 |
VOOZH | about |
|
VOOZH | about |
Data engineering plays a pivotal role in the vast data ecosystem by collecting, transforming, and delivering data essential for analytics, reporting, and machine learning. Aspiring data engineers often seek real-world projects to gain hands-on experience and showcase their expertise. This article presents the top 20 data engineering project ideas with their source code. Whether you’re a beginner, an intermediate-level engineer, or an advanced practitioner, these projects offer an excellent opportunity to sharpen your big data and data engineering skills.
In this article, you will discover various data engineering projects that are perfect for beginners. We will explore data engineering projects with source code, providing you with practical examples. Additionally, you’ll learn how to approach a data engineering project step by step, ensuring a comprehensive understanding of the process. By the end, you’ll be equipped with the knowledge to tackle your own data engineering projects for beginners confidently.
The major goal of this project is to establish a trustworthy data pipeline for collecting and analysing data from IoT (Internet of Things) devices. Webcams, temperature sensors, motion detectors, and other IoT devices all generate a lot of data. You want to design a system to effectively consume, store, process, and analyze this data. By doing this, real-time monitoring and decision-making based on the learnings from the IoT data are made possible.
Click here to check the source code
To collect, process, and analyze aviation data from numerous sources, including the Federal Aviation Administration (FAA), airlines, and airports, this project attempts to develop a data pipeline. Aviation data includes flights, airports, weather, and passenger demographics. Your goal is to extract meaningful insights from this data to improve flight scheduling, enhance safety measures, and optimize various aspects of the aviation industry.
Click here to view the Source Code
In this project, your objective is to create a robust ETL (Extract, Transform, Load) pipeline that processes shipping and distribution data. By using historical data, you will build a demand forecasting system that predicts future product demand in the context of shipping and distribution. This is crucial for optimizing inventory management, reducing operational costs, and ensuring timely deliveries.
Click here to view the source code for this data engineering project,
Make a data pipeline that collects information from various events, including conferences, sporting events, concerts, and social gatherings. Real-time data processing, sentiment analysis of social media posts on these events, and the creation of visualizations to show trends and insights in real-time are all part of the project.
Click here to check the source code.
Build a comprehensive log analytics system that collects logs from various sources, including servers, applications, and network devices. The system should centralize log data, detect anomalies, facilitate troubleshooting, and optimize system performance through log-based insights.
Click here to explore this data engineering project
A recommendation engine has been designed and developed using the Movielens dataset. To ensure data quality, a robust Extract, Transform, Load (ETL) pipeline was created to preprocess and clean the dataset. This pipeline helps in handling missing values, removing duplicates, and organizing the data for analysis. Collaborative filtering algorithms were then implemented to offer personalized movie suggestions to users based on their preferences and past interactions with movies. This approach leverages the collective wisdom of users to make recommendations, enhancing the movie-watching experience.
Click here to explore this data engineering project.
Create a retail analytics platform that ingests data from various sources, including point-of-sale systems, inventory databases, and customer interactions. Analyze sales trends, optimize inventory management, and generate personalized product recommendations for customers.
Click here to explore the source code.
Contribute to an open-source project focused on real-time data analytics. This project provides an opportunity to improve the project’s data processing speed, scalability, and real-time visualization capabilities. You may be tasked with enhancing the performance of data streaming components, optimizing resource usage, or adding new features to support real-time analytics use cases.
Click here to explore the source code for this data engineering project.
Explore Azure Stream Analytics by contributing to or creating a real-time data processing project on Azure. This may involve integrating Azure services like Azure Functions and Power BI to gain insights and visualize real-time data. You can focus on enhancing the real-time analytics capabilities and making the project more user-friendly.
Click here to explore the source code for this data engineering project.
Build a data pipeline that collects and processes real-time financial stock market data using the Finnhub API and Apache Kafka. This project involves analyzing stock prices, performing sentiment analysis on news data, and visualizing real-time market trends. Contributions can include optimizing data ingestion, enhancing data analysis for data analyst, or improving the visualization components.
Click here to explore the source code for this project.
Collaborate on a real-time music streaming data project focused on processing and analyzing user behavior data in real time. You’ll explore user preferences, track popularity, and enhance the music recommendation system. Contributions may include improving data processing efficiency, implementing advanced recommendation algorithms, or developing real-time dashboards.
Click here to explore the source code.
Develop a comprehensive website monitoring system that tracks performance, uptime, and user experience. This project involves utilizing tools like Selenium for web scraping to collect data from websites and creating alerting mechanisms for real-time notifications when performance issues are detected.
Click here to explore the source code of this data engineering project.
Dive into the cryptocurrency world by creating a Bitcoin mining data pipeline. Analyze transaction patterns, explore the blockchain network, and gain insights into the Bitcoin ecosystem. This project will require data collection from blockchain APIs, analysis, and visualization.
Click here to explore the source code for this data engineering project.
Explore Google Cloud Platform (GCP) by designing and implementing a data engineering project that leverages GCP services like Cloud Functions, BigQuery, and Dataflow. This project can include data processing, transformation, and visualization tasks, focusing on optimizing resource usage and improving data engineering workflows.
Click here to explore the source code for this project.
Collect and analyze data from Reddit, one of the most popular social media platforms. Create interactive visualizations and gain insights into user behavior, trending topics, and sentiment analysis on the platform. This project will require web scraping, data analysis, and creative data visualization techniques.
Click here to explore the source code for this project.
The objective of this project is to analyze Yelp data by building a data pipeline to extract, transform, and load the information. The analysis includes identifying popular businesses, conducting sentiment analysis on user reviews, and providing actionable insights to local businesses for improving their services based on the data.
Click here to explore the source code for this project.
Data governance is critical for ensuring data quality, compliance, and security. In this project, you will design and implement a data governance framework using Azure services. This may involve defining data policies, creating data catalogs, and setting up data access controls to ensure data is used responsibly and in accordance with regulations.
Click here to explore the source code for this data engineering project.
Design a real-time data ingestion pipeline on Azure using services like Azure Data Factory, Azure Stream Analytics, and Azure Event Hubs. The goal is to ingest data from various sources and process it in real time, providing immediate insights for decision-making.
Click here to explore the source code for this project.
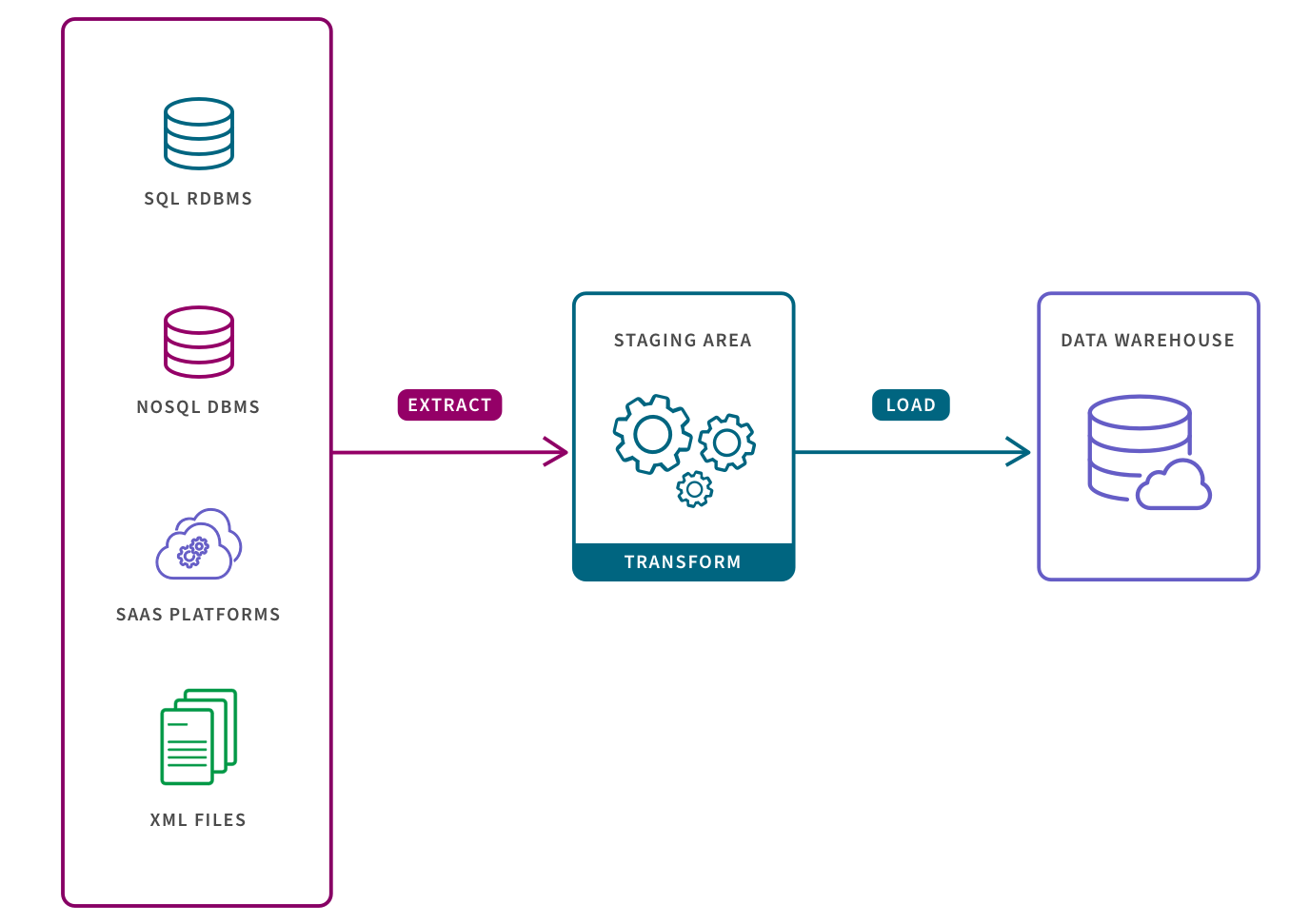
Build an end-to-end ETL (Extract, Transform, Load) pipeline on AWS. The pipeline should extract data from various sources, perform transformations, and load the processed data into a data warehouse or lake. This project is ideal for understanding the core principles of data engineering.
Click here to explore the source code for this project.
Explore ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) data integration approaches on AWS. Compare their strengths and weaknesses in different scenarios. This project will provide insights into when to use each approach based on specific data engineering requirements.
Click here to explore the source code for this project.
The mentioned projects offer excellent opportunities to enhance your resume. These diverse experiences encompass designing recommendation engines, developing ETL pipelines, and analyzing real-time data with technologies like Apache Flink and Spark Streaming. Additionally, the projects involve comprehensive analysis of Yelp data, including identifying popular businesses and providing insights to improve services. These accomplishments showcase a strong skill set in data engineering, analytics, and software development, making them valuable additions to your resume.
This curated list features 20 data engineering projects, offering hands-on experience across various skill levels. From IoT infrastructure and aviation data analysis to retail analytics and real-time financial market data processing, each project leverages key technologies such as Apache Airflow, Docker, JSON, PostgreSQL, and more. Emphasizing raw data transformation, ETL pipelines, and business intelligence, these projects cater to software engineers seeking practical applications and proficiency in programming languages. The inclusion of technologies like Delta Lake and CSV handling further enhances the versatility of these projects, making them valuable for skill development in the dynamic field of data engineering.
But don’t stop here; if you’re eager to take your data engineering journey to the next level, consider enrolling in our. With BB+, you’ll gain access to expert guidance, hands-on experience, and a supportive community, propelling your data engineering skills to new heights.
A. Data engineering involves designing, constructing, and maintaining data pipelines, including essential aspects like data modeling. For instance, creating a pipeline to collect, clean, and store customer data for analysis showcases how data engineering incorporates effective data modeling techniques to structure and organize information for meaningful insights.
A. Best practices in data engineering include robust data quality checks, efficient ETL processes, documentation, and scalability for future data growth.
A. Data engineers work on tasks like data pipeline development, ensuring data accuracy, collaborating with data scientists, and troubleshooting data-related issues.
A. To showcase data engineering projects on a resume, highlight key projects, mention technologies used, and quantify the impact on data processing or analytics outcomes.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}