 |
VOOZH | about |
|
VOOZH | about |
The Tidyverse is a collection of R packages designed specifically for data science. These packages share a consistent philosophy, grammar and design structure, making data manipulation, visualization and analysis more intuitive and efficient. Instead of learning many unrelated functions, the Tidyverse provides a unified and readable approach to working with data in R.
The Tidyverse consists of eight core packages that are automatically loaded when you install and load the tidyverse package.
| Category | Packages |
|---|---|
| Data Visualization | ggplot2 |
| Data Wrangling | dplyr, tidyr |
| Data Import | readr |
| Data Structures | tibble |
| String Handling | stringr |
| Categorical Data | forcats |
| Functional Programming | purrr |
In addition to these, there are specialized packages such as:
These are not loaded automatically.
ggplot2 is a data visualization package based on the Grammar of Graphics.
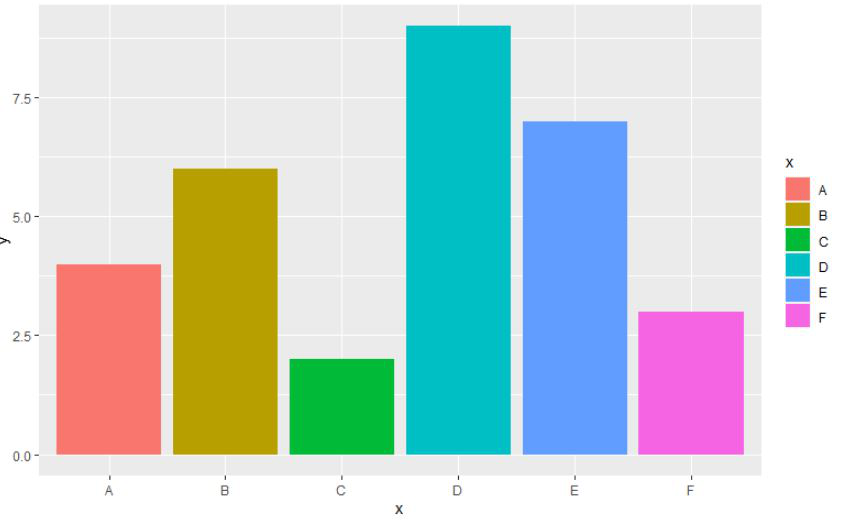
Example: We will be using 6 different data points for the bar plot and then with the help of the fill argument within the aes function.
Output:
dplyr is a data manipulation library in R. It has five important functions that are combined naturally with the group_by() function that can help in performing these functions in groups. These functions include:
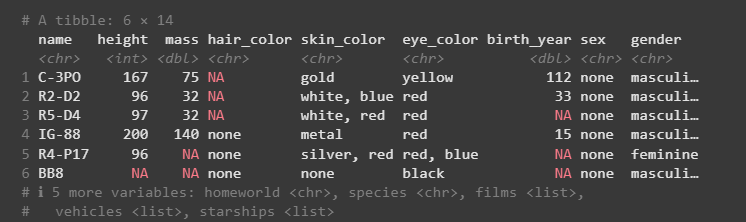
Example: We are using the dplyr package to filter the starwars dataset, selecting only the rows where the species is "Droid" and displaying the result with print().
Output:
tidyr helps clean and organize messy data into tidy format.
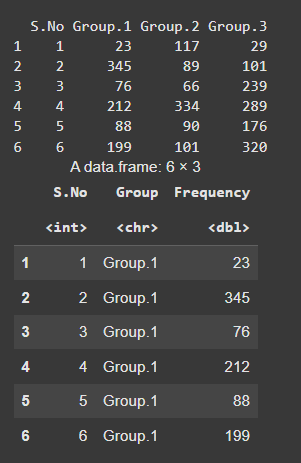
Example: The gather() function in tidyr will take multiple columns and collapse them into key-value pairs, duplicating all other columns as needed.
Output:
stringr simplifies string manipulation.
Example: We are using the stringr package to calculate the length of the string "GeeksforGeeks" with the str_length() function, which returns the number of characters in the string.
Output:
13
forcats is an R library designed to handle issues related to factors or categorical variables which are vectors that can only take a predefined set of values. It helps manage tasks like reordering these vectors or adjusting the order of their levels. Some useful functions in forcats includes:
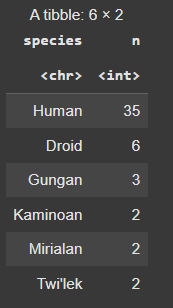
Example: Below is a example of forcats library.
Output:
readr is used for fast and simple data import.
Example: We are using the readr package to read a tab-separated file ("geeksforgeeks.txt") without column names using the read_tsv() function. The data is stored in the variable myData.
Output:
A computer science portal for geeks.
We are using the readr package to read a tab-separated file ("geeksforgeeks.txt"). Ensure that the file exists in the current working directory before running the code.
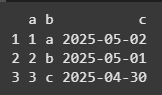
tibble is a modern version of a data frame.
Example: We are using the tibble package to create a data frame named data with three columns: a, b and c. The column a contains numbers from 1 to 3, b contains the first three letters of the alphabet and c contains dates from the previous 3 days.
Output:
Purrr supports functional programming in R.
Example: We are using purrr to split the mtcars dataset by the cyl column, apply a linear regression model to each subset, extract the summary and then return the R-squared values for each group.
Output:
1.2
2.4
3.6
You can Download the complete source code from here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}