 |
VOOZH | about |
|
VOOZH | about |
Clustering is an unsupervised machine learning technique that is used to identify similarities and patterns within data points by grouping similar points based on their features. These points can belong to different clusters simultaneously. Fuzzy clustering is a clustering technique where each data point can belong to multiple clusters with varying degrees of membership. In normal clustering, each data point goes into only one group, while in fuzzy clustering, a point can be shared between groups to different degrees.
In real-world scenarios, data points may naturally belong to more than one cluster. Fuzzy clustering addresses this by allowing data points to belong to multiple clusters at the same time. Its key advantages over normal clustering include:
Factor | Normal Clustering | Fuzzy Clustering |
Partitioning | Hard Partitioning, data points can belong to only one cluster. | Soft Partitioning, data points can belong to multiple clusters. |
Membership | Data points can either belong to one cluster or none at all. | Data points can belong to multiple clusters simultaneously. |
Representation | represented by centroids. | represented by centroids with degrees of membership. |
Suitable dataset | Dataset with distinct boundaries. | Dataset with overlapping observations. |
Algorithm used | K-means, Hierarchical clustering. | Fuzzy C -means, Gustafson-Kessel algorithm. |
Implementation | Easier to implement since the dataset is not complex. | Difficult to Implement since dataset has overlapping observations. |
In this example we will apply fuzzy clustering on a Sample sales dataset.
You can download the dataset from here.
We are installing and loading the libraries that provide necessary functions for clustering and visualization.
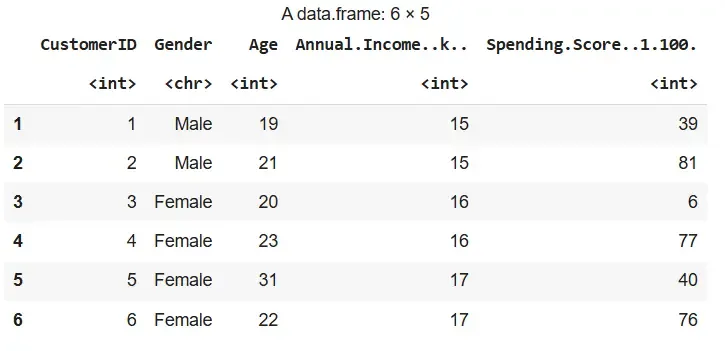
We are reading the CSV file containing the data and inspecting the first few rows.
Output:
We are cleaning the dataset to ensure accuracy in clustering.
Output:
We are choosing relevant features that influence clustering: Age, Income and Spending Score.
We are performing fuzzy clustering using the cmeans() function from e1071.
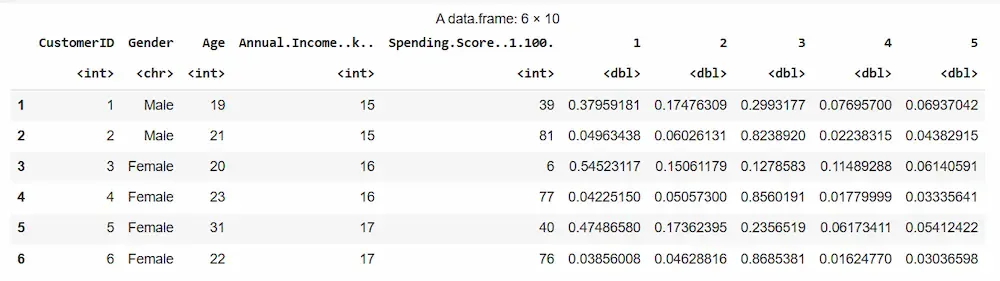
We are combining the fuzzy membership matrix with the original dataset for analysis.
Output:
The quality of a cluster refers to how well-separated and distinct the clusters are from each other and how cohesive the data points within each cluster are. A high-quality cluster should have tightly grouped points and be well-separated from other clusters. We will evaluate the quality of the formed clusters using the following approach:
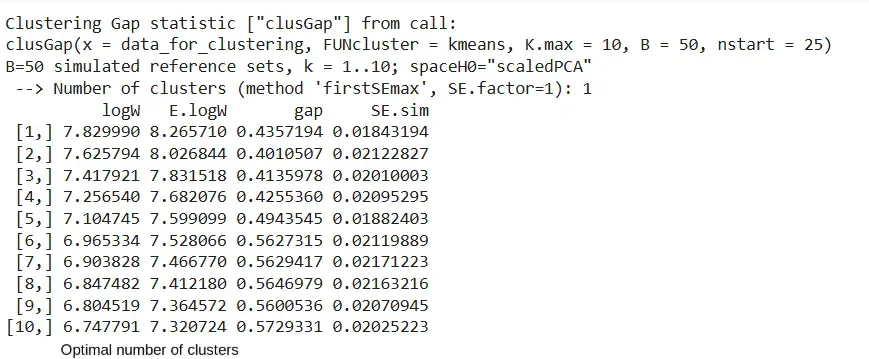
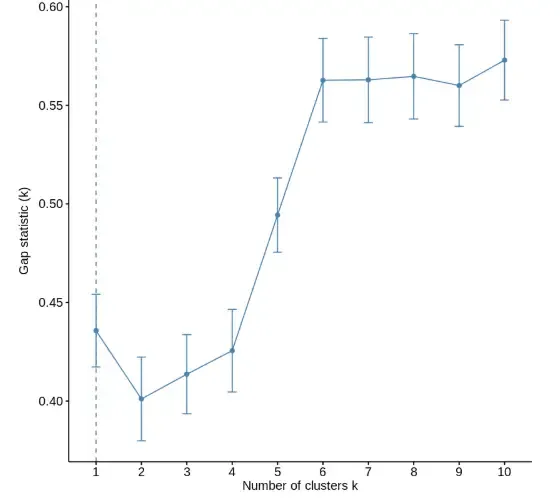
We are computing the gap statistic to determine the optimal number of clusters by comparing the model’s performance with random uniform distribution.
Output:
We are calculating the Davies-Bouldin Index to measure intra-cluster similarity and inter-cluster separation.
Output:
[1] 0.884653
We are computing the Calinski-Harabasz (CH) Index to evaluate the ratio of between-cluster dispersion to within-cluster dispersion.
Output:
[1] 151.0439
We will visualize the clustering results to better understand the distribution and separation of the formed clusters.
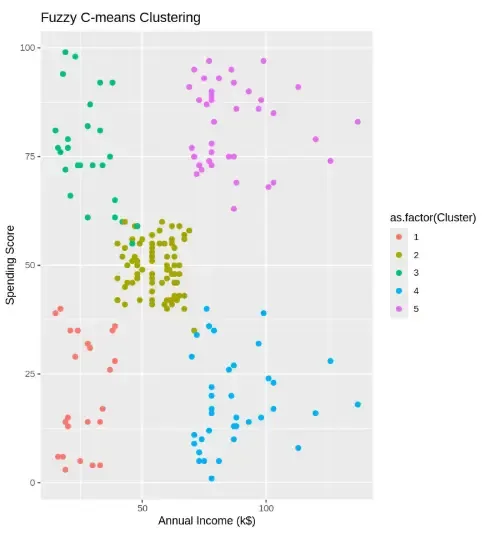
We are plotting customer data colored by their fuzzy cluster assignment for easy interpretation.
Output:
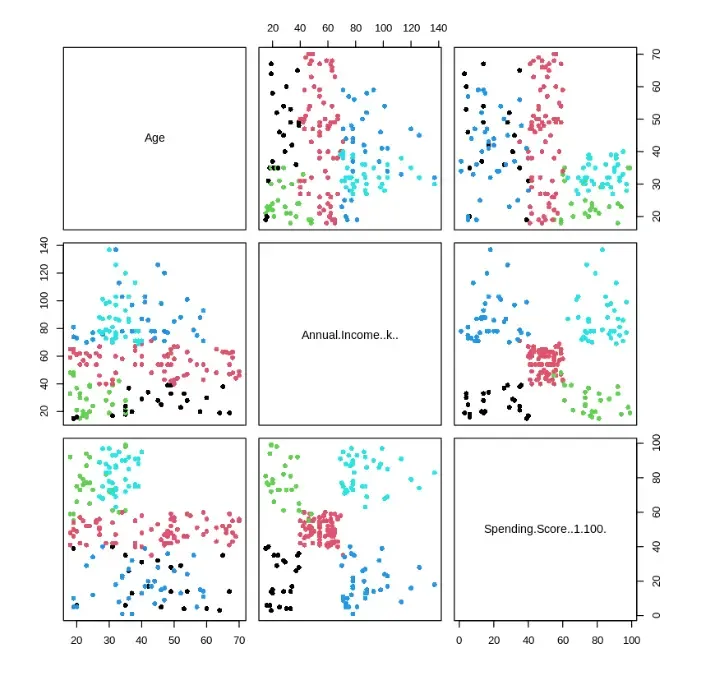
We are creating pairwise scatter plots to study the relationship between clustering variables.
Output:
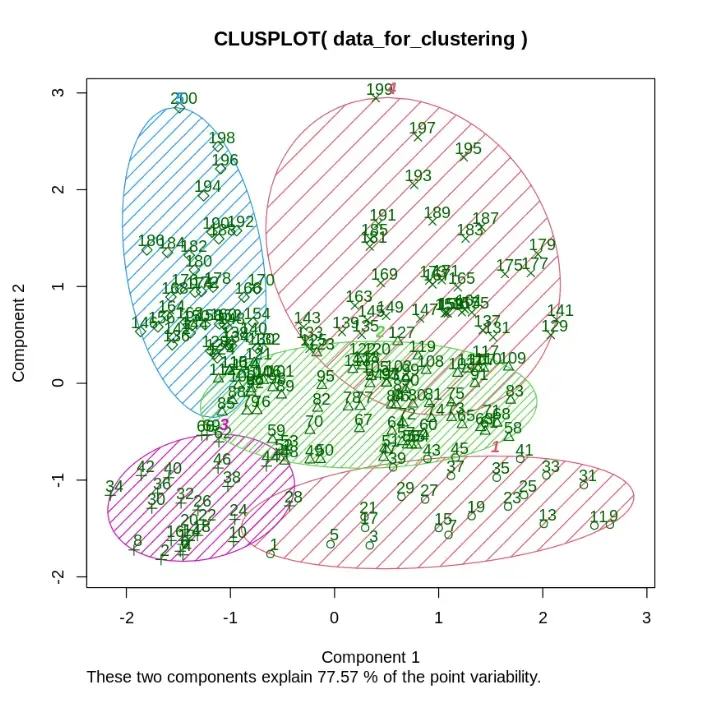
We are visualizing clusters in 2D space using dimensionality reduction.
Output:
This plot shows how the data points are grouped into clear clusters in 2D, capturing about 77.57% of the original data’s information.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}