The Apriori algorithm is used in data mining to find items that often appear together in transaction data, like shopping baskets. It looks for frequent item groups and builds larger groups from smaller ones that are already common. By doing this, it helps discover useful patterns, such as products that are often bought together.
Apriori Property:
All non-empty subsets of a frequent itemset must be frequent. Apriori assumes that all subsets of a frequent itemset must be frequent (Apriori property). If an itemset is infrequent, all its supersets will be infrequent.
ImportantTerminologies
Support: Support is an indication of how frequently the itemset appears in the dataset. It is the count of records containing an item ‘x’ divided by the total number of records in the database.
Confidence: Confidence is a measure of times such that if an item ‘x’ is bought, then item ‘y’ is also bought together. It is the support count of (x U y) divided by the support count of ‘x’.
Lift: Lift is the ratio of the observed support to that which is expected if ‘x’ and ‘y’ were independent. It is the support count of (x U y) divided by the product of individual support counts of ‘x’ and ‘y’.
Algorithm
Read each item in the transaction.
Calculate the support of every item.
If support is less than minimum support, discard the item. Else, insert it into frequent itemset.
Calculate confidence for each non- empty subset.
If confidence is less than minimum confidence, discard the subset. Else, it into strong rules.
Implementation of Apriori Algorithm in R
We implement the Apriori algorithm in R using the arules package to perform Market Basket Analysis on the preloaded Groceries dataset.
1. Installing required packages
We install the arules, arulesViz, and RColorBrewer packages to use their functions for association rule mining and visualizations.
arules: Used to mine frequent itemsets and association rules using the Apriori algorithm.
arulesViz: Used to visualize association rules and itemsets.
RColorBrewer: Used to apply color palettes for better visual output.
2. Loading required libraries
We load the installed libraries to access their functions and datasets.
library(): Used to load installed packages into the R session.
3. Importing the dataset
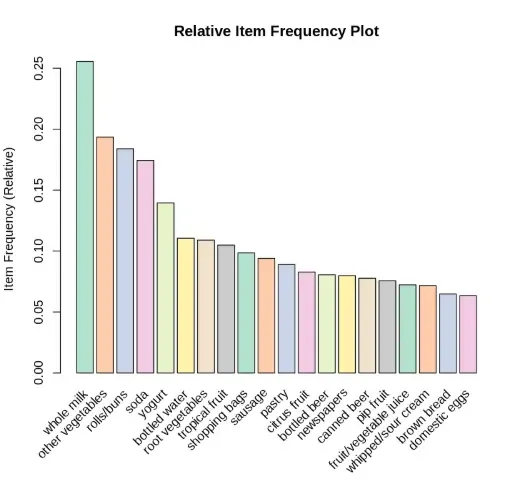
We import the Groceries dataset which contains 9835 grocery transactions.
data("Groceries"): Loads a predefined transactional dataset containing items bought together.
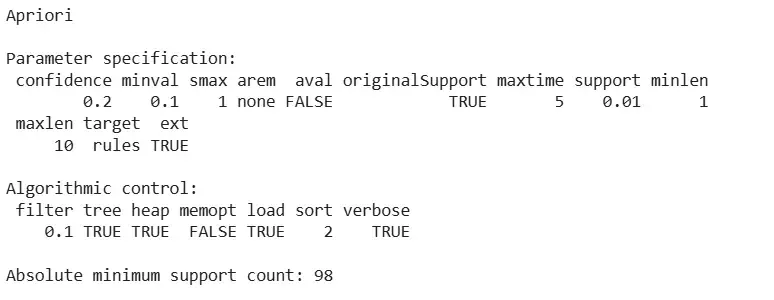
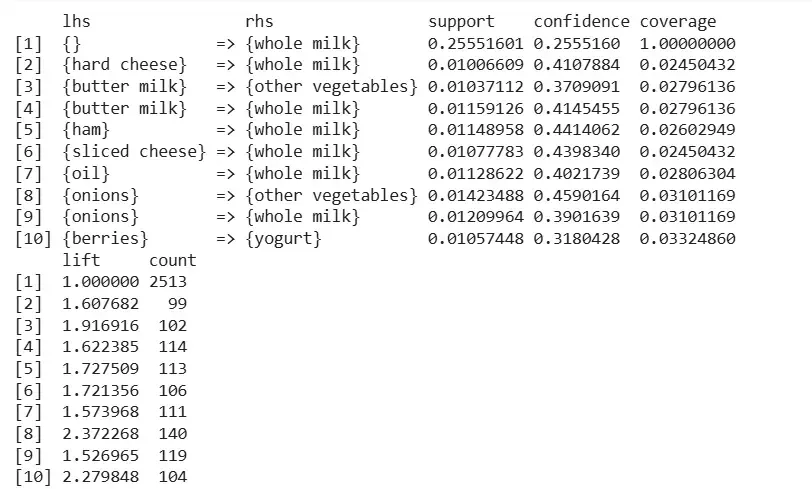
4. Applying apriori() function
We apply the apriori() function to generate strong association rules from the dataset.
apriori(): Used to generate association rules based on support and confidence.
parameter = list(supp = 0.01, conf = 0.2): Defines minimum support of 1% and confidence of 20%.

{kind=link}
{kind=link}
{kind=link}
{kind=link}