 |
VOOZH | about |
|
VOOZH | about |
The only agent that thinks for itself
Autonomous Monitoring with self-learning AI built-in, operating independently across your entire stack.
Centralized metrics streaming and storage
Aggregate metrics from multiple agents into centralized Parent nodes for unified monitoring across your infrastructure.
Fully managed cloud platform
Access your monitoring data from anywhere with our SaaS platform. No infrastructure to manage, automatic updates, and global availability.
Deploy Netdata Cloud in your infrastructure
Run the full Netdata Cloud platform on-premises for complete data sovereignty and compliance with your security policies.
Powerful, intuitive monitoring interface
Modern, responsive UI built for real-time troubleshooting with customizable dashboards and advanced visualization capabilities.
Monitor on the go
Native iOS and Android apps bring full monitoring capabilities to your mobile device with real-time alerts and notifications.
The future of infrastructure observability
See our strategic direction across AI-native observability, full-stack signals, operational intelligence, and enterprise platform maturity.
Best energy efficiency
True real-time per-second
100% automated zero config
Centralized observability
Multi-year retention
High availability built-in
Zero maintenance
Always up-to-date
Enterprise security
Complete data control
Air-gap ready
Compliance certified
Millisecond responsiveness
Infinite zoom & pan
Works on any device
Native performance
Instant alerts
Monitor anywhere
AI-native observability
Continuous delivery
Open source foundation
80% Faster Incident Resolution
True Real-Time and Simple, even at Scale
90% Cost Reduction, Full Fidelity
See and Map Your Entire Network
Single Pane of Glass
Control Without Surrender
Integrations
800+ collectors and notification channels, auto-discovered and ready out of the box.
Reduced monitoring costs by 46% while cutting staff overhead by 67%.
— Leonardo Antunez, Codyas
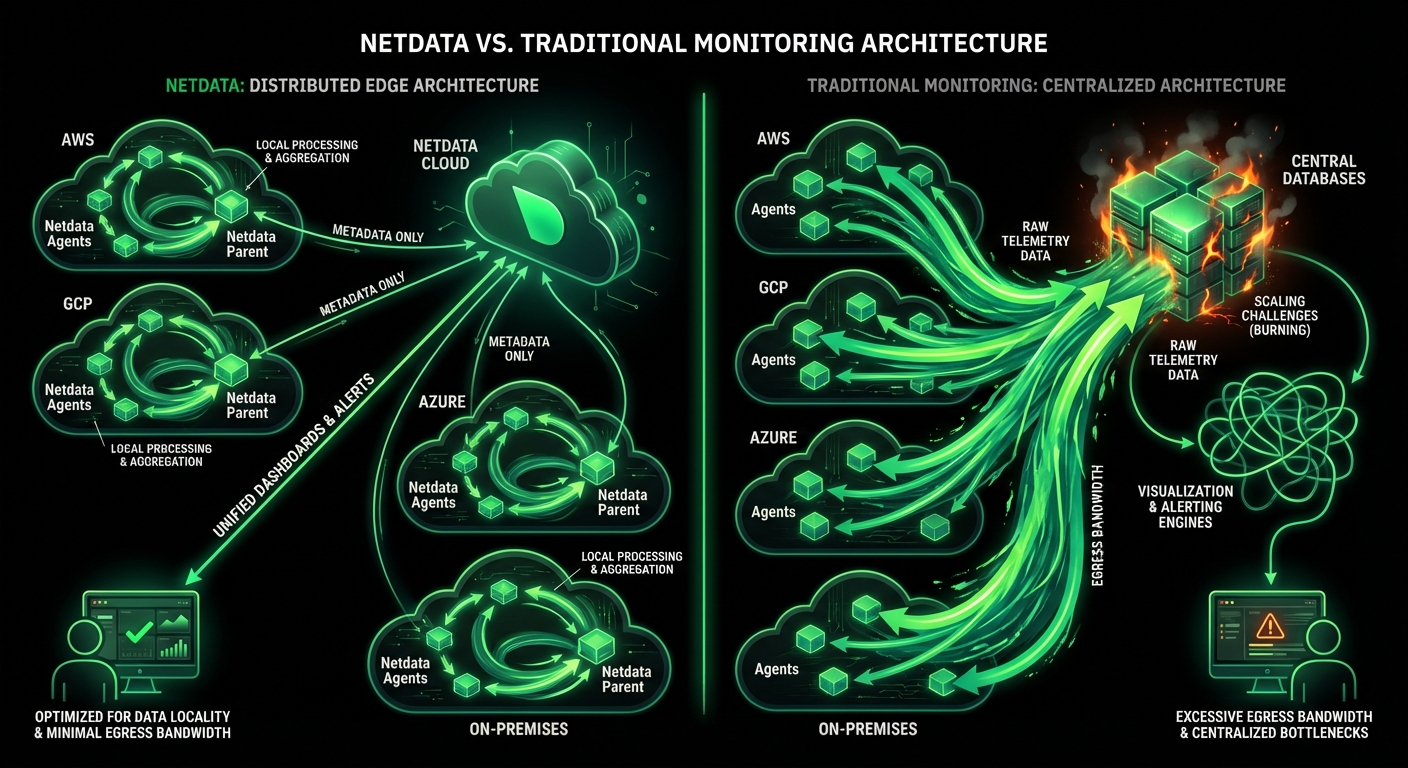
No data shipping. No central storage costs. Query at the edge.
So many out-of-the-box features! I mostly don't have to develop anything.
— Simon Beginn, LANCOM Systems
Point-and-click troubleshooting. No PromQL, no LogQL, no learning curve.
Enterprise efficiency without enterprise complexity—real ROI from day one.
— Leonardo Antunez, Codyas
Zero data egress. Only metadata reaches the cloud. Your metrics stay on your infrastructure.
Auto-discovered and configured. No manual setup required.
Slack, PagerDuty, Teams, email, webhooks—all built-in.
Built for the People Who Get Paged
Every Industry Has Rules. We Master Them.
Monitor Any Technology. Configure Nothing.
Complete Visibility. Total Control.
Don't Take Our Word for It
Netdata gives more than you invest in it. A rare unicorn that obeys the Pareto rule.
— Eduard Porquet Mateu, TMB Barcelona
Reduced website downtime by 99% and cloud bill by 30% using Netdata alerts.
— Falkland Islands Government
Optimized resource allocation based on Netdata alerts cut cloud spending by 30%.
— Falkland Islands Government
Reduced monitoring staff by 67% while cutting operational costs by 46%.
— Codyas
Netdata has agent capacity or a plugin for everything, including Windows and Kubernetes.
— Eduard Porquet Mateu, TMB Barcelona
So many out-of-the-box features! I mostly don't have to develop anything.
— Simon Beginn, LANCOM Systems
From 2-3 minutes to 30 seconds—instant visibility into any node issue.
— Matthew Artist, Nodecraft
20% less downtime and 40% budget optimization from out-of-the-box monitoring.
— Simon Beginn, LANCOM Systems
Pay per Node. Unlimited Everything Else.
One price per node. Unlimited metrics, logs, users, and retention. No per-GB surprises.
What's Your Monitoring Really Costing You?
Most teams overpay by 40-60%. Let's find out why.
Your Infrastructure Is Unique. Let's Talk.
Because monitoring 10 nodes is different from monitoring 10,000.
Monitoring That Sells Itself
Deploy in minutes. Impress clients in hours. Earn recurring revenue for years.
Per-Second Metrics at Homelab Prices
Same engine, same dashboards, same ML. Just priced for tinkerers.
$1,000 Per Referral. Unlimited Referrals.
Your colleagues get 10% off. You get 10% commission. Everyone wins.
"Netdata's significant positive impact" — LANCOM Systems
Compare vs Datadog, Grafana, Dynatrace
"Cut costs by 46%, staff by 67%" — Codyas
"Reduced cloud bill by 30%" — Falkland Islands Gov
"Better observability with Netdata than combining other tools." — TMB Barcelona
DPA, SLAs, on-prem, volume pricing
One command, 30 seconds, real data—no sandbox needed
Auto-config + per-node pricing = predictable profit
8-episode Netdata tutorial by LearnLinux.tv
3rd most starred monitoring project
Customers report 40-67% cost cuts, 99% downtime reduction
Free tier lets them try before they buy
AI Support Assistant, Available 24/7
Nedi has access to all official documentation, source code, and resources. Ask any question about Netdata—responds in your language.
Engineering Insights & Product Updates
Jun 2026
Network Monitoring, the Netdata Way: …
Interface counters tell you a port is busy. …
Jun 2026
5 Best SolarWinds Alternatives for 2026
As organizations modernize their …
Jun 2026
SolarWinds Price Increases 2026: What …
If you’re a SolarWinds customer facing …
May 2026
High-cardinality metrics at scale: why …
The “high cardinality is …
Never Fight Fires Alone
Docs, community, and expert help—pick your path to resolution.
60 Seconds to First Dashboard
One command to install. Zero config. 850+ integrations documented.
Level Up Your Monitoring
76,000+ Engineers Strong
Per-Second. 90% Cheaper. Data Stays Home.
See why teams switch from Datadog, Prometheus, Grafana, and more.
> Browse all comparisonsTrace issues directly in the source code
Get architecture recommendations
One of the most popular open-source monitoring projects
Enterprise-grade security and compliance
Your metrics stay on your infrastructure
"Most energy-efficient monitoring solution" — ICSOC 2023, peer-reviewed
"Doesn't miss alerts—mission-critical trust for safety software"
Global community improving monitoring for everyone
Trusted by teams worldwide
Free forever, fully open source agent
Work from anywhere, async-friendly culture
Your work helps millions of systems
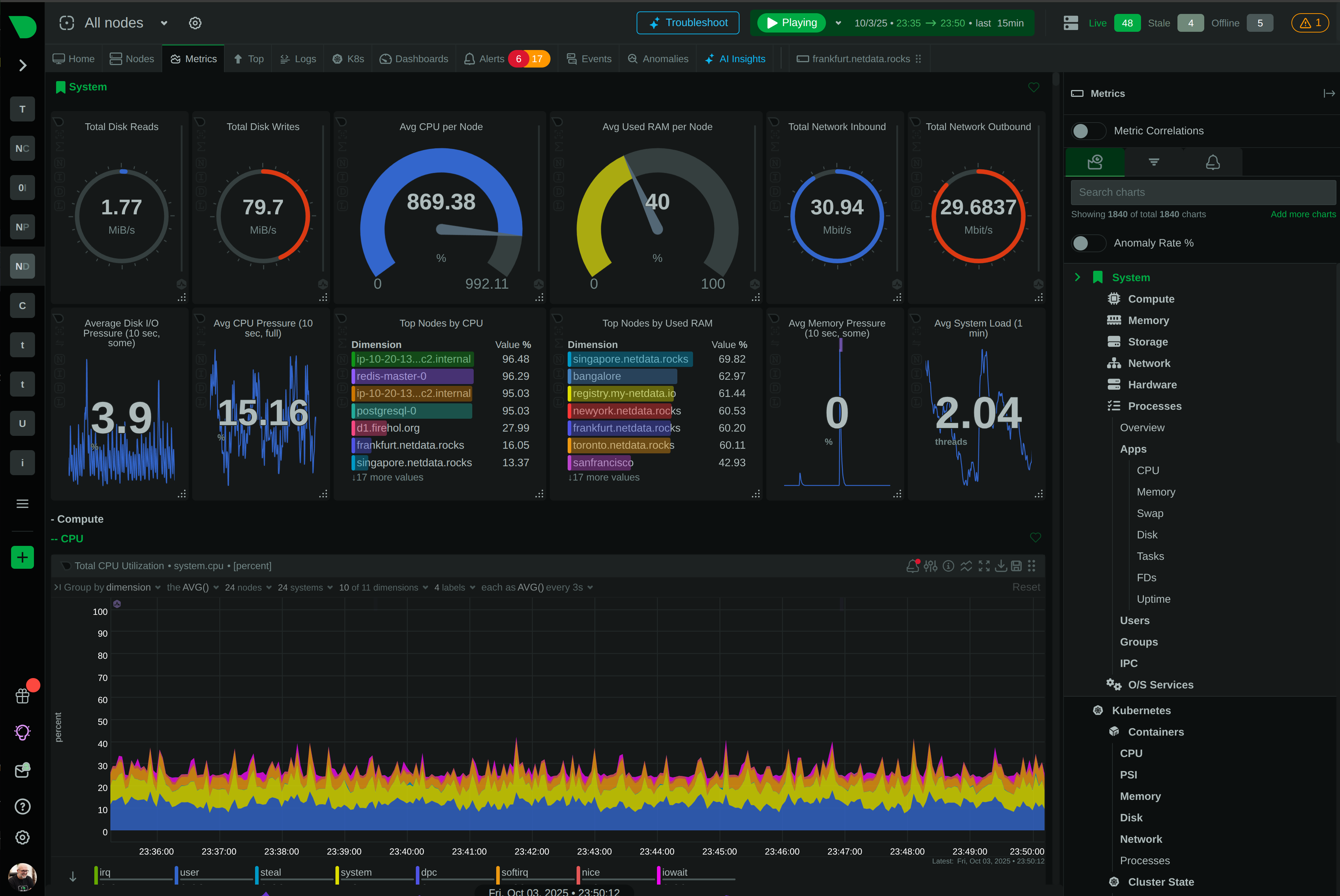
Monitor AI training clusters, inference APIs, and ML workloads with per-second precision. Netdata delivers real-time visibility into GPU utilization, resource bottlenecks, and infrastructure health - without the complexity or cost explosion of traditional monitoring.
From training clusters to inference APIs
Monitor NVIDIA and Intel GPUs in real-time. Catch thermal throttling, memory leaks, and utilization drops instantly - not minutes later.
Detect inference latency spikes, training stalls, and resource exhaustion before they cascade. 80% faster MTTR than traditional monitoring.
Predictable per-node pricing with no metric cardinality charges. Monitor unlimited GPUs, containers, and custom metrics without surprise bills.
18 unsupervised models per metric train automatically. 99% false positive reduction - surface anomalies that matter.
One-line install, zero configuration. Auto-discover GPUs, containers, and Kubernetes workloads. Dashboards and alerts active immediately.
Monitor pods, containers, nodes, and autoscaling in real-time. Track ephemeral training jobs without losing visibility.
Trusted by AI teams worldwide
10-60× faster than traditional monitoring
Explore GPU Monitoring
80% MTTR reduction
Learn About Alerting
Zero configuration required
View Kubernetes Integration
Predictable per-node pricing
Compare Pricing
Why AI Teams Choose Netdata
Traditional monitoring tools were designed for web applications, then retrofitted for AI workloads. Netdata was built from the ground up for infrastructure observability - delivering superior performance, simplicity, and cost efficiency.
Capability
Netdata
Traditional Monitoring
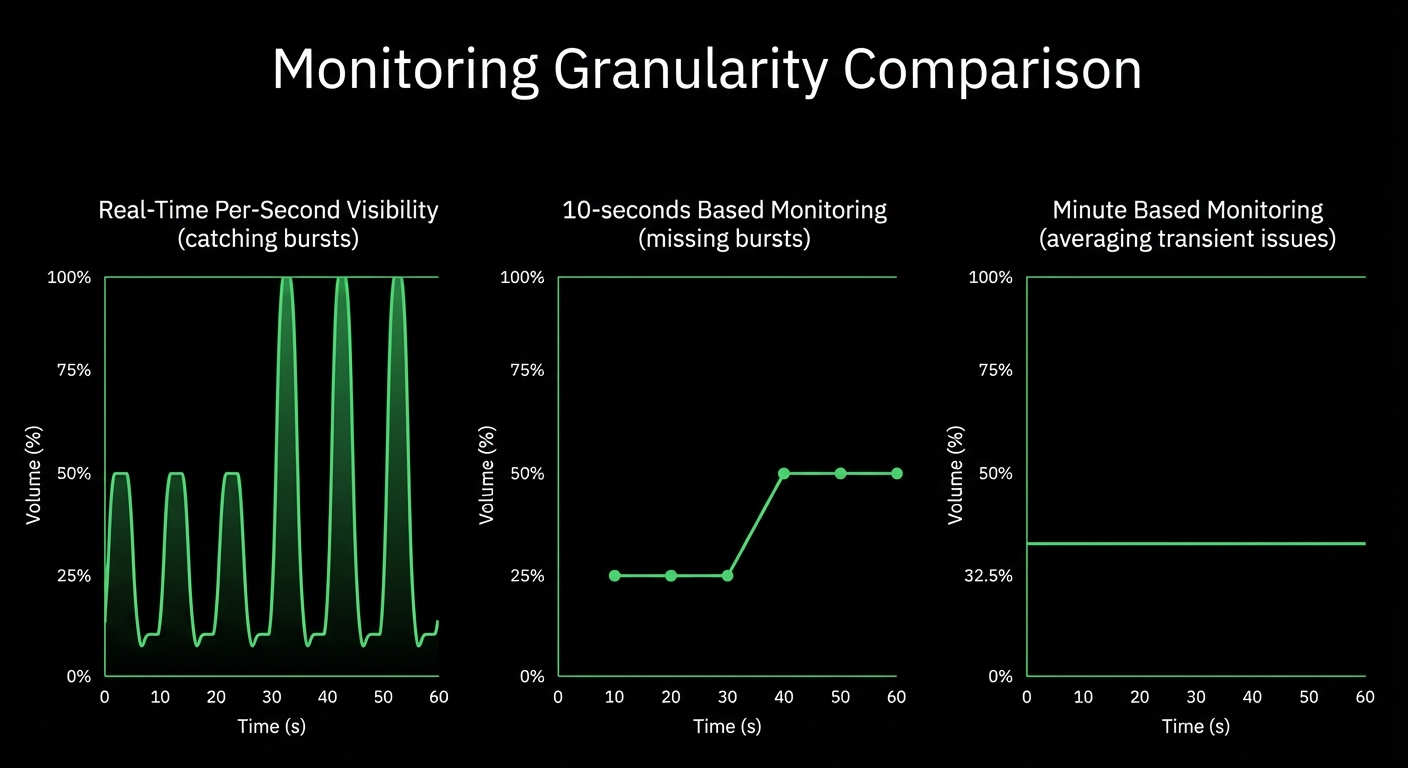
Data Granularity
✅ Per-Second
Catch 2-10 second transient issues
⚠️ Per-Minute
Miss 90% of incidents
Alert Latency
✅ Sub-2-Seconds
Real-time incident detection
⚠️ 30-90 Seconds
Delayed response
GPU Monitoring
✅ Native Support
NVIDIA, Intel auto-discovered
⚠️ Manual Setup
Requires exporters
ML Anomaly Detection
✅ Built-In
18 models per metric, 99% FP reduction
⚠️ Optional Add-On
Requires configuration
Deployment Time
✅ 60 Seconds
One-line install, zero config
❌ Days to Weeks
Complex setup
Pricing Model
✅ Per-Node
Predictable, no volume charges
❌ Volume-Based
Unpredictable, exponential scaling
Anomaly False Positives
✅ <1%
ML consensus reduces noise
⚠️ High
Manual tuning required
Query Languages
✅ None Required
Point-and-click analysis
❌ PromQL/SQL
Steep learning curve
Data Sovereignty
✅ On-Premises
Metrics stay local
⚠️ Cloud-Only
Vendor-controlled
Kubernetes Support
✅ Native
Helm chart, auto-discovery
⚠️ Manual
Requires configuration
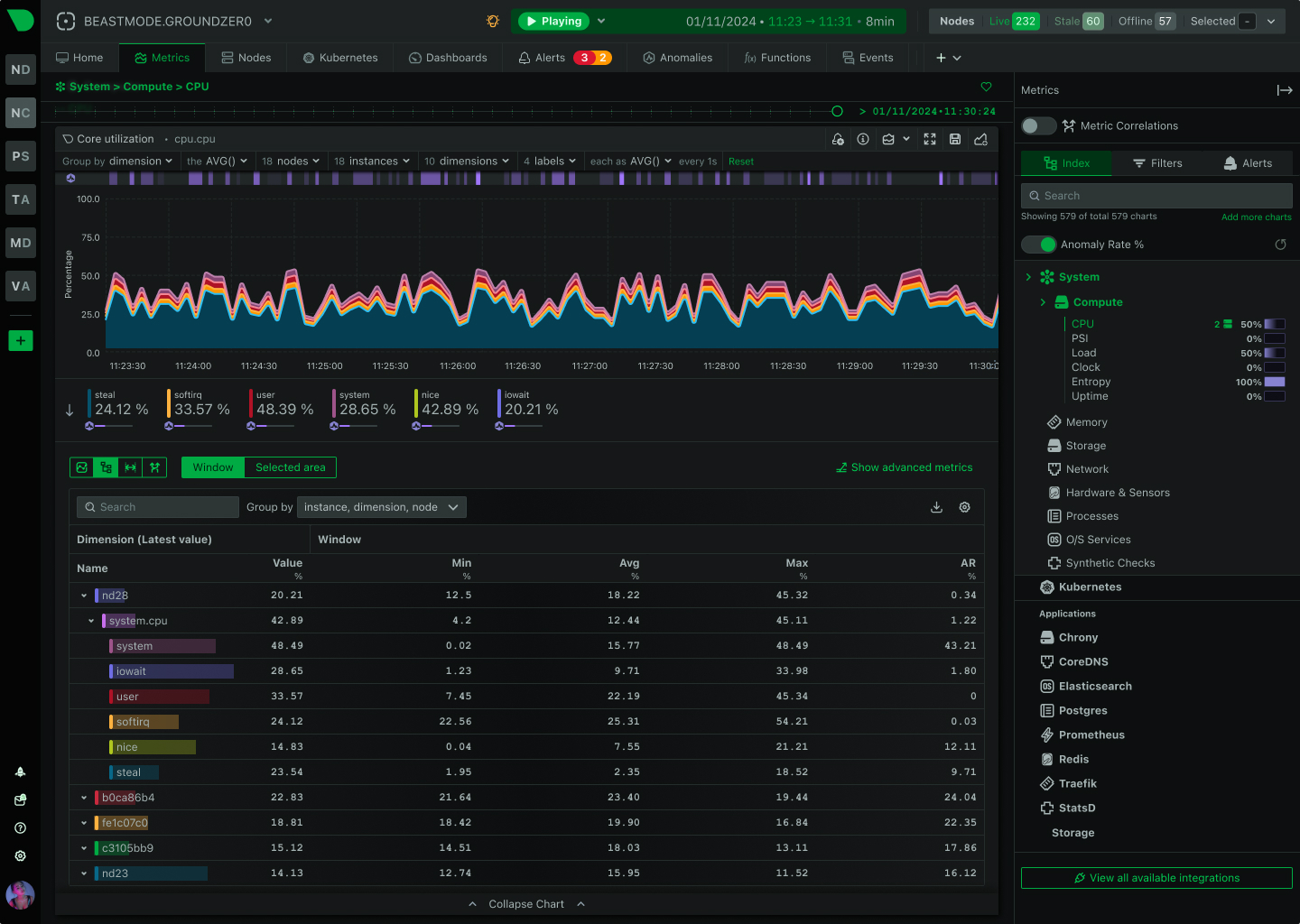
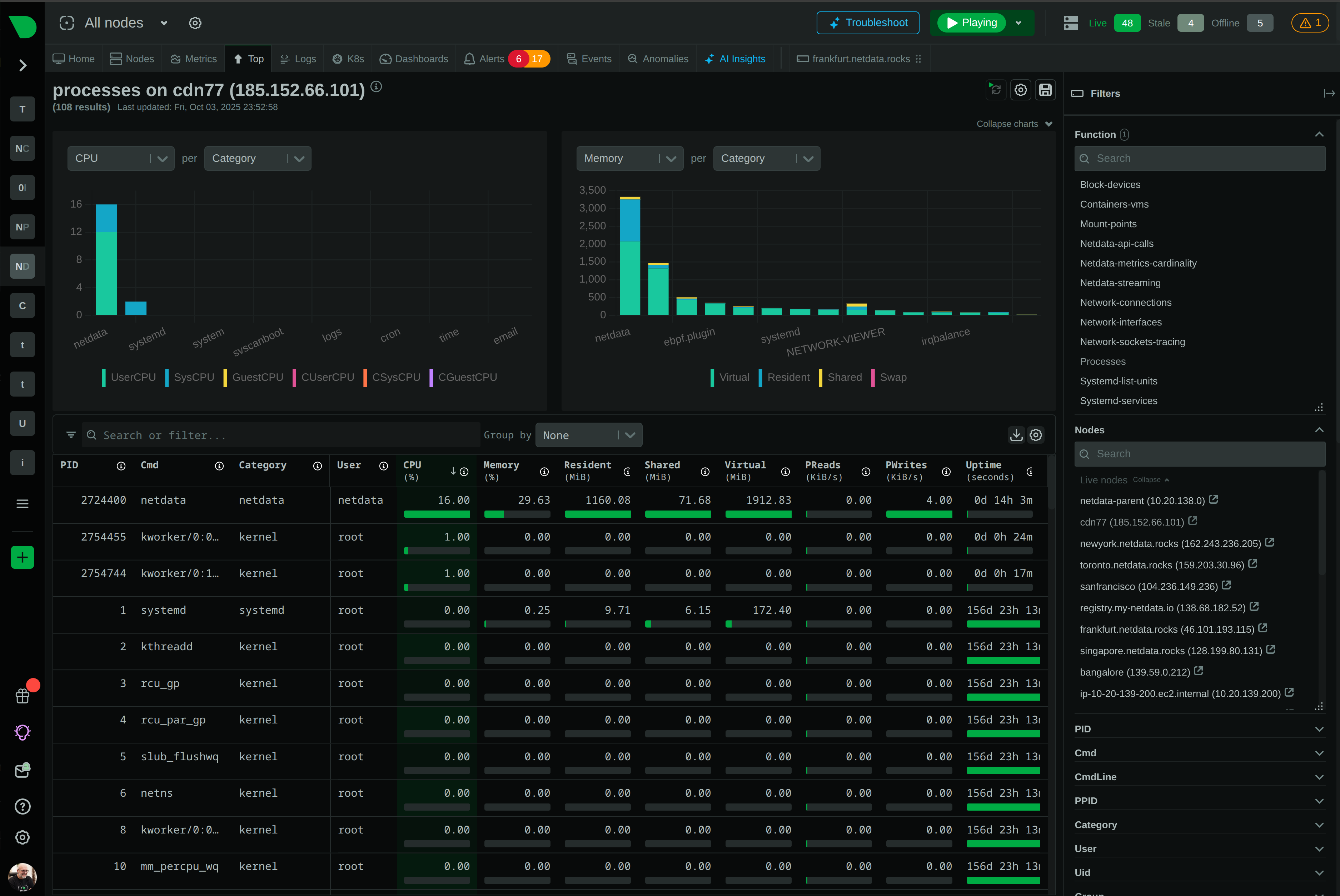
Monitor 100+ GPUs in real-time with per-second granularity. Catch thermal throttling, memory leaks, and utilization drops before they impact training runs.
Native NVIDIA & Intel GPU support
Explore GPU MonitoringTrack P50/P95/P99 latency with automated alerting on SLO breaches. Monitor GPU utilization, request rates, and error rates in real-time.
80% faster MTTR
Learn About AlertingMonitor pods, containers, nodes, and autoscaling with zero configuration. Track ephemeral training jobs from creation to completion.
Helm chart deployment
View Kubernetes GuidePer-second feedback on resource utilization during model development. Catch memory leaks, GPU underutilization, and data loading bottlenecks instantly.
Zero learning curve
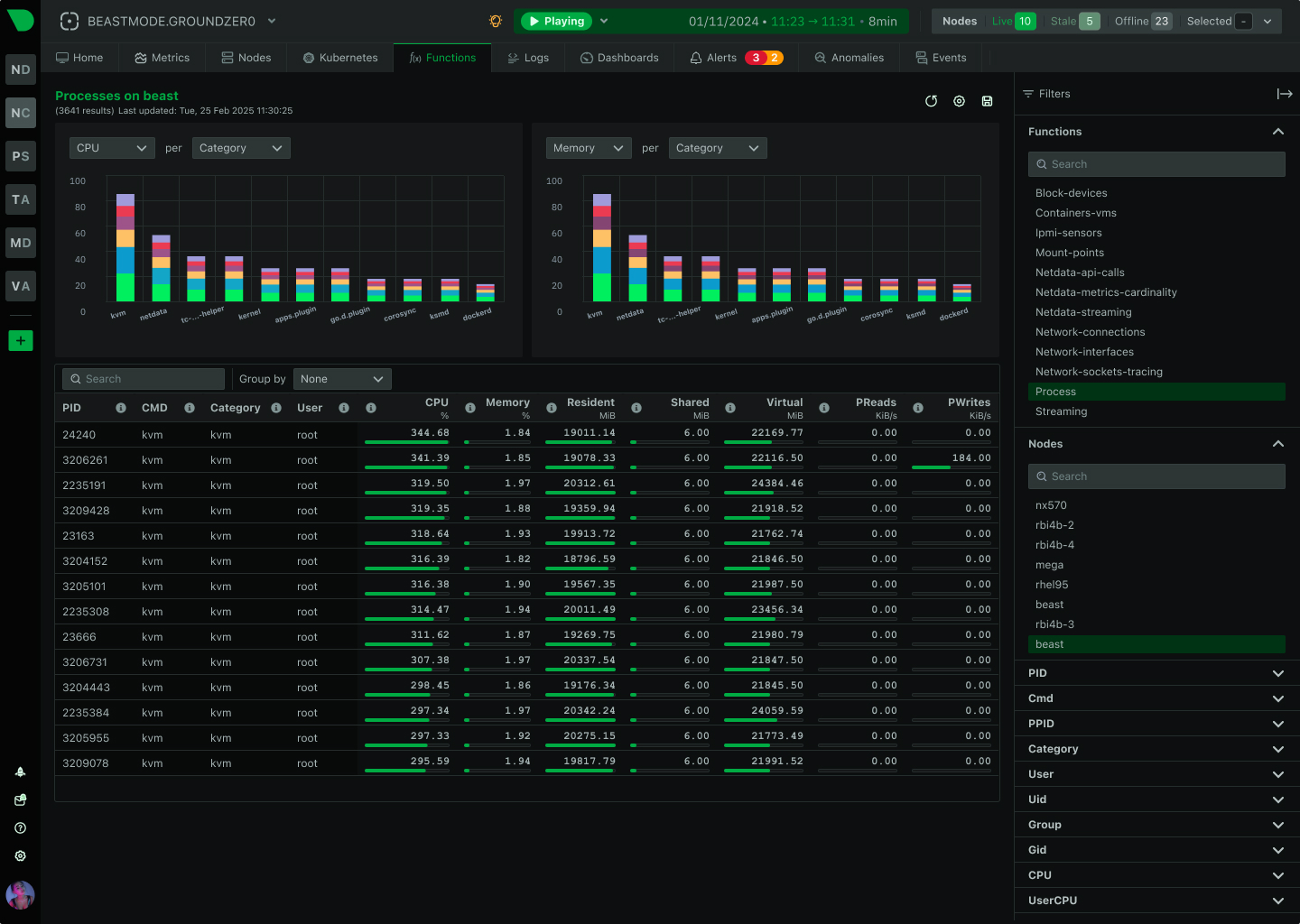
See Live DemoBrowser-based diagnostics replace SSH access. Monitor processes, network connections, and logs with history and ML context.
Console replacement
Explore FunctionsBuilt for infrastructure observability, proven at scale
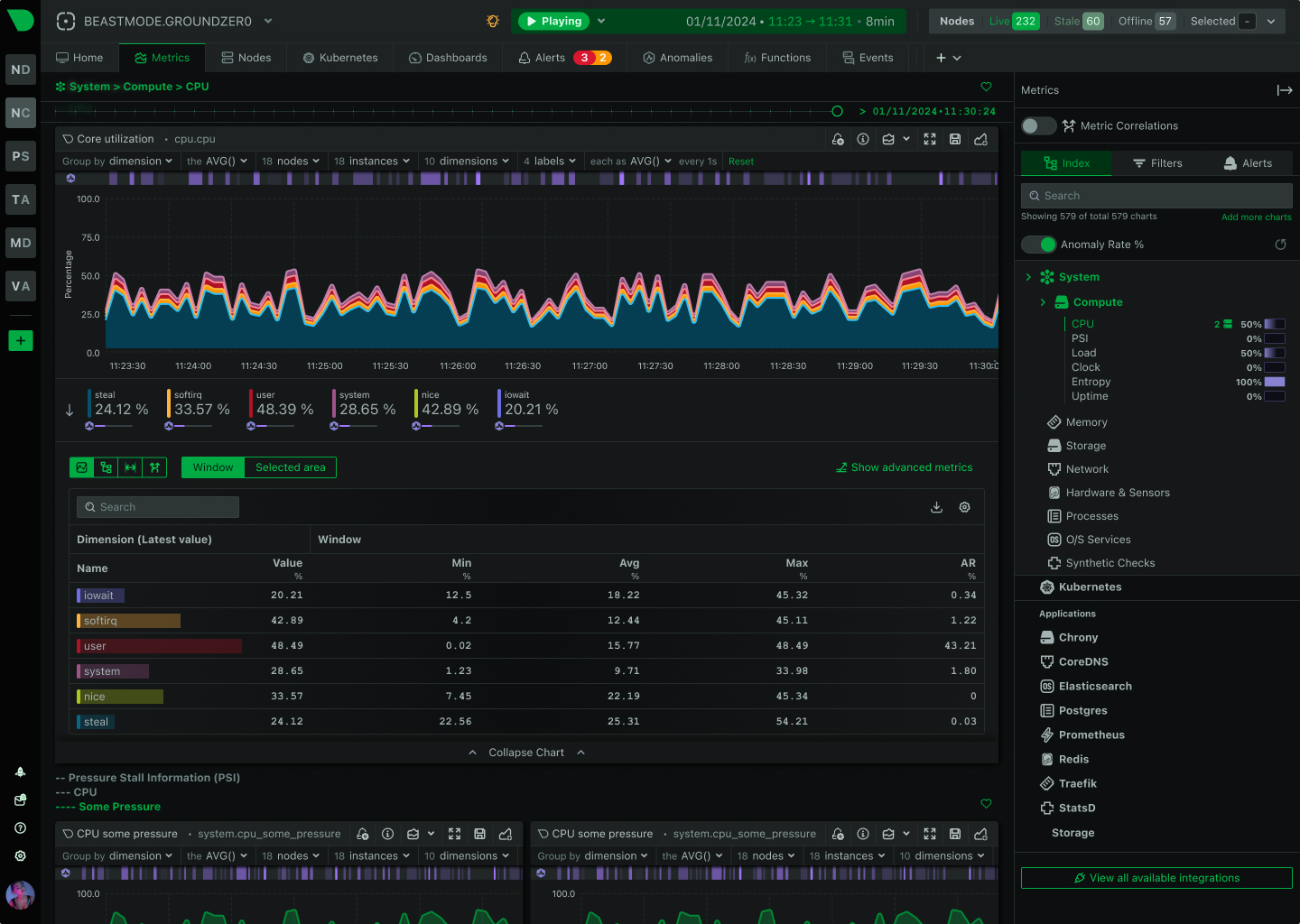
Per-second data collection with sub-2-second latency. Catch transient issues invisible to minute-averaged tools.
18 unsupervised models per metric train automatically. 99% false positive reduction - surface anomalies that matter.
One-line install, zero configuration. Auto-discover GPUs, containers, Kubernetes. Dashboards active in 60 seconds.
Per-node pricing with P90 billing. No metric cardinality charges. 90% lower TCO than volume-based platforms.
Metrics and logs stay on-premises. SOC 2 Type 2 certified. GDPR, HIPAA, PCI DSS compliant.
No query languages required. Point-and-click analysis. Universal interface across all infrastructure.
May 4, 2026
Netdata's new DCGM collector provides comprehensive real-time monitoring for NVIDIA data center GPUs with hundreds of metrics across GPU, MIG, NVLink, NVSwitch, and CPU scopes, plus built-in alerts, anomaly detection, and AI troubleshooting.
February 27, 2026
Connect AI coding agents like Claude Code, Codex, and Cursor to your entire infrastructure with a single endpoint. The Netdata Cloud MCP Server brings infrastructure-wide observability to any MCP-compatible AI tool.
June 18, 2025
Revolutionize how you interact with your monitoring data!
Netdata excels at infrastructure monitoring (GPUs, APIs, Kubernetes) but requires manual instrumentation for LLM-specific metrics like token tracking and cost attribution. Send token counts via StatsD or OpenTelemetry, and Netdata will provide dashboards and alerts. For native LLM observability, consider complementing Netdata with tools like LangSmith or Langfuse.
Netdata provides superior infrastructure monitoring (10-60× faster granularity, 90% lower cost) but lacks native LLM observability features like hallucination detection. Best approach: Use Netdata for GPU clusters, inference APIs, and Kubernetes (saving 90% on infrastructure monitoring), then complement with LLM-specific tools for application-layer observability.
Yes. Netdata’s nvidia_smi collector provides per-second monitoring of GPU utilization, memory, temperature, power draw, PCIe bandwidth, and MIG instances. Auto-discovered with zero configuration. Also supports Intel GPUs via intelgpu collector. TPU monitoring requires external exporters.
Yes. Netdata’s Helm chart provides native Kubernetes integration with auto-discovery of pods, containers, nodes, and services. Monitor ephemeral training jobs, autoscaling triggers, and resource utilization in real-time. Unified view across infrastructure, applications, and logs without tool sprawl.
Netdata trains 18 unsupervised k-means models per metric using different time windows. Anomalies are flagged only when ALL 18 models agree, achieving 99% false positive reduction (theoretical rate: 10^-36). Models retrain every 3 hours automatically, adapting to changing baselines without configuration.
60 seconds from install to production-ready monitoring. One-line command installs the agent, auto-discovers GPUs and services, generates dashboards, activates 400+ pre-configured alerts, and begins ML training. No query languages, no manual dashboard building, no threshold tuning required.
Predictable per-node pricing with P90 billing that excludes daily spikes and top 3 days per month. No charges for metric cardinality, log volume, or users. Monitor unlimited GPUs, containers, and custom metrics. 90% lower TCO than volume-based platforms. View detailed pricing.
For infrastructure monitoring: Yes. Netdata provides metrics, logs, alerts, ML, and AI troubleshooting in one platform. For LLM application observability: Partial. Netdata excels at infrastructure (GPUs, APIs, Kubernetes) but requires manual instrumentation for LLM-specific features (token tracking, hallucination detection). Best approach: Netdata for infrastructure + complementary LLM tool for application layer.
Not yet. Distributed tracing is planned for Q2 2026. Currently, Netdata ingests OpenTelemetry metrics and logs (production-ready) but not traces. For APM-style tracing today, use complementary tools like Jaeger or Tempo, then export Netdata metrics to Grafana for unified visualization.
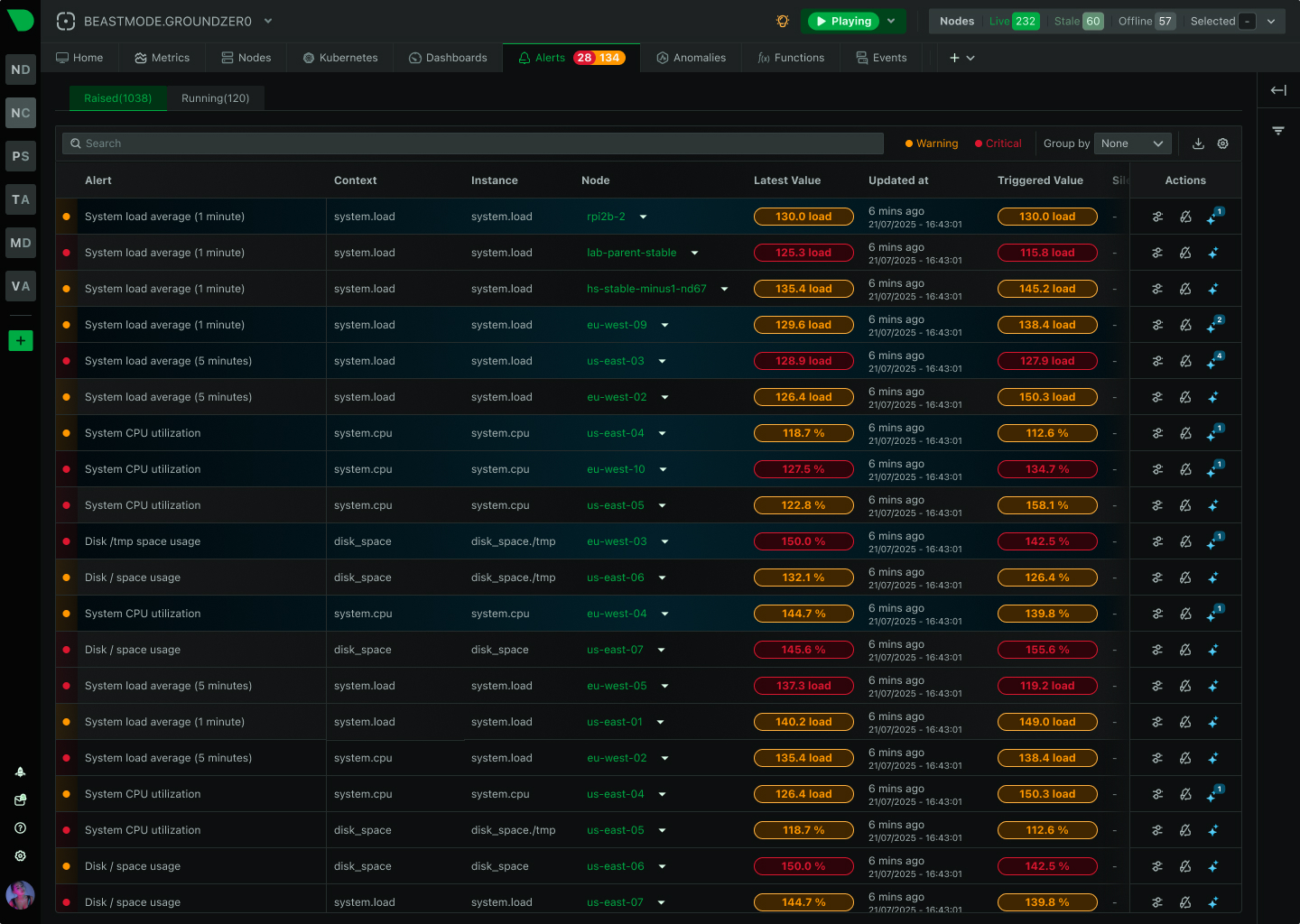
Netdata reduces alert noise through component-level alerts that are more accurate and actionable than generic threshold-based alerts. Additional features include hysteresis protection, configurable notification delays, and role-based routing. Cloud-level deduplication eliminates redundant alerts across multiple agents. Note that ML-based anomaly detection is a separate observability signal and does not filter or influence alert notifications.
Yes. Netdata supports fully on-premises deployment with no internet connectivity required. Metrics and logs stay local, ML trains at the edge, and dashboards are served directly from agents. Enterprise On-Prem option provides full Netdata Cloud features (unified dashboards, RBAC, SSO) within your datacenter. SOC 2 Type 2 certified, GDPR/HIPAA/PCI DSS compliant.
Agents are lightweight collectors installed on every node (GPUs, servers, containers). Parents are centralization points that aggregate data from multiple agents, providing unified dashboards and longer retention. For AI workloads: Install agents on all GPU nodes, set up Parents for centralized view. Agents can offload ML training and storage to Parents, reducing production system load.
Yes. Use Netdata’s httpcheck collector for endpoint monitoring, or instrument your API with StatsD timers. Netdata auto-calculates P50/P95/P99 percentiles and provides real-time alerting on SLO breaches. Correlate API latency with GPU utilization, memory pressure, and network bandwidth for instant root cause analysis.
Netdata benchmark at 4.6M metrics/s shows 36% less CPU, 88% less RAM, 97% less disk I/O, and 16× faster queries than Prometheus. Key differences: (1) Per-second vs per-minute granularity, (2) Zero configuration vs manual setup, (3) Built-in ML vs none, (4) Algorithmic dashboards vs manual building, (5) Predictable per-node pricing vs infrastructure costs. Read detailed comparison.
Yes. Netdata monitors AWS, Azure, GCP, and on-premises infrastructure with unified dashboards. Deploy agents across all environments, set up Parents per region/cloud, and access everything through Netdata Cloud. Track cross-cloud training jobs, inference APIs, and resource utilization without tool sprawl. Data sovereignty maintained - metrics stay in each cloud.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}