLength','PetalWidth','label'])
print(df.head())Implementing PCA on the dataset
from sklearn.decomposition import PCA pca = PCA(n_components=2) principalComponents = pca.fit_transform(df) pca_df = pd.DataFrame(data = principalComponents , columns = ['principal component 1', 'principal component 2']) df = pd.concat([pca_df, df[['label']]], axis = 1)
2. Use Feature Hashing:
Feature hashing is a technique used on sparse datasets in which the dataset can be binned into the desired number of outputs.
from sklearn.feature_extraction import FeatureHasher
h = FeatureHasher(n_features=10)
p = [{'dog': 1, 'cat':2, 'elephant':4},{'dog': 2, 'run': 5}]
f = h.transform(p)
f.toarray()
Output:
array([[ 0., 0., -4., -1., 0., 0., 0., 0., 0., 2.], [ 0., 0., 0., -2., -5., 0., 0., 0., 0., 0.]])
3. Perform Feature Selection and Feature Extraction
4. Use t-Distributed Stochastic Neighbor Embedding (t-SNE)
5. Use low variance filter
2. Remove the features from the model
It is one of the easiest and quick methods for handling sparse datasets. This method includes removing some of the features from the dataset which are not so important for the model training.
However, it should be noted that sometimes sparse datasets can also have some useful and important information that should not be removed from the dataset for better model training, which can cause lower performance or accuracy.
Dropping a whole column having sparse data:
import pandas as pd df = pd.drop(['SparseColumnName'],axis=1)
Dropping a column having sparse datatype:
import pandas as pd
import numpy as np
df = pd.DataFrame({"A": pd.arrays.SparseArray([0, 1, 0])})
df.sparse.to_dense()
print(df)
3. Use methods that are not affected by sparse datasets
Some of the machine learning models are robust to the sparse dataset, and the behavior of the models is not affected by the sparse datasets. This approach can be used if there is no restriction to using these algorithms.
For example, Normal K means the algorithm is affected by sparse datasets and performs badly, resulting in lower accuracy. Still, the entropy-weighted k means algorithm is not affected by the sparse data, giving reliable results. So it can be used while dealing with sparse datasets.
Sparse data in machine learning is a widespread problem, especially when working with one hot encoding. Due to the problem caused by sparse data (like over-fitting, lower performance of the models, etc.), handling these types of data is more recommended for better model building and higher performance of the machine-learning models.
Some Key Insights from this blog are:
1. Sparse data is completely different from missing data. It is a form of data that contains a high amount of zero values.
2. The sparse data should be handled properly to avoid problems like time and space complexity, lower performance of the models, over-fitting, etc.
3. Dimensionality reduction, converting the sparse features into dense features and using algorithms like entropy-weighted k means, which are robust to sparsity, can be the solution while dealing with sparse datasets.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 50+ Published Articles on Data Science | Technical Writer (AI/ML/DL) | Data Science Freelancer | Amazon ML Summer School '22 | Reach Out @[email protected], @portfolio.parthshukla.live
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}