 |
VOOZH | about |
|
VOOZH | about |
MongoDB models relationships between data using embedded documents, references (normalized model), and the $lookupaggregation stage, allowing you to balance performance, structure, and query flexibility based on application needs.
These techniques provide flexibility in handling various data relationships, optimizing both storage and access patterns.
In the Embedded Document Model, related data is stored within a single MongoDB document, allowing associated information (e.g., student and address) to be retrieved in one query for faster access.
Using embedded documents, a one-to-one relationship can be modeled by storing related data (e.g., a student’s address) inside the parent document. This reduces the number of read operations and enables single-query retrieval.
Before Embedding (Separate Documents)
/// Student document
{
"StudentName": "GeeksA",
"StudentId": "g_f_g_1209",
"Branch": "CSE"
}
// Address document
{
"StudentName": "GeeksA",
"PermanentAddress": "XXXXXXX",
"City": "Delhi",
"PinCode": 202333
}
Problem with Separate Documents
When address data is frequently accessed, querying separate collections using the same key (e.g., StudentName) requires multiple queries, increasing complexity and read overhead.
After Embedding (Single Document)
{
"StudentName": "GeeksA",
"StudentId": "g_f_g_1209",
"Branch": "CSE",
"Address": {
"PermanentAddress": "XXXXXXX",
"City": "Delhi",
"PinCode": 202333
}
}
Advantages
Limitations
Subset Pattern (When Documents Grow Large)
If only a subset of fields is frequently accessed, move large or infrequently used data into separate collections (subset pattern) to keep the main document lightweight.
Trade-off of Subset Pattern
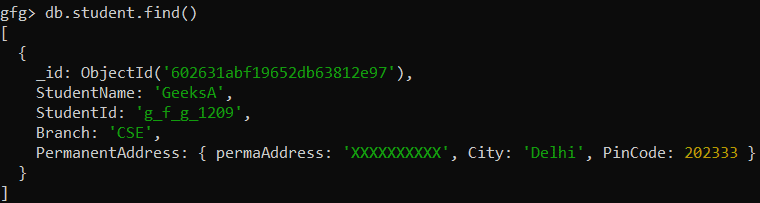
Example: Display the address of the student
Here, we are working with:
Database: gfg
Collection: student
Documents: One document that contains the details of a student
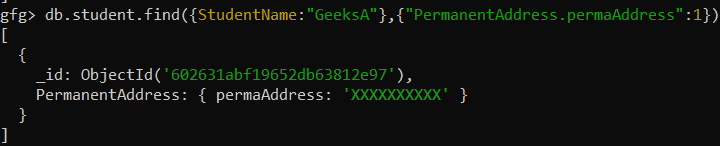
Query:
db.student.find({StudentName:"GeeksA"},{"PermanentAddress.permaAddress":1})Output:
A one-to-many relationship can be modeled using embedded documents when multiple related items (e.g., multiple addresses) belong to a single parent document. This enables efficient single-query retrieval and reduces read operations.
Before Embedding (Separate Documents)
// Student document
{
"StudentName": "GeeksA",
"StudentId": "g_f_g_1209",
"Branch": "CSE"
}
// Permanent Address document
{
"StudentName": "GeeksA",
"AddressType": "Permanent",
"Address": "XXXXXXX",
"City": "Delhi",
"PinCode": 202333
}
// Current Address document
{
"StudentName": "GeeksA",
"AddressType": "Current",
"Address": "XXXXXXX",
"City": "Mumbai",
"PinCode": 334509
}
After Embedding (Single Document with Array of Addresses)
{
"StudentName": "GeeksA",
"StudentId": "g_f_g_1209",
"Branch": "CSE",
"Addresses": [
{
"Type": "Permanent",
"Address": "XXXXXXX",
"City": "Delhi",
"PinCode": 202333
},
{
"Type": "Current",
"Address": "XXXXXXX",
"City": "Mumbai",
"PinCode": 334509
}
]
}
Advantages
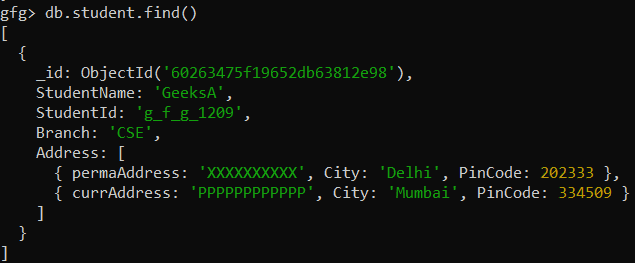
Example: Display all the addresses of the student
Here, we are working with:
Database: gfg
Collection: student
Documents: One document that contains the details of a student
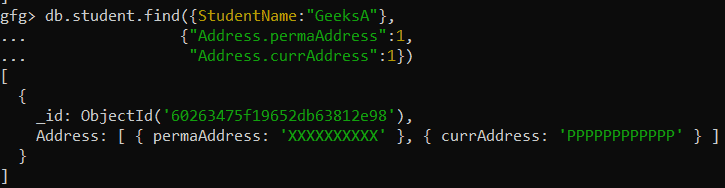
Query:
db.student.find({StudentName:"GeeksA"},
{"Address.permaAddress":1,
"Address.currAddress":1})
Output:
Note:
- Store multiple related items as a bounded array within the parent document.
- Use embedding when related data is frequently accessed together.
In the Normalized (Reference) Data Model, related data is stored in separate collections and linked using references (IDs), enabling normalized relationships and independent access to each entity.
In the reference model, related data is stored in separate collections, and the parent document maintains references (IDs) to multiple child documents. This is suitable for one-to-many relationships where related entities (e.g., classes) are accessed independently or can grow over time.
Before Referencing (Separate Documents)
// Teacher document
{
"name": "Sam",
"TeacherId": "g_f_g_1209"
}
// Class 1 document
{
"TeacherId": "g_f_g_1209",
"ClassId": "C_123",
"ClassName": "GeeksA",
"StudentCount": 23,
"Subject": "Science"
}
// Class 2 document
{
"TeacherId": "g_f_g_1209",
"ClassId": "C_234",
"ClassName": "GeeksB",
"StudentCount": 33,
"Subject": "Maths"
}
Problem
Retrieving all classes taught by a teacher requires multiple queries across collections, increasing query complexity.
After Referencing (Using IDs in Parent Document)
// Teacher document
{
"name": "Sam",
"TeacherId": "g_f_g_1209",
"ClassIds": ["C_123", "C_234"]
}
Now using these classIds field teacher can easily retrieve the data of class 1 and 2.
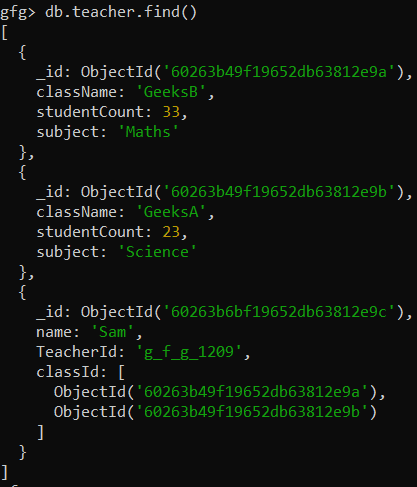
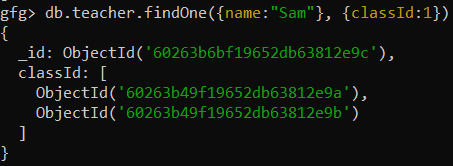
Example: Display the values of classId field
Here, we are working with:
Database: gfg
Collection: teacher
Documents: Three document that contains the details of the classes
Query:
db.teacher.findOne({name:"Sam"}, {classId:1})Output:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}