 |
VOOZH | about |
|
VOOZH | about |
Git pack objects are used to efficiently store and compress repository data by combining multiple objects into a single file. This helps reduce storage space and improve performance.
The importance of pack objects in Git for enabling efficient storage, faster data transfer, and optimized repository management.
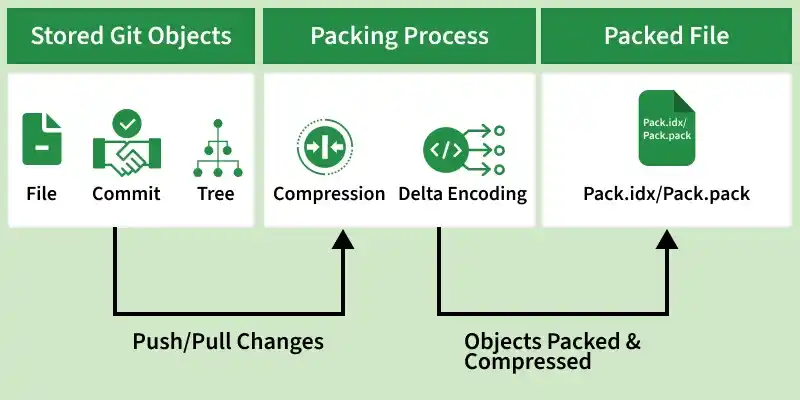
Git stores data as objects such as files, commits, and branches. These objects are initially stored individually in the .git/objects directory.
When you perform operations like push or pull, Git automatically creates or updates pack files. This process, known as packing, combines objects efficiently using compression, reducing repository size and improving performance.
Large files can slow down Git operations. The following methods help manage them effectively:
Remove Large Files
Remove Unnecessary Commits
Clone Specific Commits (Shallow Clone)
git clone --depth 1Run Garbage Collection
git gc --prune=nowIn some cases, Git pack files may become corrupted due to issues like incomplete transfers or disk errors. The following methods can be used to detect and recover from such corruption:
git fsckChecks the repository for inconsistencies and identifies corrupted objects or pack files.
Restore Using ReflogAllows rollback to a previous valid commit state before corruption occurred.
git fetchor re-clone using:
git clonegit fetch or git clone retrieves a clean copy of objects from the remote repository.
The size of Git pack objects depends on several factors:
Git pack archives allow packaging repository objects into a compressed, portable format for easy sharing and transfer between systems.
{kind=link}
{kind=link}