The $substrCP operator in MongoDB extracts substrings based on Unicode code points within the aggregation pipeline, ensuring correct handling of both ASCII and non-ASCII characters for multilingual text processing.
Extracts substrings using Unicode code point index and length.
Handles multibyte and non-ASCII characters correctly.
Designed for use in aggregation stages (e.g., $project, $addFields).
Avoids byte-level slicing issues seen with byte-based substring methods.
Suitable for multilingual and special-character text manipulation.
Syntax
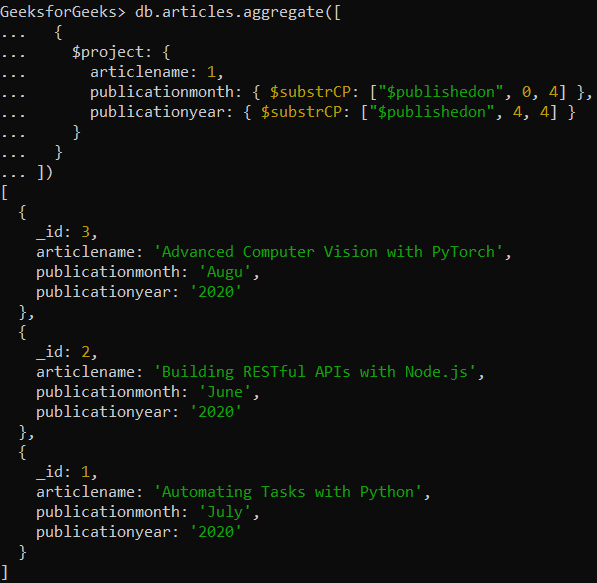
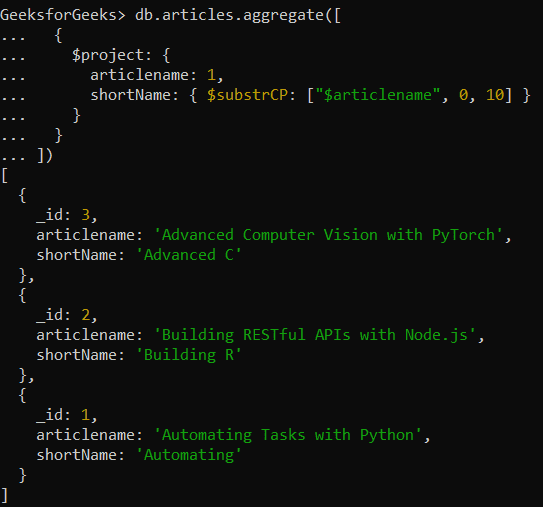
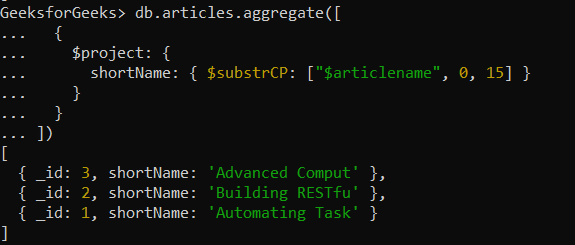
{ $substrCP: [ <string expression>, <code point index>, <code point count> ] }
string expression: Accepts strings with alphabetic, alphanumeric, and special characters as input for substring extraction.
code point index: It is a non-negative integer that represents the starting point of the substring
code point count: Non-negative integer specifying the number of characters that need to be taken from the code point index.
Importance of $substrCP
Here are some importance discussed below:
Works seamlessly with non-ASCII characters (e.g., Chinese, Arabic, emojis, etc.).
Uses Unicode code points instead of byte positions, ensuring accuracy.
Supports multibyte character sets effectively.
Enhances data processing in multilingual applications.
Helps extract portions of text fields for analysis, filtering, and transformations.
Examples of MongoDB $substrCP Operator
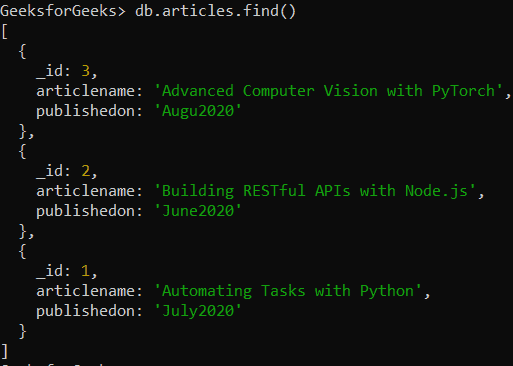
To understand MongoDB $substrCP Operator we need a collection on which we will perform various operations and queries.
Database: GeeksforGeeks
Collection: articles
Documents: Three documents that contain the details of the articles in the form of field-value pairs.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}